
插件 〉HPE Clusterview

HPE Clusterview
Clusterview Grafana 插件
一个专注于高性能计算的数据点密集视图。

预期的查询数据格式
数据预期采用长格式,包含一个值列和一个或多个描述布局的列。可以存在额外的字段,以提供鼠标悬停、块内显示或可点击链接的 URL 的附加信息。
查询数据的一个最小示例
| 位置 | 值 |
|---|---|
| x1000c0s0b0n0 | 20.1 |
| x1000c1s2b1n0 | 21.2 |
| x1001c0s7b0n0 | 20.7 |
| ... |
更复杂的查询可能会添加用于附加文本显示或 URL 的字段,和/或将位置拆分为多个字段
| 名称 | 行 | 插槽 | 索引 | 值 | 外部 ID |
|---|---|---|---|---|---|
| node 11-0 | 1 | 1 | 0 | 20.1 | bk39dj |
| node 12-0 | 1 | 2 | 0 | 21.2 | sMfek3 |
| node 21-0 | 2 | 1 | 0 | 20.7 | BL9bap |
| node 21-1 | 2 | 1 | 1 | 16.0 | LQ0doV |
| ... |
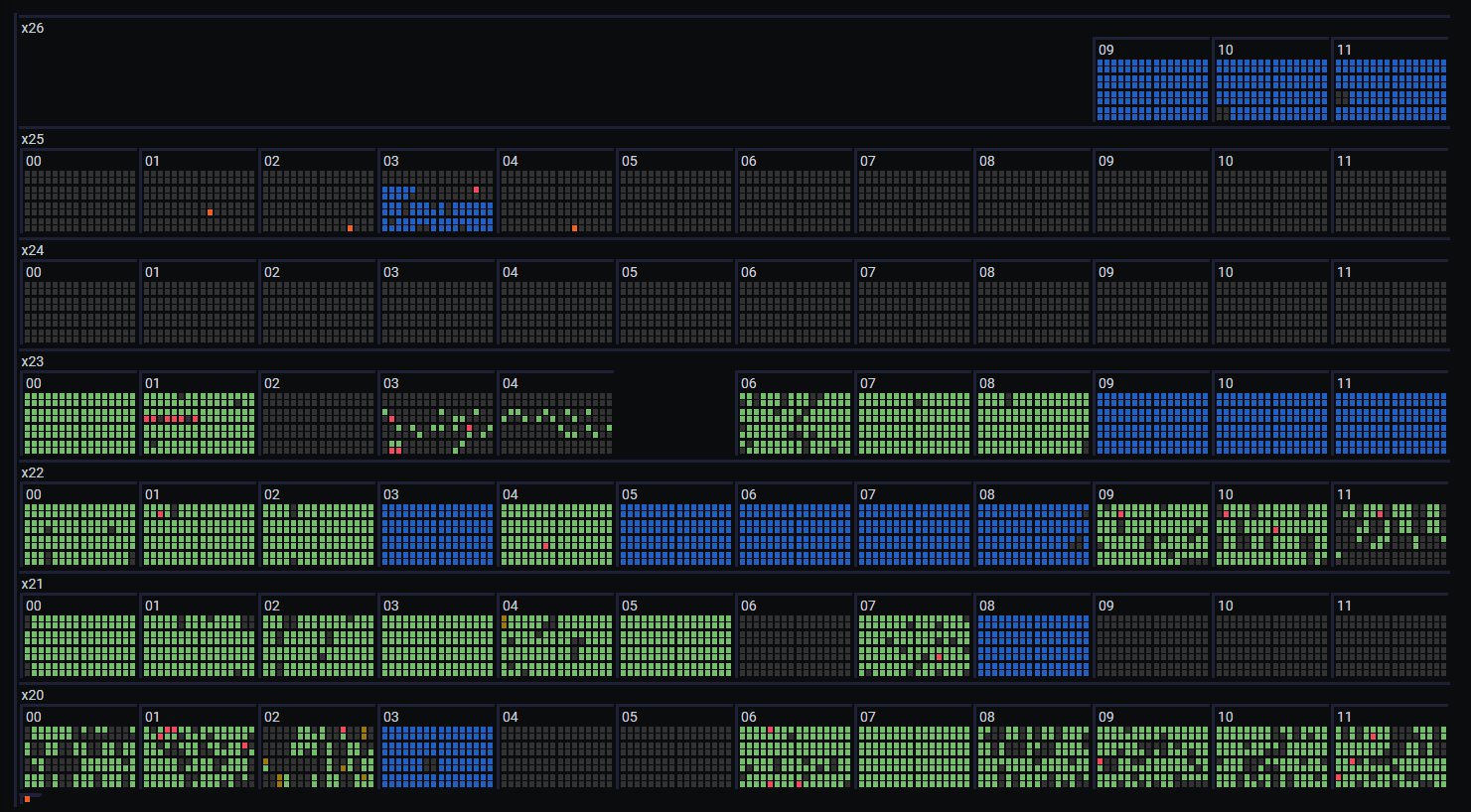
数据分组
显示基于一个或多个字段组织成层次结构。层次结构的每一层都可以进行不同的配置,以实现更复杂的布局。

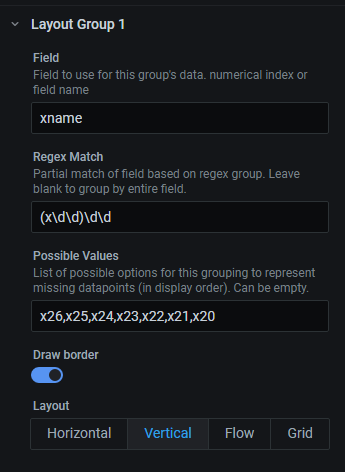
字段
定义哪个字段包含此层的位置数据。这可以是字段的名称,也可以是零索引整数。如果留空,这将是层次结构中的最终布局组。
正则表达式匹配
一个用于从字段中提取位置数据的正则表达式。这应该是一个带有单个捕获组的正则表达式,用于定义层次结构中此层的值。如果字段不需要分割成多个部分,可以留空,将使用整个值。
例如,如果位置字段看起来像 x1000c0s0b0n0,那么正则表达式匹配字段可以写成
(x\d+)- 标识符: x1000x\d+(c\d)- 标识符: c0x\d+c\d(s\d)- 标识符: s0x\d+c\ds\d(b\d)- 标识符: b0x\d+c\ds\db\d(n\d)- 标识符: n0
可能的值
可以在此处指定此层可能存在的一组实例。对于列表中但查询中不存在的任何值,将显示一个 null 值占位符。这可以在查询数据缺失时创建一致的输出。它还用于指定值的顺序,否则这些值将按照查询中的数据顺序显示。
绘制边框和显示标签
在数据周围显示标签或(部分)边框。
注意:边框和标签显示在层中的所有实体周围,而不是层中的单个实例,因此它们的应用可能并不总是直观的。
布局
层次结构的每一层(组)可以采用不同的布局方向。具有不同布局的多层可以组合形成复杂的排列。布局类型包括
- 水平 - 节点在屏幕上横向显示。
- 垂直 - 节点垂直显示。
- 流式 - 类似于水平布局,但会自动换行到下一行。
- 网格 - 以固定列数显示。
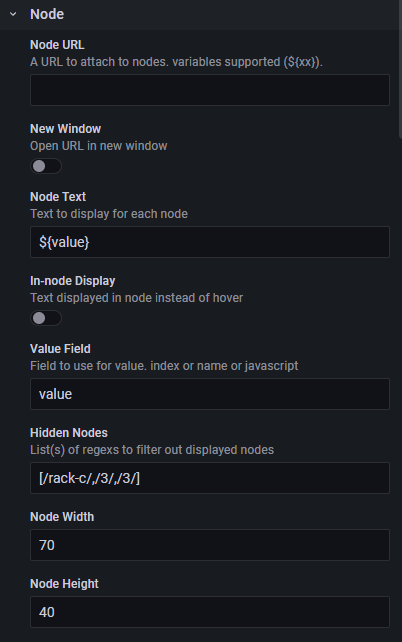
节点
节点部分描述了关于显示节点的详细信息。

节点 URL
如果存在节点 URL,每个节点将成为指向给定 URL 的链接。URL 中也可以包含变量 ${FieldName}。
节点文本
鼠标悬停时显示的文本,或者如果选择了节点内显示,则直接显示在节点上。文本中可以包含变量。
值字段
使用此项指定用于确定显示颜色的值。这可以是字段的整数索引或字段名称。
1值
隐藏节点
在某些情况下,您可能希望为某些节点预留空间,但不想将其显示为缺失。这可能是为了匹配物理布局中某些东西不存在或未填充的情况。隐藏节点字段允许这样做。它接受一个或多个正则表达式数组,用于匹配每个层组中的不同值。
对于每个期望的匹配,应提供一个数组。该数组应包含与层次结构中的层数相同数量的元素。每个元素应是一个正则表达式(用 / 转义),用于匹配该层的数据。如果只需要一个匹配,可以提供一个正则表达式数组。如果存在多个匹配,则应使用数组的数组。
假设一个仪表盘具有一个 3 层分组层次结构,第一层是 a,b,c;第二层是 1,2,3;第三层也是 1,2,3;以下是隐藏节点值的示例
[ /a/, /1/, /2/]- 节点 a12 将留空。[ [ /b/, /.*/, /.*/], [ /c/, /1/, /.*/]]- 所有 b* 和任何以 c1* 开头的内容将留空。
值/颜色
用于显示颜色谱的配置。颜色将根据查询值进行插值。超出给定阈值范围的值将被限制在最近的端点。
条件
一组逻辑条件,用于确定节点显示为什么颜色。支持多种不同的条件格式。
最简单的用法是单个值,它与值字段中指定的字段完全匹配
1- 匹配值字段中的 1。'ok'- 匹配值字段中的 'ok'。
单引号、双引号或不使用引号都可以用于指定值。
下一个最简单的方法是将逻辑运算符与值组合。这也将与值字段中指定的字段匹配。数字支持以下逻辑比较:==, =, <, <=, >, >=, !=。
>3- 匹配值字段大于 3。!=10- 匹配所有不等于 10 的值。
此外,可以使用 MATCH 或 MATCHES (不区分大小写)进行正则表达式匹配。除非使用 ^ 和 $,否则这将匹配部分值
MATCH '^(ok|OK)$'- 匹配等于ok或OK的任何值字段MATCHES ".*01$"- 匹配任何以01结尾的值字段
也可以使用其他字段(使用 $VAR 或 ${VAR} 语法)。这些字段还可以与布尔运算符组合创建更复杂的条件
$value == 0 AND $status MATCHES 'ok.*'$value<1 && ($subvalue <10 || $subvalue == 'missing')
支持的布尔运算有: and, &&, &, or, ||, |, ()
条件从上到下执行。第一个匹配的条件将决定颜色。空的条件字段将匹配所有现有字段。
聚合
对于时间序列数据,执行聚合以将每个节点减少为单个值。在大多数情况下,修改查询以仅报告每个节点的最新数据是比使用聚合更理想的解决方案(特别是对于大型仪表盘的性能)。
聚合数据
如果存在多个重复条目,使用此方法将它们合并。
- 无 - 不进行任何合并。如果存在任何重复项,则使用查询中的最新值。
- Max - 所有重复项的最大值。
- Min - 所有重复项的最小值。
- Last - 使用最新值。这需要选择时间戳字段。
时间戳字段
用作时间戳的字段。仅在使用 last 作为聚合时需要
忽略空值
如果设置,空值将从数据集中过滤掉。
在 Grafana Cloud 上安装 HPE Clusterview
在 Grafana Cloud 实例上安装插件是一键式操作;更新也是如此。很酷吧?
请注意,可能需要最多 1 分钟才能在您的 Grafana 中看到该插件。
在 Grafana Cloud 实例上安装插件是一键式操作;更新也是如此。很酷吧?
请注意,可能需要最多 1 分钟才能在您的 Grafana 中看到该插件。
在 Grafana Cloud 实例上安装插件是一键式操作;更新也是如此。很酷吧?
请注意,可能需要最多 1 分钟才能在您的 Grafana 中看到该插件。
在 Grafana Cloud 实例上安装插件是一键式操作;更新也是如此。很酷吧?
请注意,可能需要最多 1 分钟才能在您的 Grafana 中看到该插件。
在 Grafana Cloud 实例上安装插件是一键式操作;更新也是如此。很酷吧?
请注意,可能需要最多 1 分钟才能在您的 Grafana 中看到该插件。
在 Grafana Cloud 实例上安装插件是一键式操作;更新也是如此。很酷吧?
请注意,可能需要最多 1 分钟才能在您的 Grafana 中看到该插件。
在 Grafana Cloud 实例上安装插件是一键式操作;更新也是如此。很酷吧?
请注意,可能需要最多 1 分钟才能在您的 Grafana 中看到该插件。
了解更多信息,请访问有关插件安装的文档。
在本地 Grafana 上安装
对于本地实例,插件通过简单的 CLI 命令安装和更新。插件不会自动更新,但当更新可用时,您会在 Grafana 中收到通知。
1. 安装面板
使用 grafana-cli 工具从命令行安装 HPE Clusterview
grafana-cli plugins install 插件将安装到您的 grafana 插件目录;默认目录是 /var/lib/grafana/plugins。更多关于 CLI 工具的信息。
2. 将面板添加到仪表盘
已安装的面板会立即显示在 Grafana 主菜单的“仪表盘”部分,并且可以像 Grafana 中的任何其他核心面板一样添加。
要查看已安装面板列表,请单击主菜单中的 Plugins 项目。核心面板和已安装面板都会显示。
变更日志
1.2.0
- 未聚合时移除额外节点
- 文档和文本清理
- 公开发布
1.1.0
- 支持 Grafana 9.x
- 修复 Safari 浏览器问题
1.0.0
- 初始版本。