
在 Grafana Cloud 中自动化、记录和学习事件管理
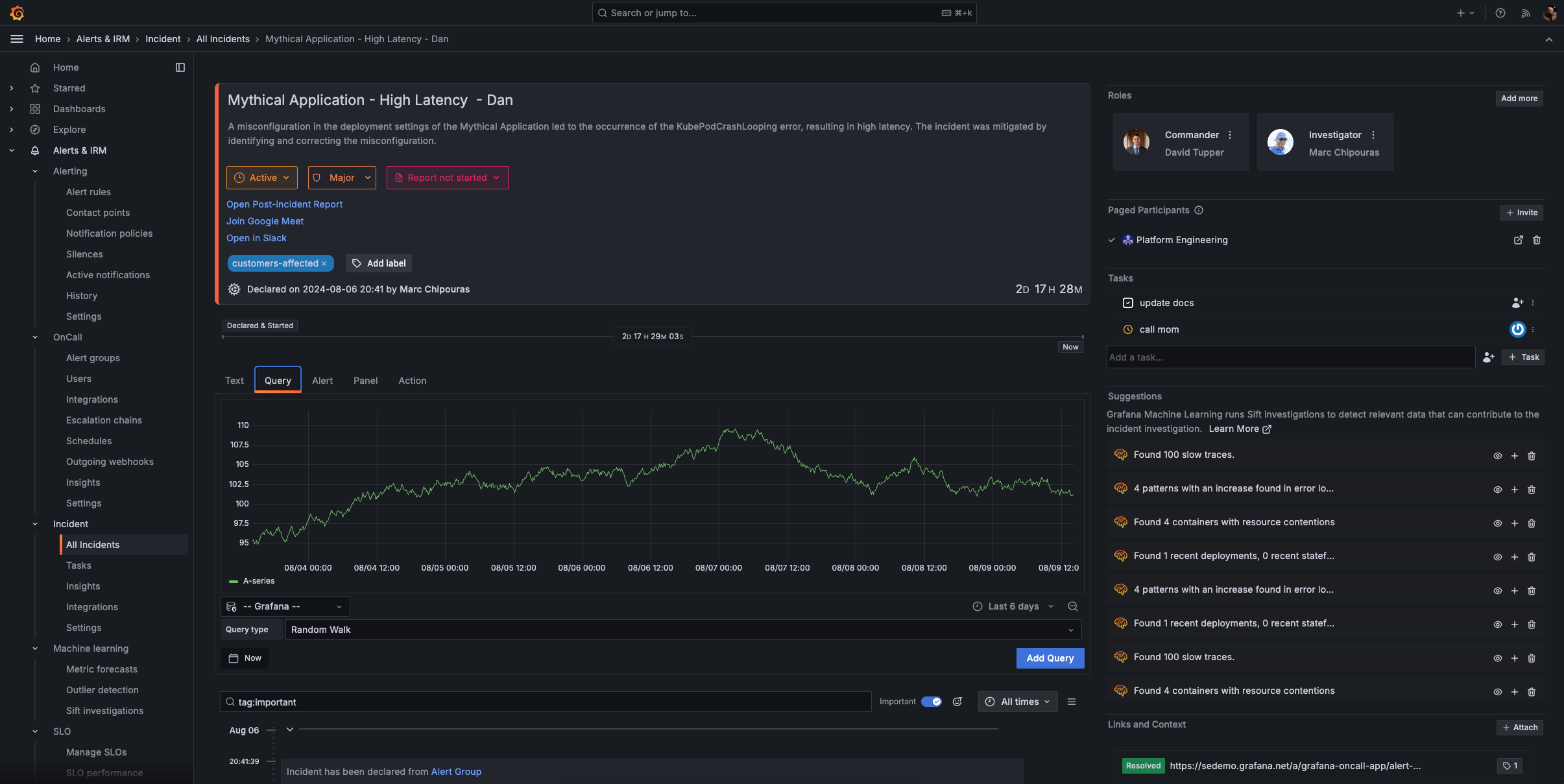
Incident 是 Grafana Cloud IRM 应用的一部分,它是一个事件管理工具,能够自动化处理例行任务,从而让您的团队更快地专注于解决事件(并从中改进)。
所有你需要的信息,都已为你记录
通过全面的事件时间线学习,以缓解未来的问题。无论何时何地声明事件,您都将捕获从开始到结束的所有关键信息。
您的单一真实来源
无需再匆忙地寻找散布在各个平台上的正确信息。集中沟通,避免事件期间的混乱。
专注于最重要的事情
自动化手动管理工作,让工程师能够专注于任务并更快地修复问题。
快速轻松地声明事件
一旦发现问题,您可以从任何 Grafana 可视化图表触发事件。
- 为响应者嵌入正确的上下文,例如相关的仪表板和指标。
- 在声明事件时分配适当的严重级别,以优先处理响应工作,并邀请参与者进行协作。
- 在 Grafana 生态系统中从监控转向主动事件响应,并直接从您的可视化图表创建事件频道和协作空间。
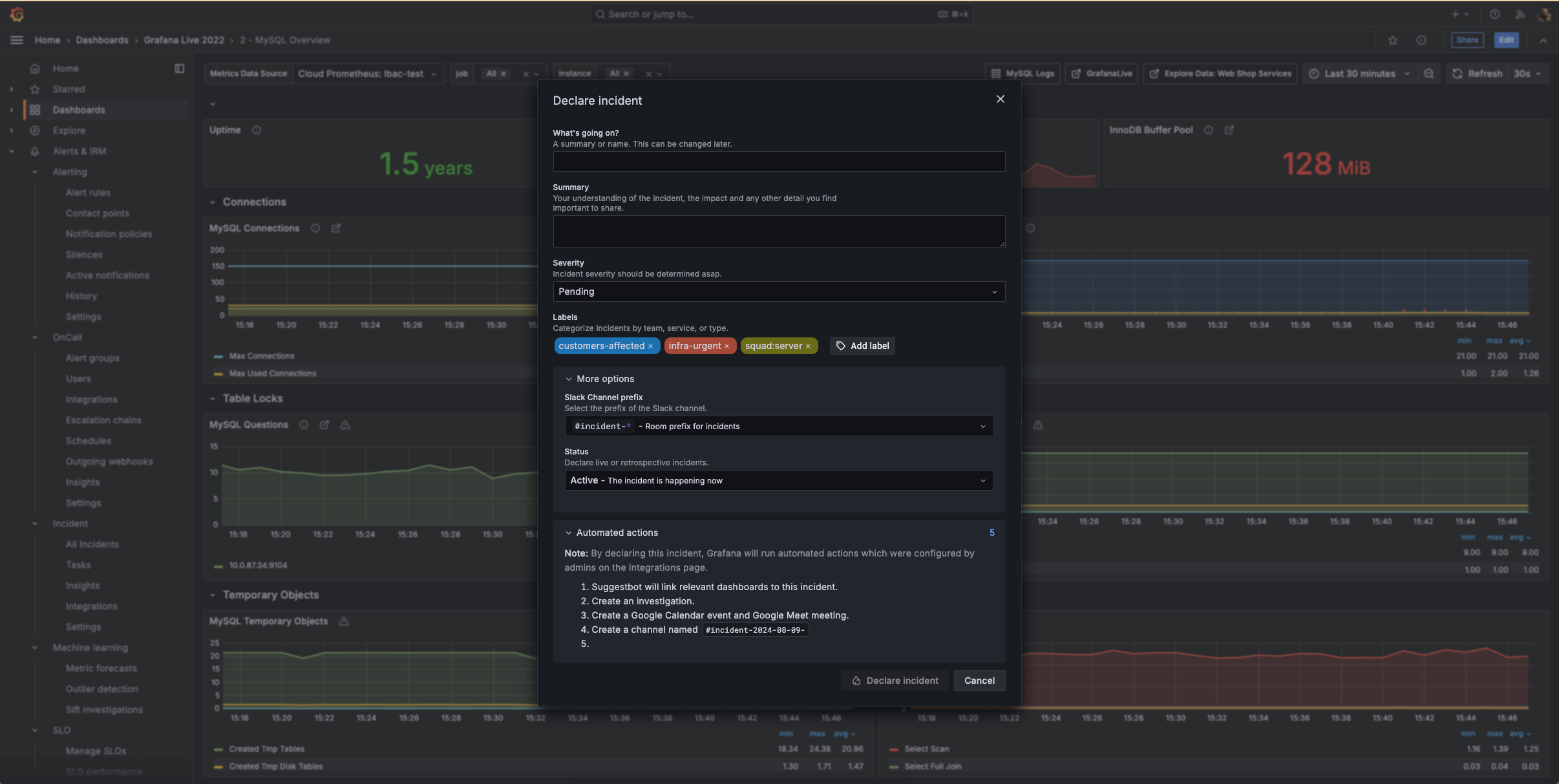
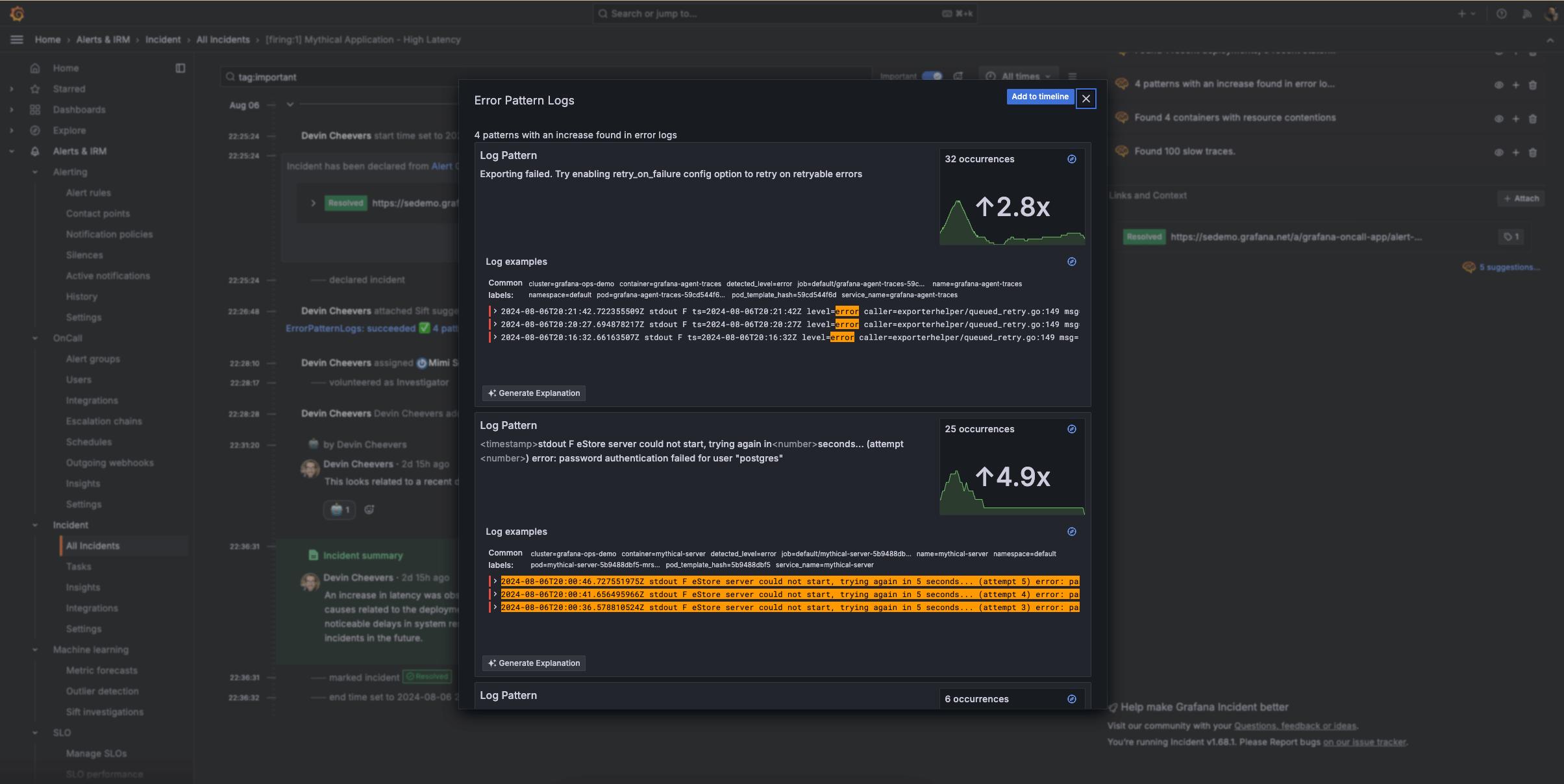
记录所有重要事项
自动为每个事件生成单一真实来源,以便您更好地跟踪正在进行的事件并改进未来的响应。
- 为每个事件维护集中的记录,以便所有团队成员都能访问一致、准确的信息。
- 在事件生命周期中捕获关键决策和更新,包括相关的 Grafana 面板和重要的 Slack 通知。
- 自动将事件、通信和行动组织成清晰、按时间顺序排列的时间线,以跟踪事件的进展和响应工作。
- 将事件时间线转换为结构化的事后评审 (PIR) 文档,并利用预填充的事件数据和关键事件简化评审流程。
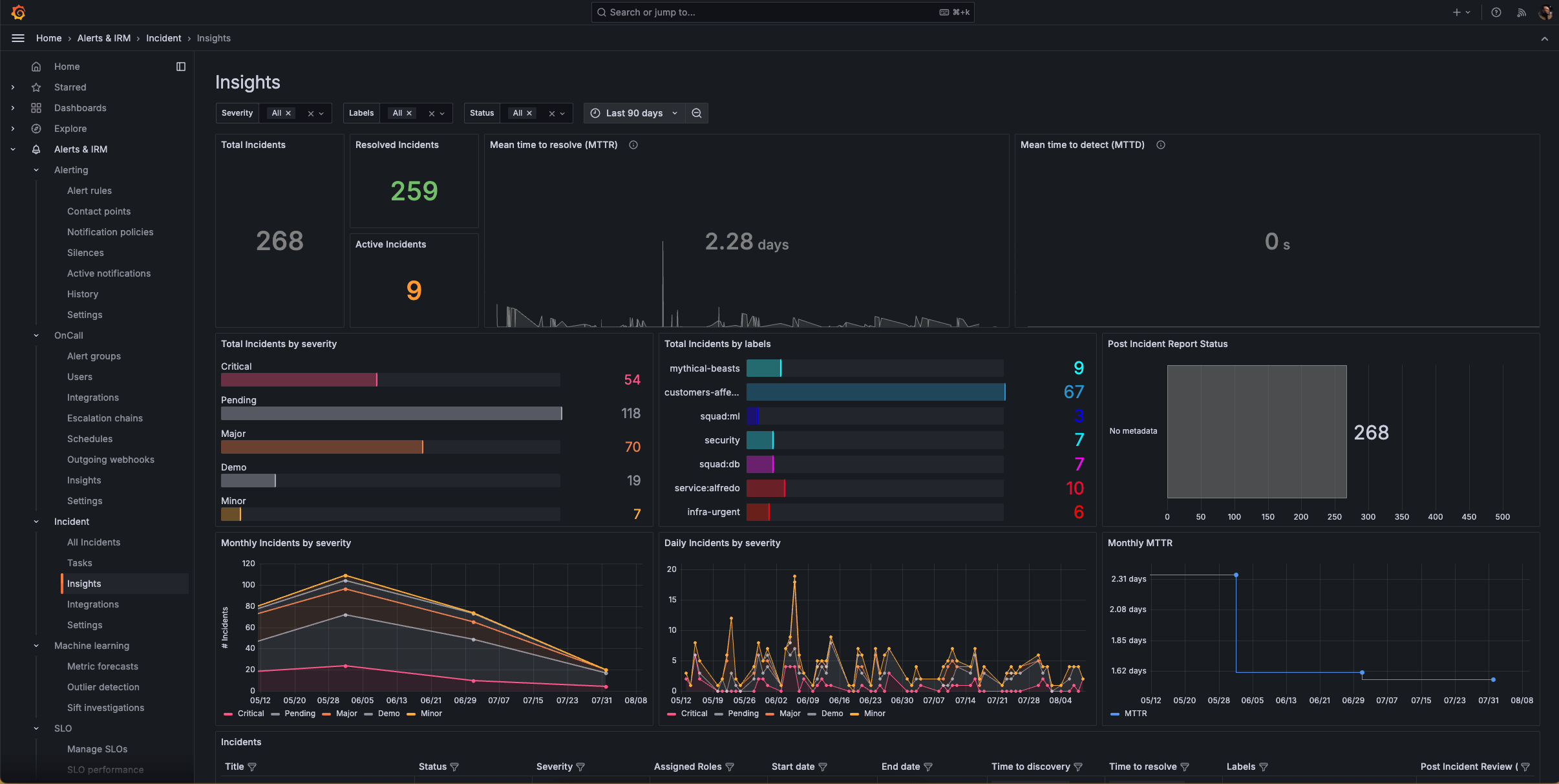
分析并改进您的事件管理操作
全面了解您的事件运营绩效,以便通过数据驱动的洞察持续改进您的流程。
- 概览您的事件管理工作流程,并深入了解事件频率和解决情况的趋势和模式。
- 跟踪关键指标,例如平均解决时间 (MTTR) 和平均检测时间 (MTTD),识别瓶颈,并按标签、严重级别或状态等各种维度分析绩效。
- 收集事件频率和类型数据,以优化您的可观测性和响应策略。
利用机器学习减少 MTTR
利用 Sift(Grafana Cloud 中强大的诊断助手)发现问题,减少 MTTR 和 MTTD。
- 自动扫描指标和日志,提供系统健康状况的整体视图,并关联来自多个来源的数据,以识别复杂、相互关联的问题。
- 使用 Sift 检查开始事件,并自动收集相关的上下文和数据,以快速启动事件响应流程。
- Sift 会根据反馈和结果持续改进其检测能力,并随着时间的推移适应不断变化的系统行为和新类型的问题。
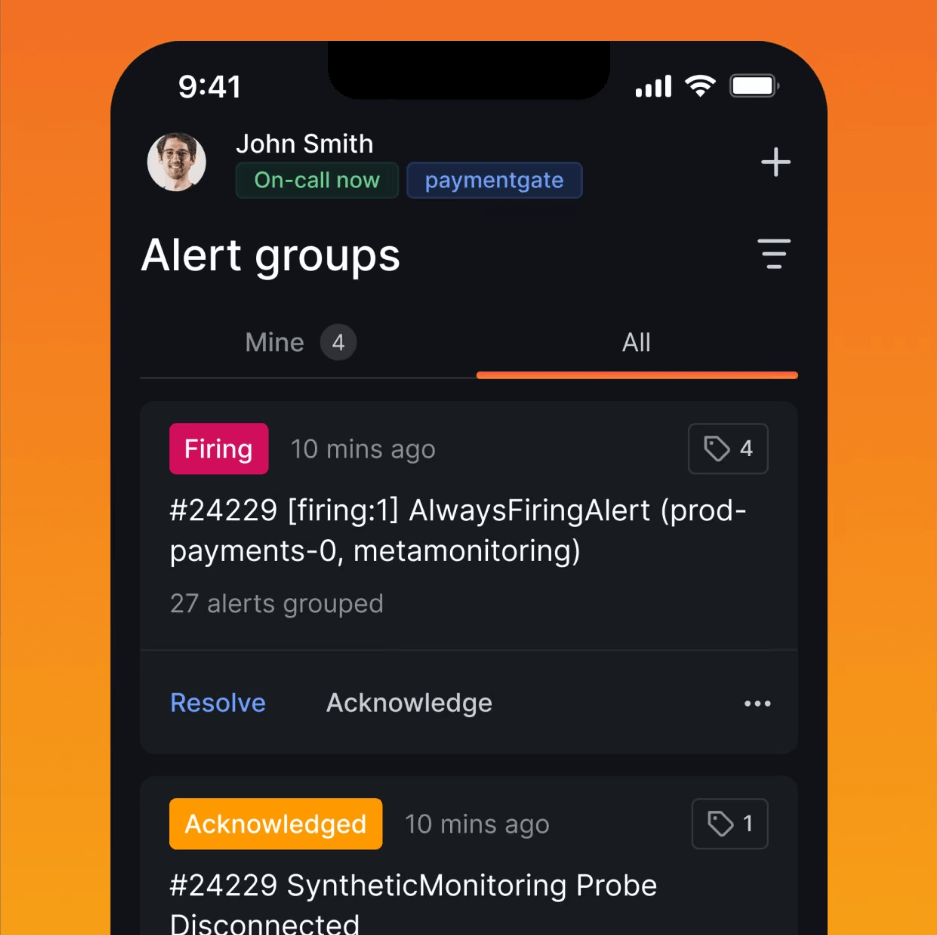
移动中的事件响应和管理
借助 IRM 移动应用,您可以随时随地处理紧急情况。
个性化通知
- 接收根据您的个人偏好量身定制的推送通知。
- 对于紧急情况,可覆盖“请勿打扰”设置。
触手可及的值班排程
- 随时随地查看值班轮换详情。
- 快速查看即将到来的排班和团队可用性。
- 轻松与您的团队请求换班。
按需查看事件详情
- 直接从您的移动设备确认、响应或升级事件。
- 访问全面的事件信息,以便做出明智的决策。
在 Grafana Cloud 中开始事件响应和管理
2
连接工具(推荐)
设置与您常用应用的集成,例如 Slack,您可以在相关频道中添加 Grafana Incident 聊天机器人。
3
配置通知
决定每个用户如何接收通知并创建升级规则。
4
设置值班排程并开始声明事件
在 UI 中建立值班排程并声明您的第一个演练事件。
有关完整的实施详情和最佳实践,
在 Grafana Cloud 中获取 IRM
检测、响应和学习。Grafana Cloud IRM 简化了事件工作流程,帮助您专注于管理事件,而不是工具。