
Grafana Alerting 入门 - 第 3 部分
Grafana Alerting 入门 - 第 3 部分
Grafana Alerting 入门教程第 3 部分是 Grafana Alerting 入门教程第 2 部分的延续。
Grafana Alerting 中的分组功能通过将相关的警报实例合并成一个简洁的通知来减少通知噪音。这对于待命工程师非常有用,可以确保他们专注于解决事件,而不是被海量通知淹没。
分组是通过通知策略中的标签配置的。这些标签引用由警报实例生成或由用户配置的标签。
通知策略还允许您定义针对每组警报实例发送通知的频率。
在本教程中,您将:
- 了解警报规则分组的工作原理。
- 创建一个通知策略来处理分组。
- 为实际场景定义警报规则。
- 接收和查看分组的警报通知。
开始之前
您可以通过不同的方式学习本教程。
Grafana Cloud
- 作为 Grafana Cloud 用户,您无需安装任何东西。创建您的免费账户。
继续阅读警报规则分组的工作原理。
交互式学习环境
- 或者,您可以在我们的交互式学习环境中尝试此示例:Grafana Alerting 入门 - 第 3 部分。这是一个已完全配置好的环境,所有依赖项都已安装。
Grafana OSS
如果您选择在本地运行 Grafana Stack,请确保已安装以下应用程序:
Docker Compose(包含在 macOS 和 Windows 版 Docker Desktop 中)
设置 Grafana Stack(OSS 用户)
为了演示使用 Grafana Stack 进行数据观测,请下载并运行以下文件。
克隆教程环境仓库。
git clone https://github.com/grafana/tutorial-environment.git更改到您克隆仓库的目录
cd tutorial-environment运行 Grafana Stack
docker compose up -d首次运行
docker compose up -d时,Docker 会下载教程所需的所有资源。这可能需要几分钟,具体取决于您的互联网连接速度。注意
如果您的系统上已经运行了 Grafana、Loki 或 Prometheus,可能会看到错误,因为 Docker 镜像尝试使用的端口已被本地安装占用。在这种情况下,请停止这些服务,然后再次运行命令。
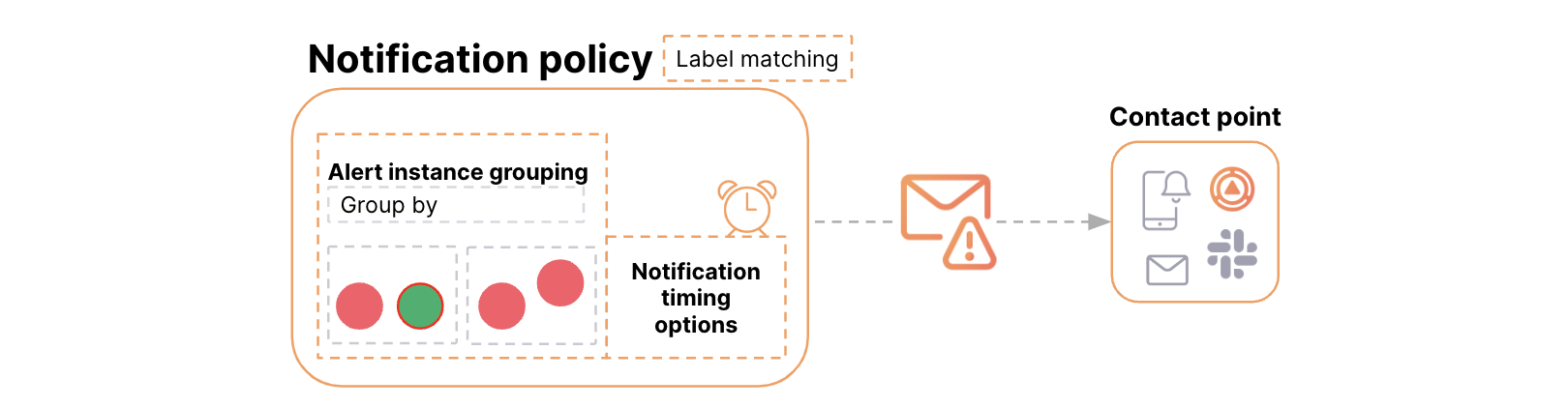
警报规则分组的工作原理
警报通知分组通过标签和定时选项进行配置。
- 标签将警报规则映射到通知策略并定义分组。
- 定时选项控制通知发送的时间和频率。
标签类型
保留标签(默认)
- 由 Grafana 自动生成,例如
alertname,grafana_folder。 - 示例:
alertname="High CPU usage"。
用户配置的标签:
- 手动添加到警报规则。
- 示例:
severity,priority。
查询标签:
- 由数据源查询返回。
- 示例:
region,service,environment。
定时选项
Group wait:发送第一个通知前的等待时间。Group interval:同一分组的通知发送间隔时间。Repeat interval:对于未更改的分组,重新发送通知前的等待时间。
共享相同标签值的警报将被分组在一起,并且定时选项决定了通知的频率。
更多详情,请参阅:
警报分组在实际应用中的示例
场景:监控分布式应用
您正在跨多个区域监控 CPU 使用率、内存利用率和网络延迟等指标。一些警报规则包含诸如 region: us-west 和 region: us-east 等标签。如果这些区域的多个警报规则同时触发,可能会导致通知泛滥。
如何管理分组
要对警报规则通知进行分组:
- 定义标签:使用
region、metric或instance等标签对警报进行分类。 - 配置通知策略:
- 按查询标签“region”对警报进行分组。
- 示例
region: us-west的警报通知发送给西海岸团队。region: us-east的警报通知发送给东海岸团队。
- 指定发送通知的定时选项以控制其频率。
- 示例
- Group interval 设置决定了同一警报分组的更新发送频率。默认情况下,此间隔设置为 5 分钟,但您可以根据需要自定义使其更短或更长。
- 示例
设置警报规则分组
通知策略
根据上述示例,创建了通知策略,用于将带有 region 标签的警报实例路由到特定的联系点。目标是每个区域接收一个合并通知。为了演示分组的工作原理,东海岸团队的警报通知不进行分组。关于定时,为该区域定义了特定的计划。此设置会覆盖父策略的设置,以便对特定标签(即区域)的行为进行微调。
登录 Grafana
- Grafana Cloud 用户:通过 Grafana Cloud 登录。
- OSS 用户:访问 https://:3000。
导航到通知策略
- 转到 Alerts & IRM > Alerting > Notification Policies。
添加子策略
在默认策略中,单击 + New child policy。
标签:
region运算符:
=值:
us-west此标签匹配 region 标签为 us-west 的警报规则。
选择联系点
- 选择 Webhook。
如果您还没有任何联系点,请添加一个联系点。
启用继续匹配
- 打开Continue matching subsequent sibling nodes,以便即使一个或多个标签(即 region 标签)匹配后,评估仍继续进行。
覆盖分组设置
切换Override grouping。
按:添加
region作为标签。移除任何现有标签。按将共享相同分组标签的警报合并为一个通知。例如,所有带有
region=us-west的警报将合并为一个通知,从而更容易管理并减少警报疲劳。
设置自定义定时
切换Override general timings。
Group interval:
2m。这确保了同一警报分组的后续通知将以 2 分钟的间隔发送。虽然默认是 5 分钟,但我们这里选择 2 分钟是为了方便演示提供更快的反馈。定时选项控制通知的发送频率,有助于在及时警报和最小化噪音之间取得平衡。
保存并重复
- 对
region = us-east重复上述步骤,但不覆盖分组和定时选项。使用不同的 Webhook 端点作为联系点。
![Two nested notification policies to route and group alert notifications]()
这些嵌套策略应路由 region 标签为 us-west 或 us-east 的警报实例。只有 us-west 区域的团队应接收分组警报通知。
注意
在 Grafana 中,通知策略中的每个标签必须具有唯一的键。如果您尝试添加具有不同值(us-west 和 us-east)的相同标签键(例如,region),则只有最后一个条目会被保存,而前一个条目会被丢弃。这是因为标签被存储为关联数组(map),其中每个键必须是唯一的。对于相同的标签键,请使用 regex 匹配器(例如,region=~“us-west|us-east”)。
- 对

创建警报规则
在本节中,我们将根据我们的应用监控示例配置一个警报规则。
- 导航到 Alerts & IRM > Alerting > Alert rules。
- 单击 New alert rule。
输入警报规则名称
使其简短且具有描述性,因为它会出现在您的警报通知中。例如:High CPU usage - Multi-region。
定义查询和警报条件
在本节中,我们使用 Grafana 管理的警报规则创建的默认选项。默认选项允许我们定义查询、表达式(用于处理数据 - UI 中的 WHEN 字段)以及必须满足的条件才能触发警报(在默认模式下为阈值)。
Grafana 包含一个测试数据源,用于创建模拟时间序列数据。此数据源包含在本教程的演示环境中。如果您在 Grafana Cloud 或您自己的本地 Grafana 实例中工作,可以通过连接 (Connections) 菜单添加数据源。
从下拉菜单中选择 TestData 数据源。
从场景 (Scenario) 中选择 CSV 内容 (CSV Content)。
复制以下 CSV 数据
选择 TestData 作为数据源。
将场景 (Scenario) 设置为 CSV 内容 (CSV Content)。
使用以下 CSV 数据
region,cpu-usage,service,instance us-west,35,web-server-1,server-01 us-west,81,web-server-1,server-02 us-east,79,web-server-2,server-03 us-east,52,web-server-2,server-04 us-west,45,db-server-1,server-05 us-east,77,db-server-2,server-06 us-west,82,db-server-1,server-07 us-east,93,db-server-2,server-08
返回的数据模拟了数据源返回多个时间序列,每个时间序列都会为其创建一个警报实例。
在警报条件 (Alert condition) 部分
- 保持
Last作为归约函数(WHEN)的值,并将75作为阈值。这是警报规则应触发的上限值。
- 保持
单击 Preview alert rule condition 运行查询。
它应该返回 5 个处于 Firing 状态的系列,其中两个来自 us-west 区域的触发实例,三个来自 us-east 区域。
![Preview of a query returning alert instances.]()

添加文件夹和标签
- 在文件夹 (Folder) 中,单击 + New folder 并输入名称。例如:
Multi-region alerts。此文件夹包含我们的警报规则。
设置评估行为
每个警报规则都分配到一个评估组。您可以将警报规则分配到现有评估组,或创建一个新的评估组。
- 在评估组和间隔 (Evaluation group and interval) 中,重复上述步骤创建一个新的评估组。将其命名为
Multi-region group。 - 选择一个评估间隔 (Evaluation interval)(警报评估的频率)。选择
1m。 - 将待处理期 (pending period) 设置为
0s(零秒),以便警报规则在条件满足时立即触发(这最大限度地缩短了演示等待时间)。
配置通知
选择当警报规则触发时谁应接收通知。
选择 Use notification policy。
点击 Preview routing 确保正确匹配。
![Preview of alert instance routing with the region label matcher]()
预览应该显示,来自我们数据源的 region 标签通过我们配置的标签匹配器成功匹配了我们之前创建的通知策略。
点击 Save rule and exit。

创建第二个警报规则
重复上述步骤创建第二个警报规则,该规则在内存使用率过高时发出警报。
点击 More > Duplicate 复制警报规则。
将其命名为
High Memory usage - Multi-region。使用下面的 CSV 数据模拟返回内存使用率的数据源。
region,memory-usage,service,instance us-west,42,cache-server-1,server-09 us-west,88,cache-server-1,server-10 us-east,74,api-server-1,server-11 us-east,90,api-server-1,server-12 us-west,53,analytics-server-1,server-13 us-east,81,analytics-server-2,server-14 us-west,77,analytics-server-1,server-15 us-east,94,analytics-server-2,server-16点击 Save rule and exit。
接收分组警报通知
配置好警报规则后,只要警报触发,您就应该在联系点收到警报通知。
当配置的警报规则检测到跨多个区域的 CPU 或内存使用率高于 75% 时,它将每分钟评估一次指标。如果条件持续存在,通知将被分组在一起,在发送第一个警报前有 30 秒的 Group wait。同一警报分组的后续通知将以 2 分钟的间隔发送(仅限 US-west 警报实例),从而增加分组警报通知的频率。US-east 实例的后续通知应以默认的 5 分钟间隔发送。如果条件持续存在较长时间,Repeat interval 为 4 小时确保只有在问题持续存在时才重新发送警报。
因此,我们的通知策略应该路由三个通知:一个分组通知,将来自 us-west 区域的 CPU 和内存警报实例分组,以及两个单独通知,包含来自 us-east 区域的警报实例。
分组通知示例
{
"receiver": "US-West-Alerts",
"status": "firing",
"alerts": [
{
"status": "firing",
"labels": {
"alertname": "High CPU usage - Multi-region",
"grafana_folder": "Multi-region alerts",
"instance": "server-05",
...
{
"status": "firing",
"labels": {
"alertname": "High Memory usage - Multi-region",
"grafana_folder": "Multi-region alerts",
"instance": "server-10",
},
...}us-west 联系点收到的一条通知,其中分组了 CPU 和内存警报实例的详细信息。
{
"receiver": "US-East-Alerts",
"status": "firing",
"alerts": [
{
"status": "firing",
"labels": {
"alertname": "High CPU usage - Multi-region",
"grafana_folder": "Multi-region alerts",
"instance": "server-03",
"region": "us-east",
"service": "web-server-2"
...}}}us-east 联系点收到的一条单独通知,其中包含 CPU 警报实例的详细信息。
{
"receiver": "US-East-Alerts",
"status": "firing",
"alerts": [
{
"status": "firing",
"labels": {
"alertname": "High memory usage - Multi-region",
"grafana_folder": "Multi-region memory alerts",
"instance": "server-12",
"region": "us-east"
...}}}us-east 联系点收到的一条单独通知,其中包含内存警报实例的详细信息。
结论
通过配置通知策略和使用标签(例如 *region*),您可以根据特定条件对警报通知进行分组,并将它们路由到相应的团队。进一步微调定时选项——包括 Group wait、Group interval 和 Repeat interval——可以减少噪音,并确保通知仍具有可操作性,而不会让待命工程师不堪重负。
在Grafana Alerting 第 4 部分中了解更多信息
提示
在Grafana Alerting 入门 - 第 4 部分中,您将学习如何使用模板创建自定义且简洁的通知。