
为何在 Grafana Cloud 中使用 Kubernetes 监控?
加速实现价值
使用这个即用型监控工具,可减少部署、设置和故障排除时间,只需运行几条 CLI 命令或对 Helm chart 进行少量更改即可。
更快识别根因
通过集群导航视图深入分析您的基础设施,以便识别和解决问题,无需在不同窗口和监控工具之间切换。
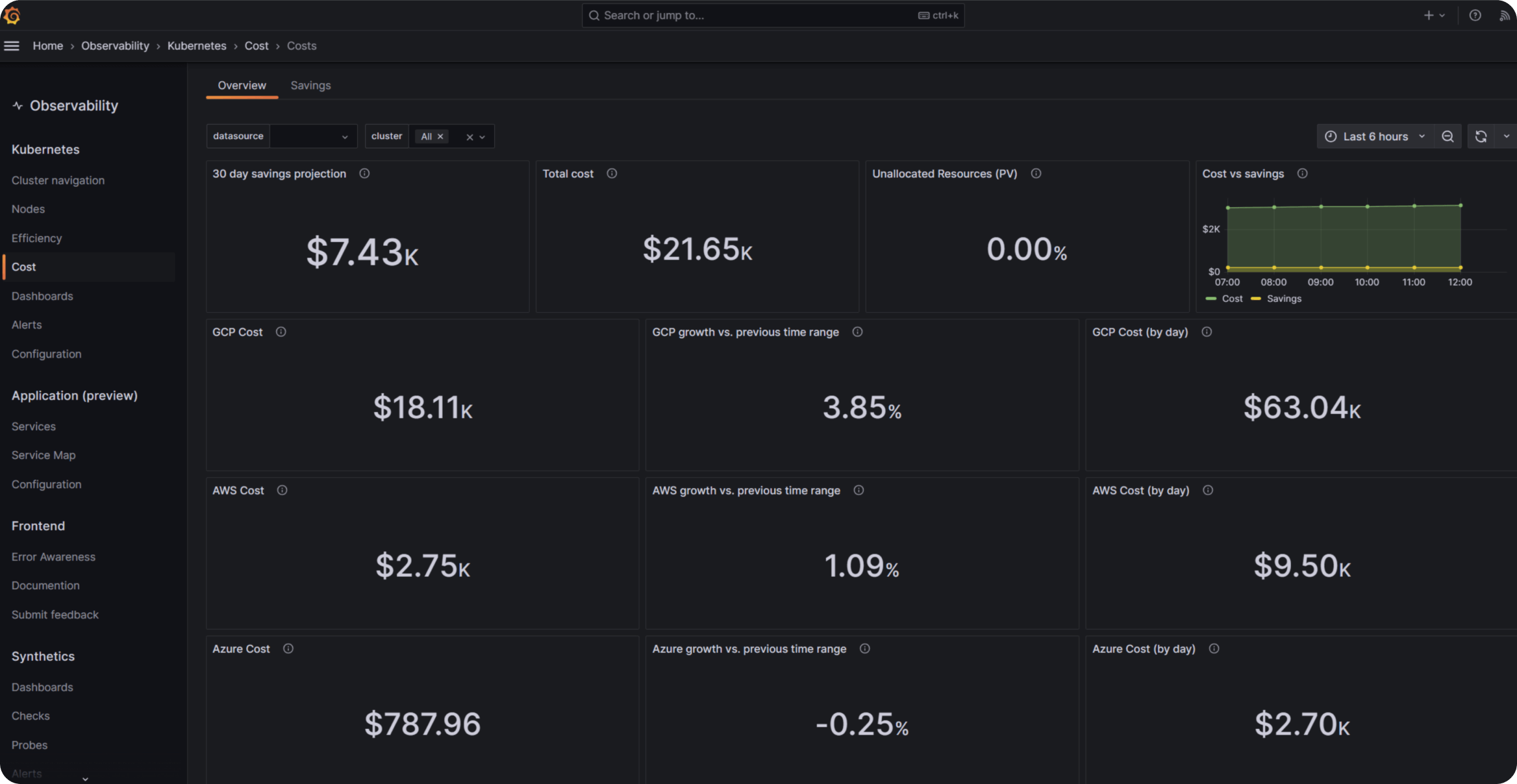
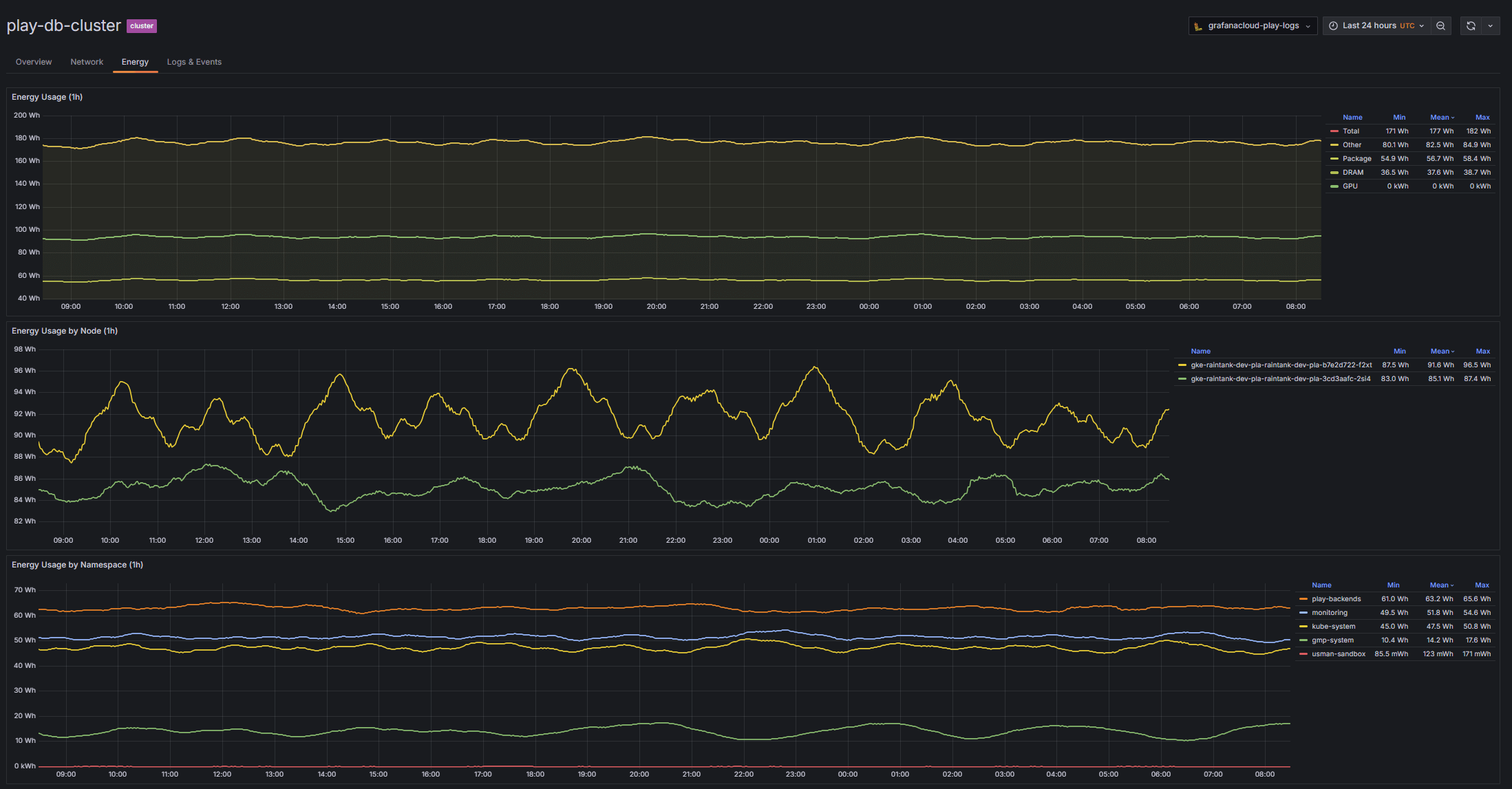
降低成本
效率和成本监控可视化可提供全面的支出洞察,支持围绕资源分配、扩展策略和技术投资做出数据驱动的决策。
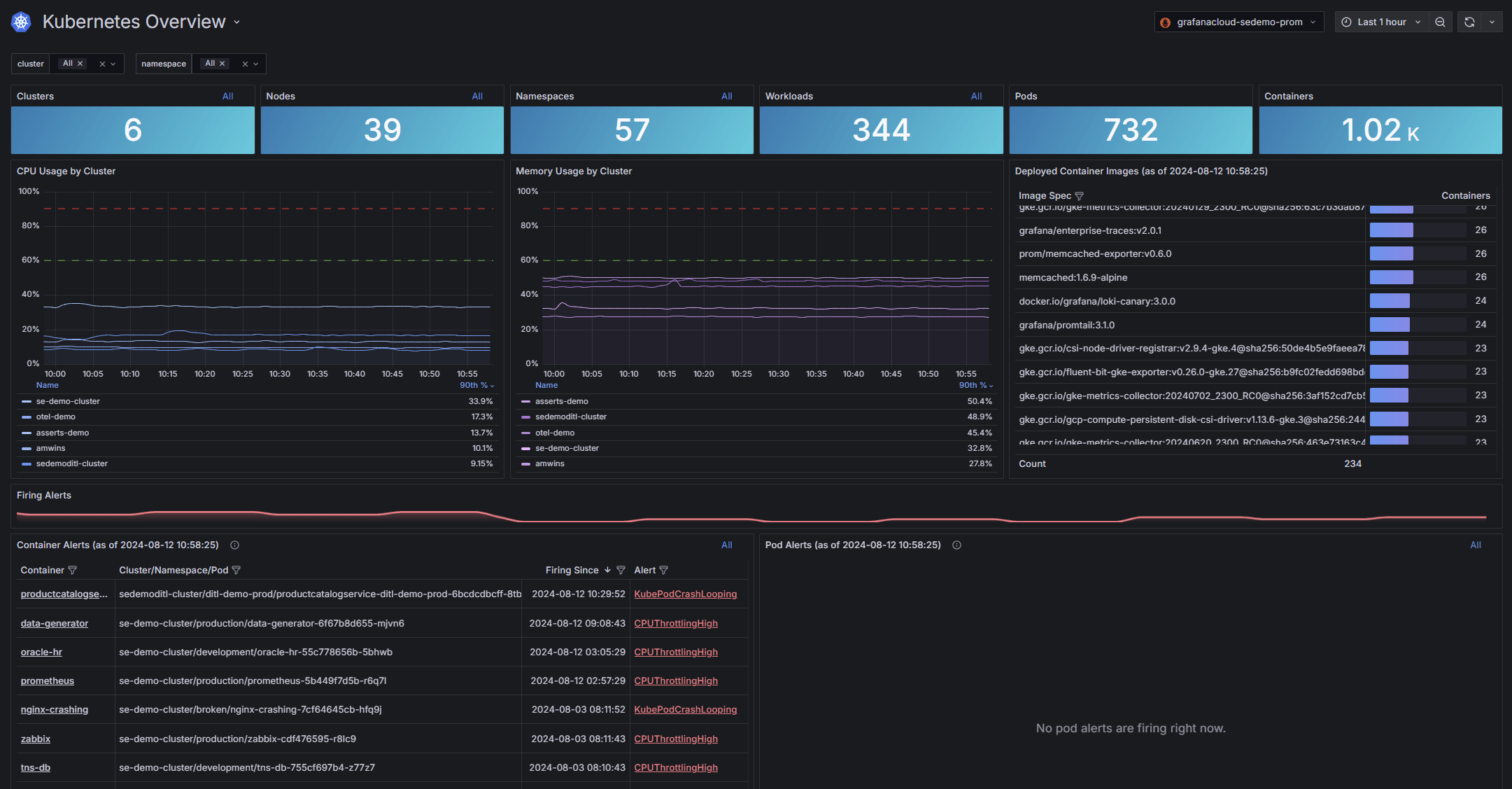
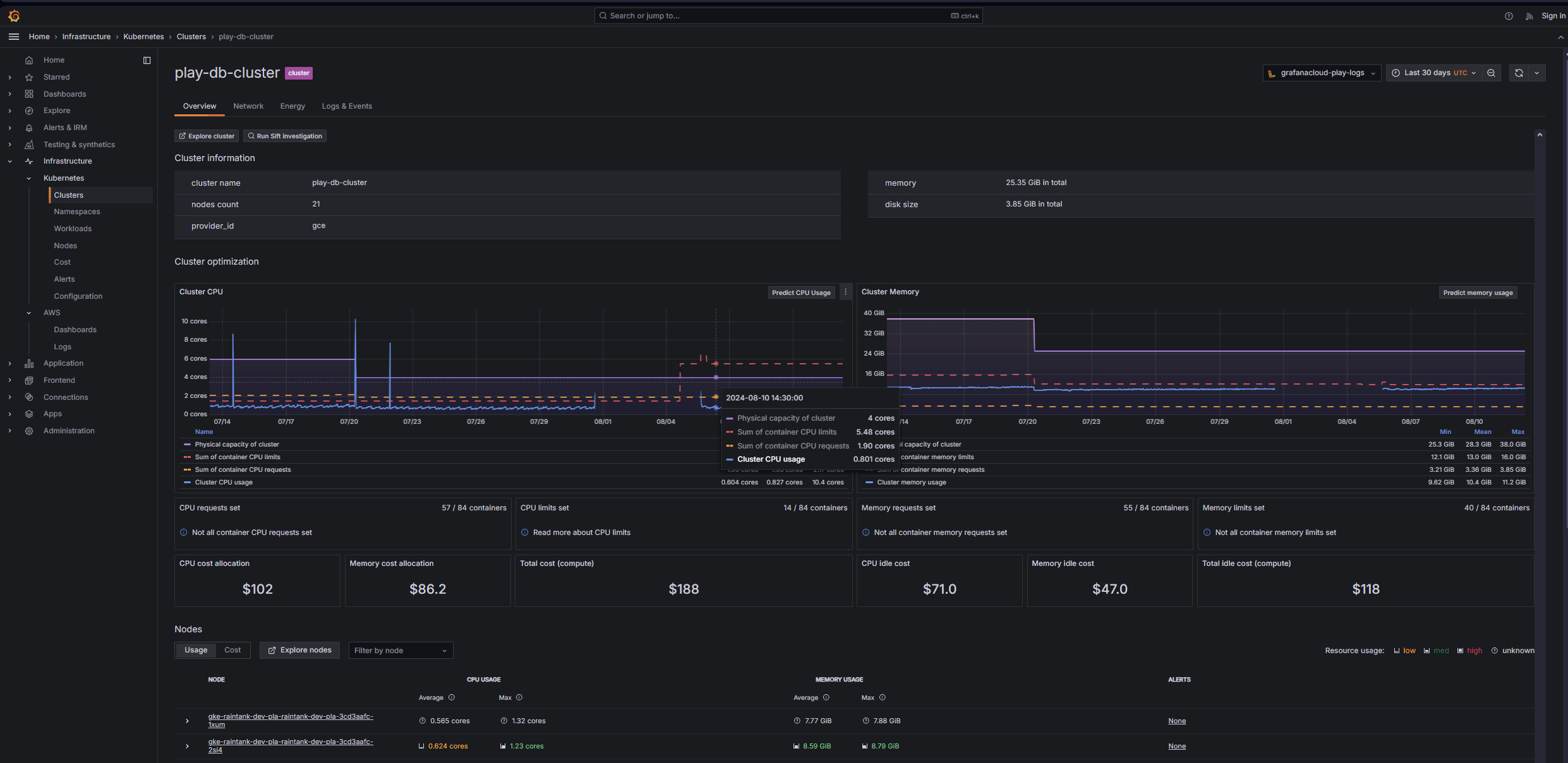
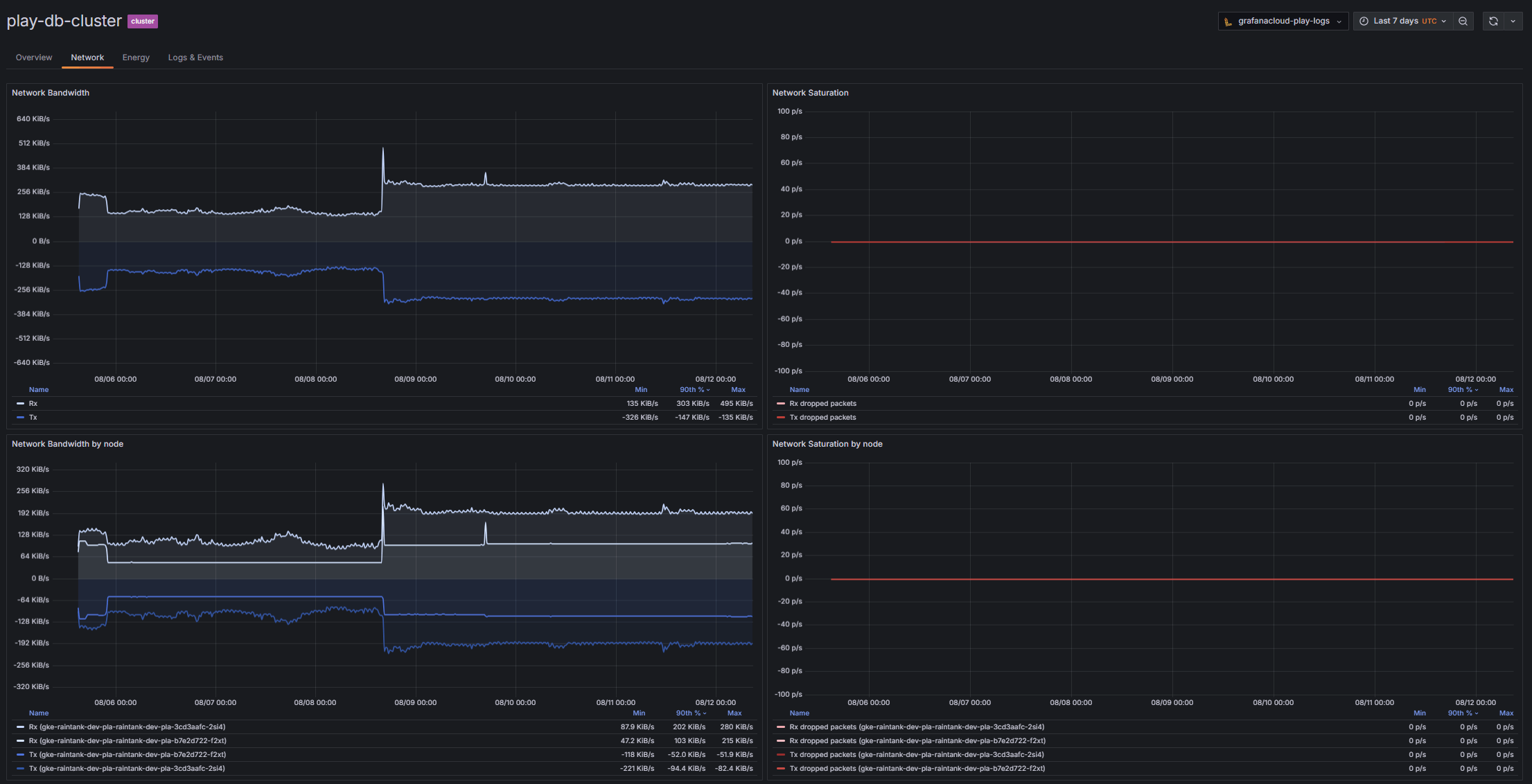
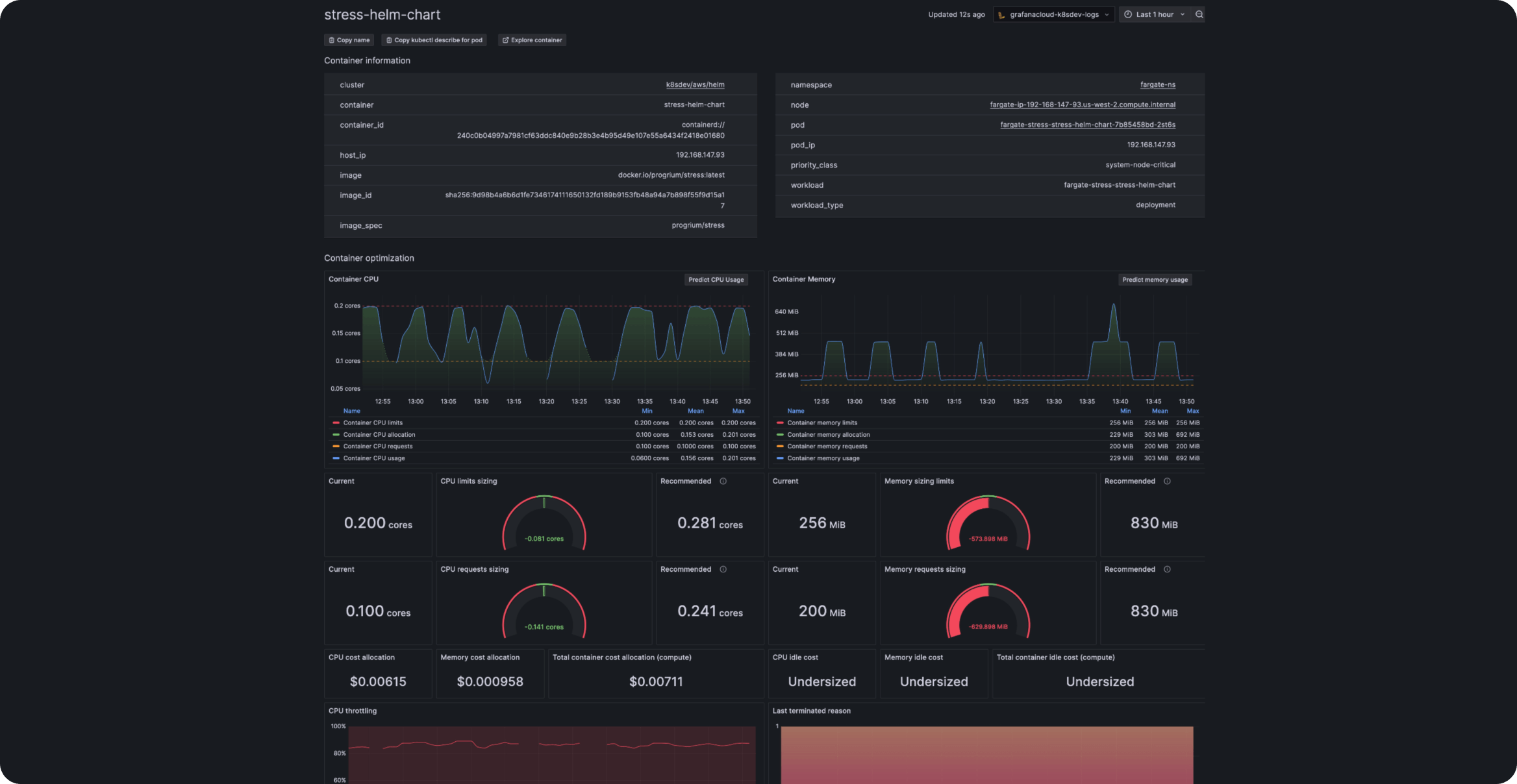
全面可见性,从 Kubernetes 集群到容器
获取 Kubernetes 集群的完整视图,然后深入查看特定的容器级信息。
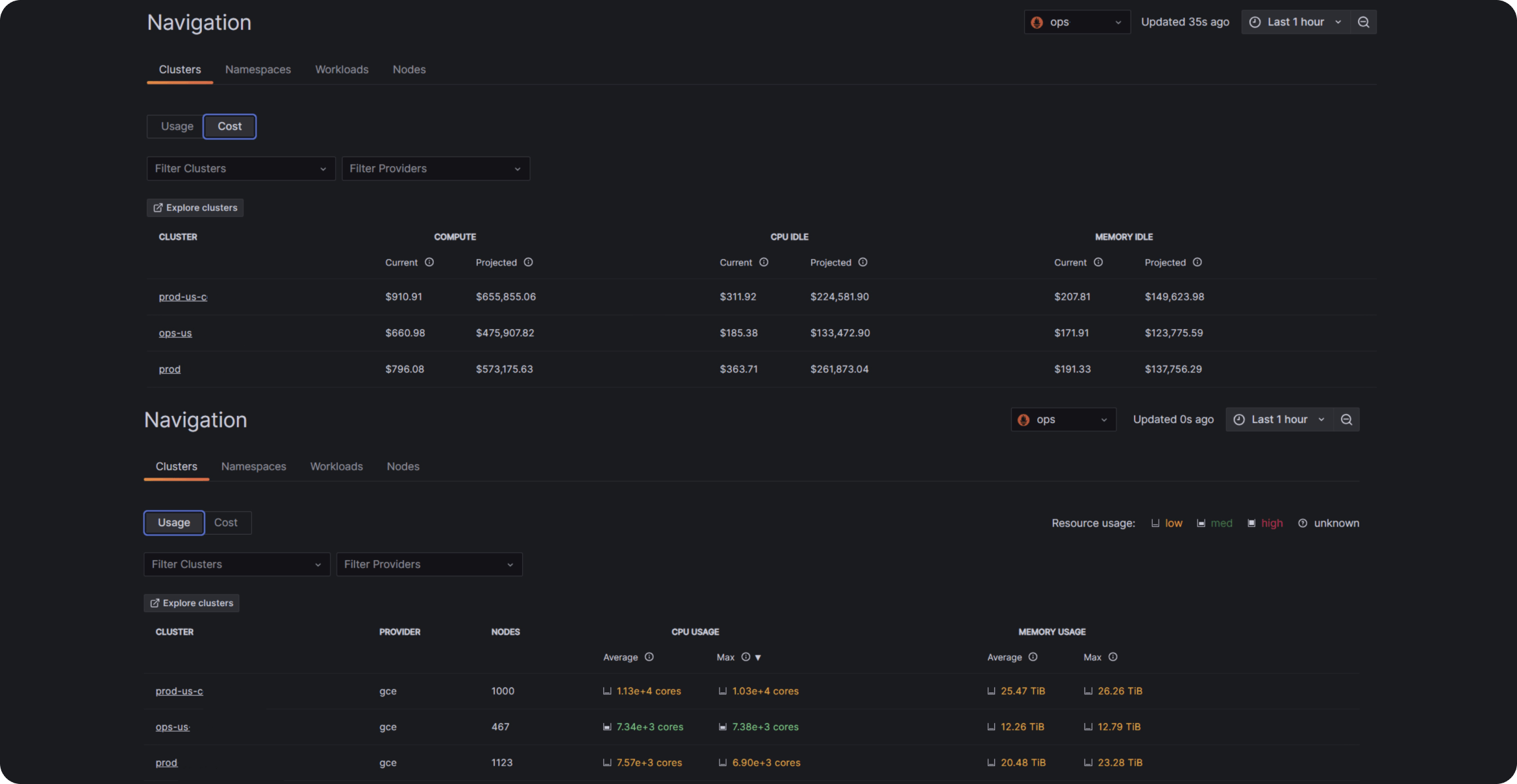
- 每个基础设施级别的成本和资源使用情况归属
- 颜色编码的资源使用可视化和图标有助于更快识别和解决问题
- 峰值与平均资源效率的并排比较
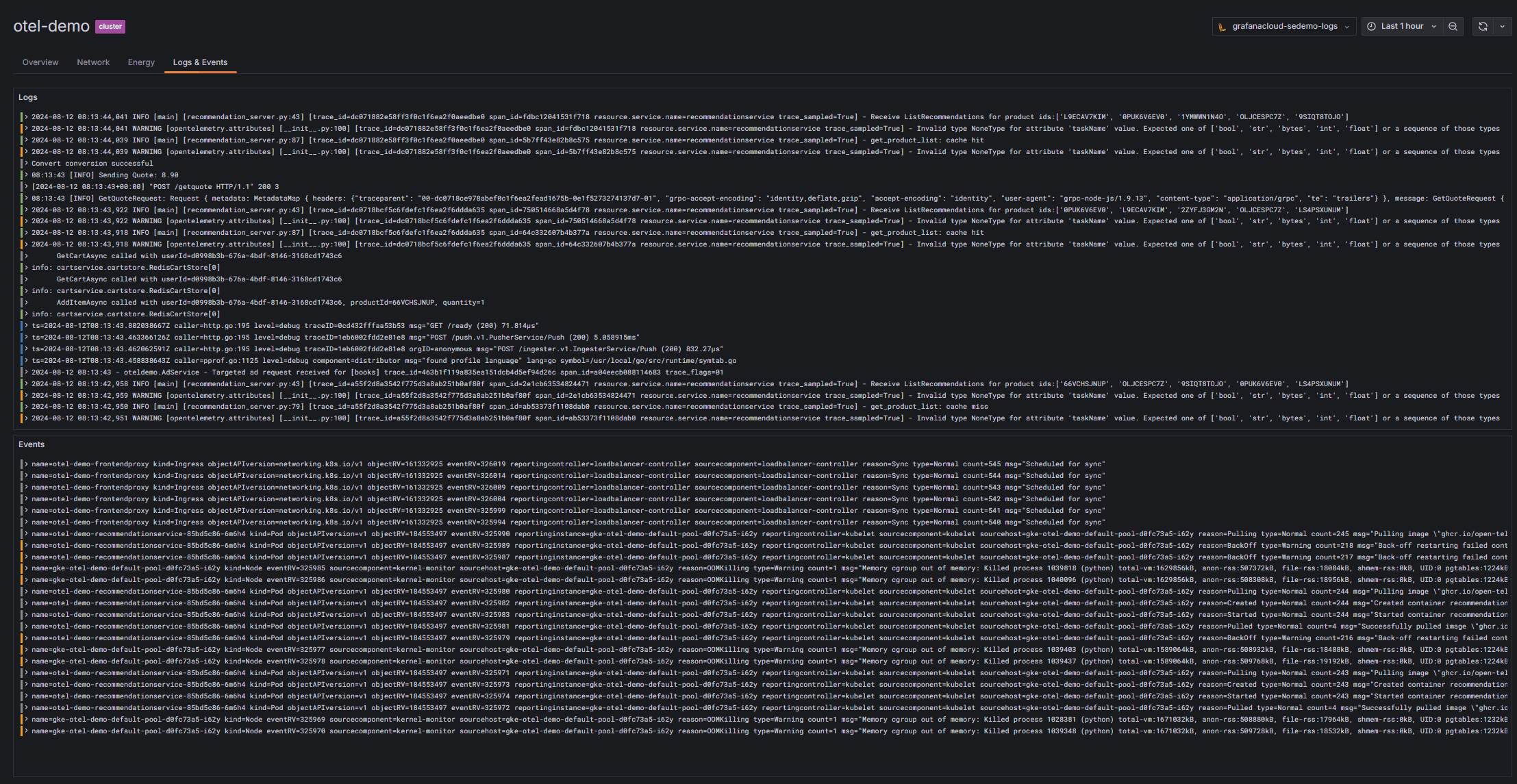
即时 Prometheus 关联日志
Prometheus 和 Grafana Loki 的元数据为您的 Kubernetes 集群保留相同的标签,因此访问相关的 Kubernetes 指标和日志再简单不过了。
轻松上手
了解完整的实施详情和最佳实践
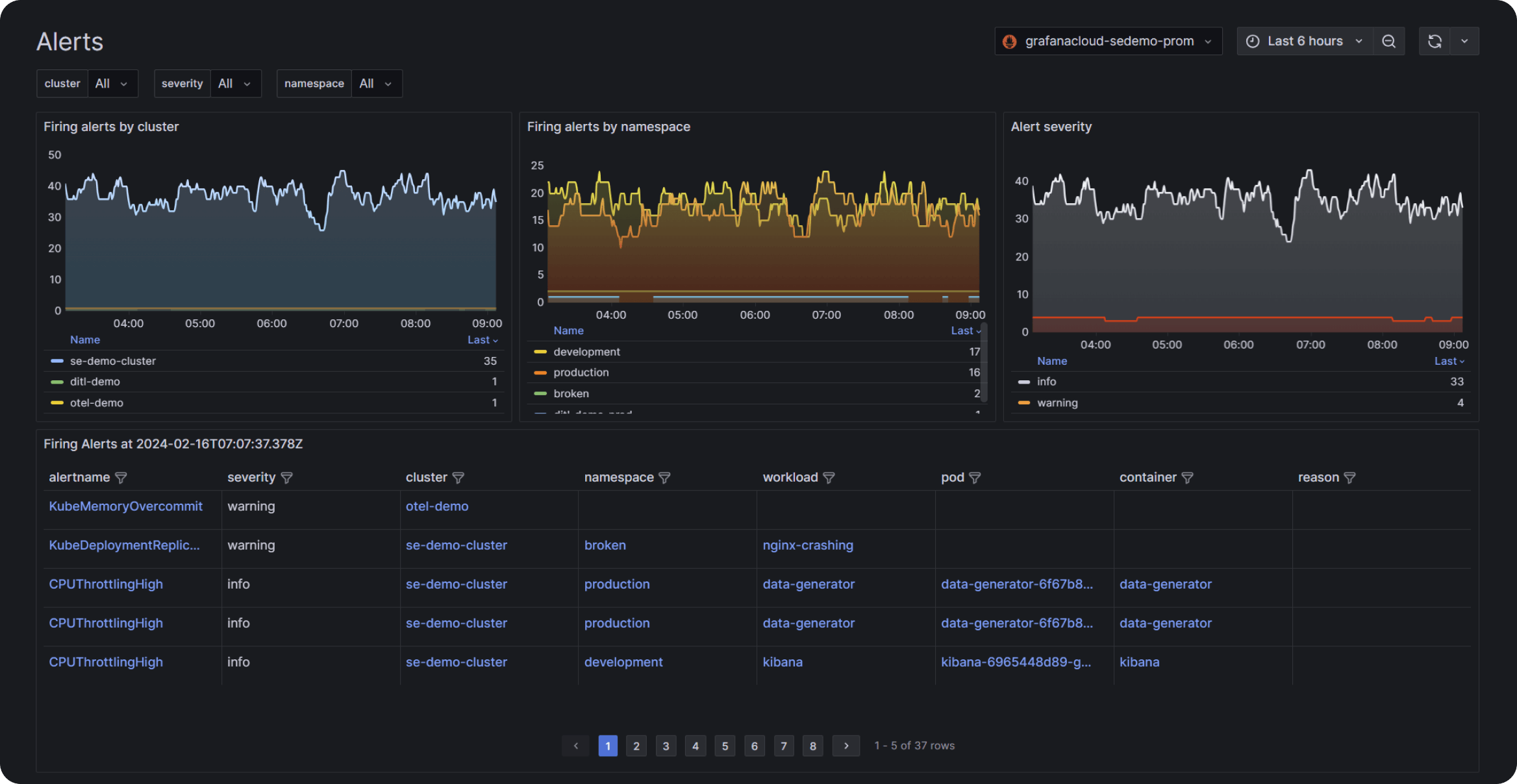
Kubernetes 指标和警报规则
Grafana Cloud 中的 Kubernetes 监控解决方案以 60 秒的采集间隔摄取一组默认指标。警报规则集有助于设置和运行集群及其工作负载的警报。
了解更多关于Kubernetes 指标和警报规则的信息
包含的关键警报规则
KubeNodeNotReady
KubeNodeUnreachable
KubeletTooManyPods
KubeNodeReadinessFlapping
KubeletPlegDurationHigh
KubeletPodStartUpLatencyHigh
KubeletClientCertificateExpiration
KubeletServerCertificateExpiration
KubeletClientCertificateRenewalErrors
KubeletServerCertificateRenewalErrors
KubeletDown
KubeVersionMismatch
KubeClientErrors
KubeCPUOvercommit
KubeMemoryOvercommit
KubeCPUQuotaOvercommit
KubeMemoryQuotaOvercommit
KubeQuotaAlmostFull
KubeQuotaFullyUsed
KubeQuotaExceeded
CPUThrottlingHigh
KubePodCrashLooping
KubePodNotRead
KubeDeploymentGenerationMismatch
KubeDeploymentReplicasMismatch
KubeStatefulSetReplicasMismatch
KubeStatefulSetGenerationMismatch
KubeStatefulSetUpdateNotRolledOut
KubeDaemonSetRolloutStuck
KubeContainerWaiting
KubeDaemonSetNotScheduled
KubeDaemonSetMisScheduled
KubeJobCompletion
KubeJobFailed
KubeHpaReplicasMismatch
KubeHpaMaxedOut
包含的关键指标
cluster:namespace:pod_cpu:active:kube_pod_container_resource_limits
cluster:namespace:pod_cpu:active:kube_pod_container_resource_requests
cluster:namespace:pod_memory:active:kube_pod_container_resource_limits
cluster:namespace:pod_memory:active:kube_pod_container_resource_requests
container_cpu_cfs_periods_total
container_cpu_cfs_throttled_periods_total
container_cpu_usage_seconds_total
container_fs_reads_bytes_total
container_fs_reads_total
container_fs_writes_bytes_total
container_fs_writes_total
container_memory_cache
container_memory_rss
container_memory_swap
container_memory_working_set_bytes
container_network_receive_bytes_total
container_network_receive_packets_dropped_total
container_network_receive_packets_total
container_network_transmit_bytes_total
container_network_transmit_packets_dropped_total
container_network_transmit_packets_total
go_goroutines
kube_daemonset_status_current_number_scheduled
kube_daemonset_status_desired_number_scheduled
kube_daemonset_status_number_available
kube_daemonset_status_number_misscheduled
kube_daemonset_updated_number_scheduled
kube_deployment_metadata_generation
kube_deployment_spec_replicas
kube_deployment_status_observed_generation
kube_deployment_status_replicas_available
kube_deployment_status_replicas_updated
kube_horizontalpodautoscaler_spec_max_replicas
kube_horizontalpodautoscaler_spec_min_replicas
kube_horizontalpodautoscaler_status_current_replicas
kube_horizontalpodautoscaler_status_desired_replicas
kube_job_failed
kube_job_spec_completions
kube_job_status_succeeded
kube_namespace_created
kube_node_info
kube_node_spec_taint
kube_node_status_allocatable
kube_node_status_capacity
kube_node_status_condition
kube_pod_container_resource_limits
kube_pod_container_resource_requests
kube_pod_container_status_waiting_reason
kube_pod_info
kube_pod_owner
kube_pod_status_phase
kube_replicaset_owner
kube_resourcequota
kube_statefulset_metadata_generation
kube_statefulset_replicas
kube_statefulset_status_current_revision
kube_statefulset_status_observed_generation
kube_statefulset_status_replicas
kube_statefulset_status_replicas_ready
kube_statefulset_status_replicas_updated
kube_statefulset_status_update_revision
kubelet_certificate_manager_client_expiration_renew_errors
kubelet_certificate_manager_client_ttl_seconds
kubelet_certificate_manager_server_ttl_seconds
kubelet_cgroup_manager_duration_seconds_bucket
kubelet_cgroup_manager_duration_seconds_count
kubelet_node_config_error
kubelet_node_name
kubelet_pleg_relist_duration_seconds_bucket
kubelet_pleg_relist_duration_seconds_count
kubelet_pleg_relist_interval_seconds_bucket
kubelet_pod_start_duration_seconds_count
kubelet_pod_worker_duration_seconds_bucket
kubelet_pod_worker_duration_seconds_count
kubelet_running_container_count
kubelet_running_containers
kubelet_running_pod_count
kubelet_running_pods
kubelet_runtime_operations_duration_seconds_bucket
kubelet_runtime_operations_errors_total
kubelet_runtime_operations_total
kubelet_server_expiration_renew_errors
kubelet_volume_stats_available_bytes
kubelet_volume_stats_capacity_bytes
kubelet_volume_stats_inodes
kubelet_volume_stats_inodes_used
kubernetes_build_info
machine_memory_bytes
namespace_cpu:kube_pod_container_resource_limits:sum
namespace_cpu:kube_pod_container_resource_requests:sum
namespace_memory:kube_pod_container_resource_limits:sum
namespace_memory:kube_pod_container_resource_requests:sum
namespace_workload_pod
namespace_workload_pod:kube_pod_owner:relabel
node_namespace_pod_container:container_cpu_usage_seconds_total:sum_irate
node_namespace_pod_container:container_memory_cache
node_namespace_pod_container:container_memory_rss
node_namespace_pod_container:container_memory_swap
node_namespace_pod_container:container_memory_working_set_bytes
node_quantile:kubelet_pleg_relist_duration_seconds:histogram_quantile
process_cpu_seconds_total
process_resident_memory_bytes
rest_client_request_duration_seconds_bucket
rest_client_requests_total
storage_operation_duration_seconds_bucket
storage_operation_duration_seconds_count
storage_operation_errors_total
up
volume_manager_total_volumes
有用资源
60 分钟
GrafanaLive:使用 Grafana Cloud 改进 Beeswax 平台的可观测性
博客文章
引入 Grafana Cloud 中的 Kubernetes 监控
成功案例
随着在 Kubernetes 上运行的微服务呈倍数增长,PayIt 转向 Grafana 和 Prometheus,以实现云原生规模的可观测性
博客文章
引入 Grafana Cloud 中的 Kubernetes 监控
博客文章
在 Grafana Loki 的 Kubernetes 环境中进行大规模日志记录的五个技巧
博客文章
Kubernetes 监控的 5 大主要优势
博客文章
如何在 Grafana Cloud 中监控 Kubernetes 节点的健康状况和资源使用情况
博客文章
在 Grafana Cloud 中通过 Kubernetes 监控引入即时 Kubernetes 日志记录
博客文章
如何使用 Prometheus Operator 监控 Kubernetes 集群
博客文章
如何使用 Kubernetes 事件进行有效警报和监控
博客文章
监控 Kubernetes 层:需要了解的关键指标
博客文章
Kubernetes 应用中的分布式追踪:您需要了解的内容
博客文章
Kubernetes 应用监控新手指南
博客文章
如何使用 Grafana Loki、Grafana 和 Grafana Agent 收集和查询 Kubernetes 日志
博客文章
如何使用 Argo CD 在 Grafana Cloud 中配置 Kubernetes 监控
博客文章
如何将现有 Grafana 仪表盘和警报迁移到 Grafana Cloud 中的 Kubernetes 监控
博客文章
如何使用 Grafana Cloud 的 Kubernetes 监控优化资源利用率
博客文章
Kubernetes 警报:使用 Grafana Cloud 简化 Kubernetes 集群中的异常检测
博客文章
Kubernetes 资源限制的案例:可预测性 vs 效率