
插件 〉Apache Cassandra

Apache Cassandra
Grafana 的 Apache Cassandra 数据源
此数据源用于可视化存储在 Cassandra/DSE 中的**时间序列数据**,如果您正在寻找 Cassandra **指标**,则可能需要使用 datastax/metric-collector-for-apache-cassandra。
![]()
![]()
要查看此数据源的实际应用,请按照快速演示步骤操作。文档可在此处获取此处
支持版本/兼容性:
- Grafana
- 7.x, 8.x, 9.x, 10.x 完全支持(插件版本 2.x)
- 5.x, 6.x 已弃用(适用于插件版本 1.x,但建议升级)
- Cassandra 3.x, 4.x
- DataStax Enterprise 6.x
- DataStax Astra (文档)
- AWS Keyspaces(有限支持)(文档)
- Linux, OSX(包括 M1), Windows
功能特性:
- 使用认证凭据和 TLS 连接到 Cassandra
- 查询配置器
- 原生 CQL 查询编辑器
- 表格模式
- 变量
- 注释
- 告警
联系方式:
目录
使用方法
您可以在数据源 wiki 中找到更详细的说明。
安装
- 使用 grafana 控制台工具安装插件:
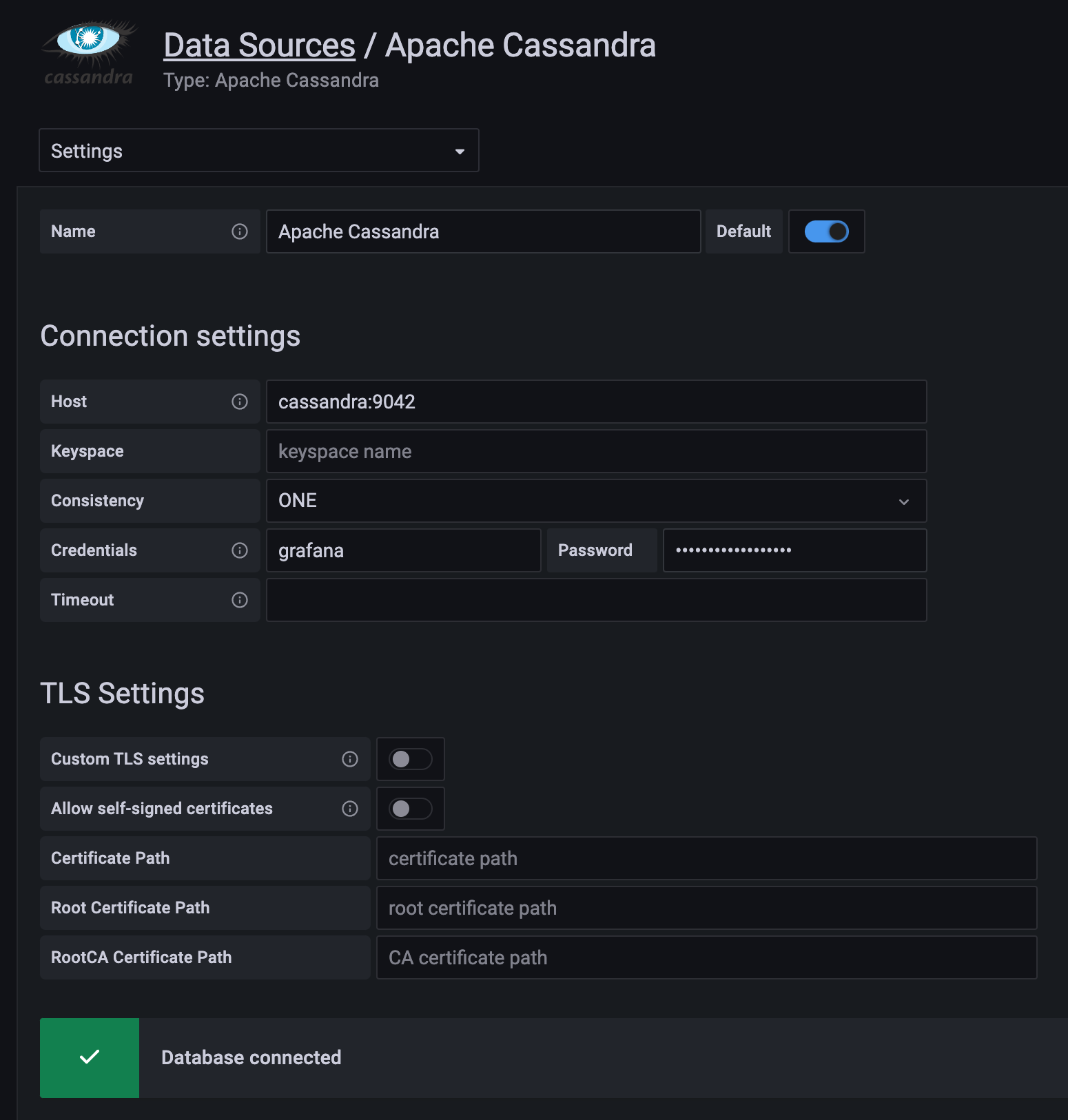
grafana-cli plugins install hadesarchitect-cassandra-datasource。插件将安装到您的 grafana 插件目录中;默认目录为/var/lib/grafana/plugins。另外,您也可以从最新发布版本下载插件,请下载cassandra-datasource-VERSION.zip文件并将其解压到 Grafana 插件目录(grafana/plugins)中。 - 在数据源配置页面将 Apache Cassandra 数据源添加为一个数据源。
- 配置数据源,指定联系点和端口,例如 "10.11.12.13:9042",以及用户名和密码。强烈建议使用一个仅对您需要访问的表具有只读权限的专用用户。
- 点击“保存并测试”按钮,如果出现错误消息,请检查凭据和连接。

构建查询
从 Cassandra/DSE 查询数据有**两种方式**:**查询配置器**和**查询编辑器**。配置器更易于使用,但功能有限;编辑器更强大,但需要了解 CQL。
查询配置器

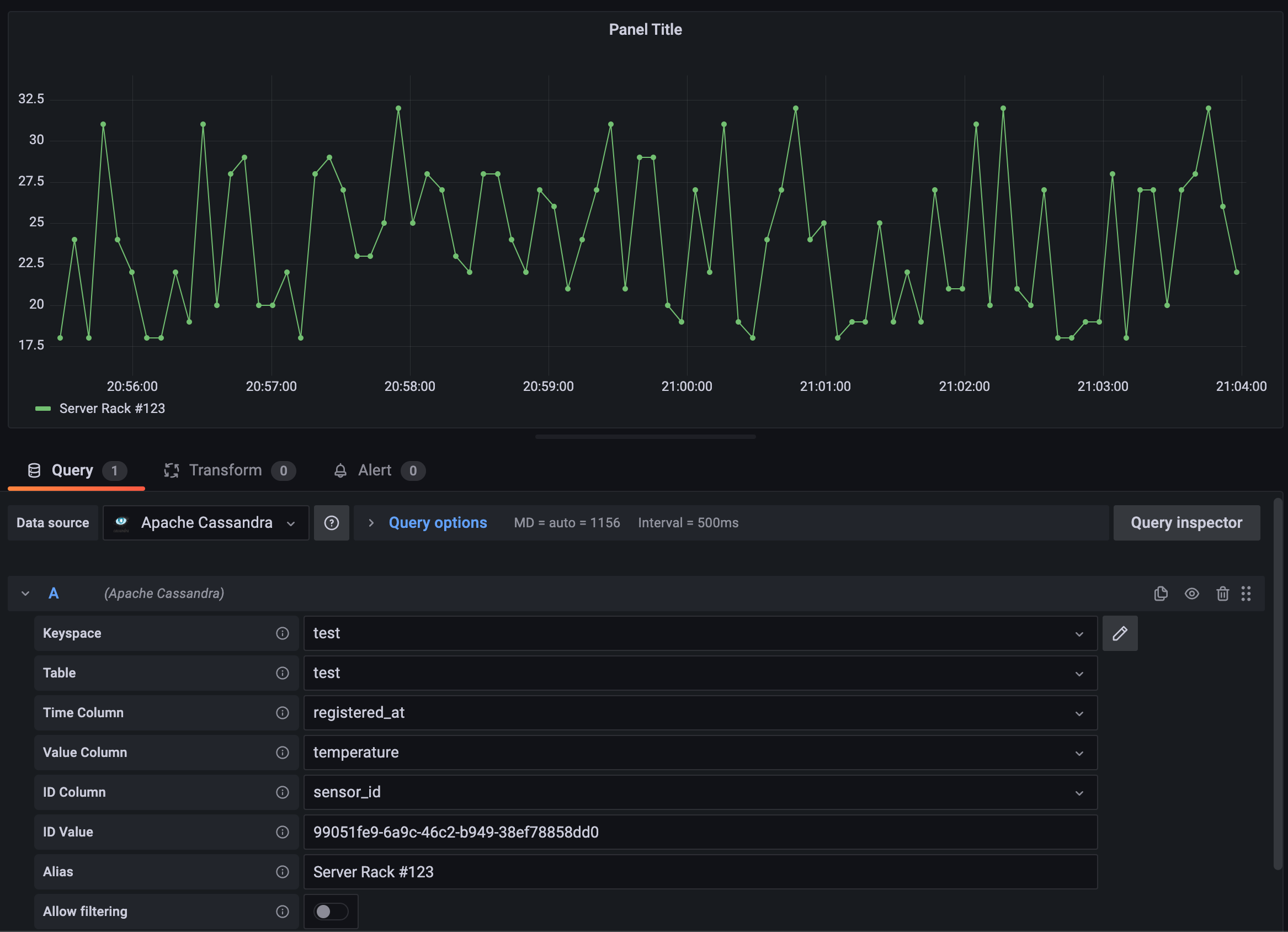
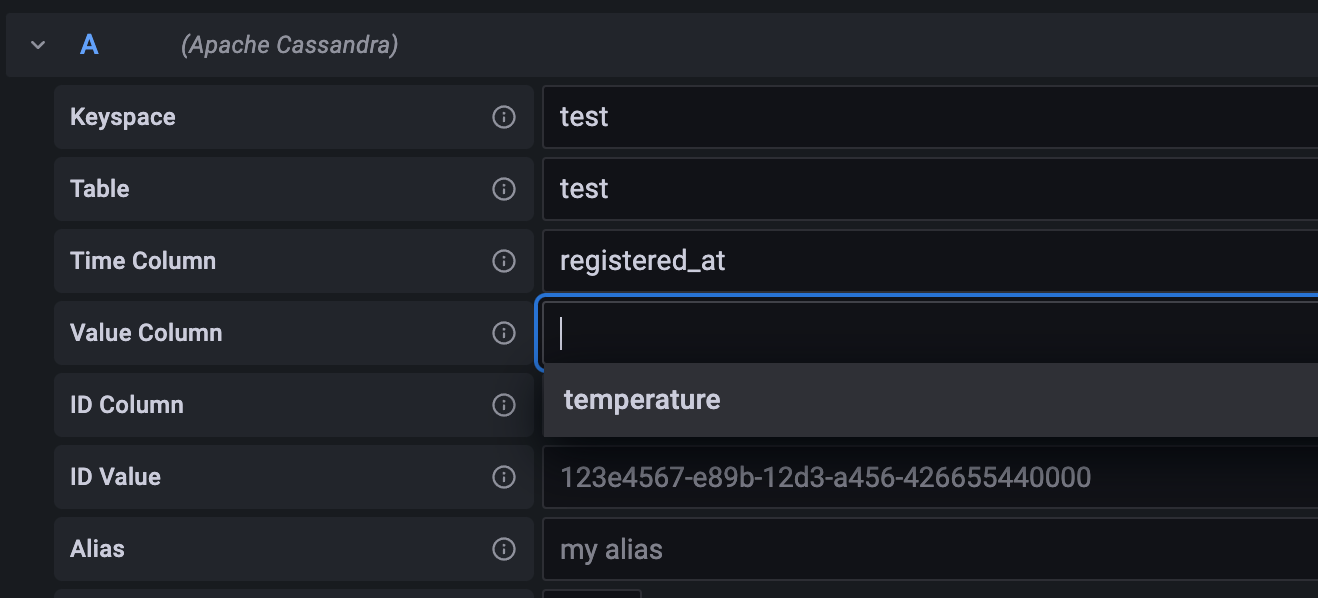
查询配置器是查询数据的最简单方式。首先输入 keyspace 和表名,然后选择合适的列。如果 keyspace 和表名输入正确,数据源将自动建议列名。
- 时间列 - 存储时间戳值的列,用于回答“何时”的问题。
- 值列 - 存储您希望显示的值的列。可以是
value、temperature或您需要的任何属性。 - ID 列 - 唯一标识数据来源的列,例如
sensor_id、shop_id或任何允许您识别数据来源的列。
之后,您必须指定 ID Value,即您想显示的数据来源的特定 ID。您可能需要启用 "ALLOW FILTERING",但我们建议避免使用它。
示例 假设您想可视化安装在家中的温度传感器的报告。由于传感器每分钟报告其 ID、时间、位置和温度,我们创建一个表来存储数据并将一些值放入其中
CREATE TABLE IF NOT EXISTS temperature ( sensor_id uuid, registered_at timestamp, temperature int, location text, PRIMARY KEY ((sensor_id), registered_at) );
insert into temperature (sensor_id, registered_at, temperature, location) values (99051fe9-6a9c-46c2-b949-38ef78858dd0, 2020-04-01T11:21:59.001+0000, 18, “kitchen”); insert into temperature (sensor_id, registered_at, temperature, location) values (99051fe9-6a9c-46c2-b949-38ef78858dd0, 2020-04-01T11:22:59.001+0000, 19, “kitchen”); insert into temperature (sensor_id, registered_at, temperature, location) values (99051fe9-6a9c-46c2-b949-38ef78858dd0, 2020-04-01T11:23:59.001+0000, 20, “kitchen”);
在这种情况下,为了获取结果,我们必须按如下方式填写配置器字段:
- Keyspace - smarthome(keyspace 名称)
- Table - temperature(表名)
- 时间列 - registered_at(发生时间)
- 值列 - temperature(要显示的值)
- ID 列 - sensor_id(数据来源的 ID)
- ID 值 - 99051fe9-6a9c-46c2-b949-38ef78858dd0 传感器的 ID
- ALLOW FILTERING - FALSE(非必需,所以我们很高兴避免)
如果有多个来源(多个传感器),您将需要添加更多行。如果您的用例如此简单,查询配置器将是一个不错的选择,否则请继续使用查询编辑器。
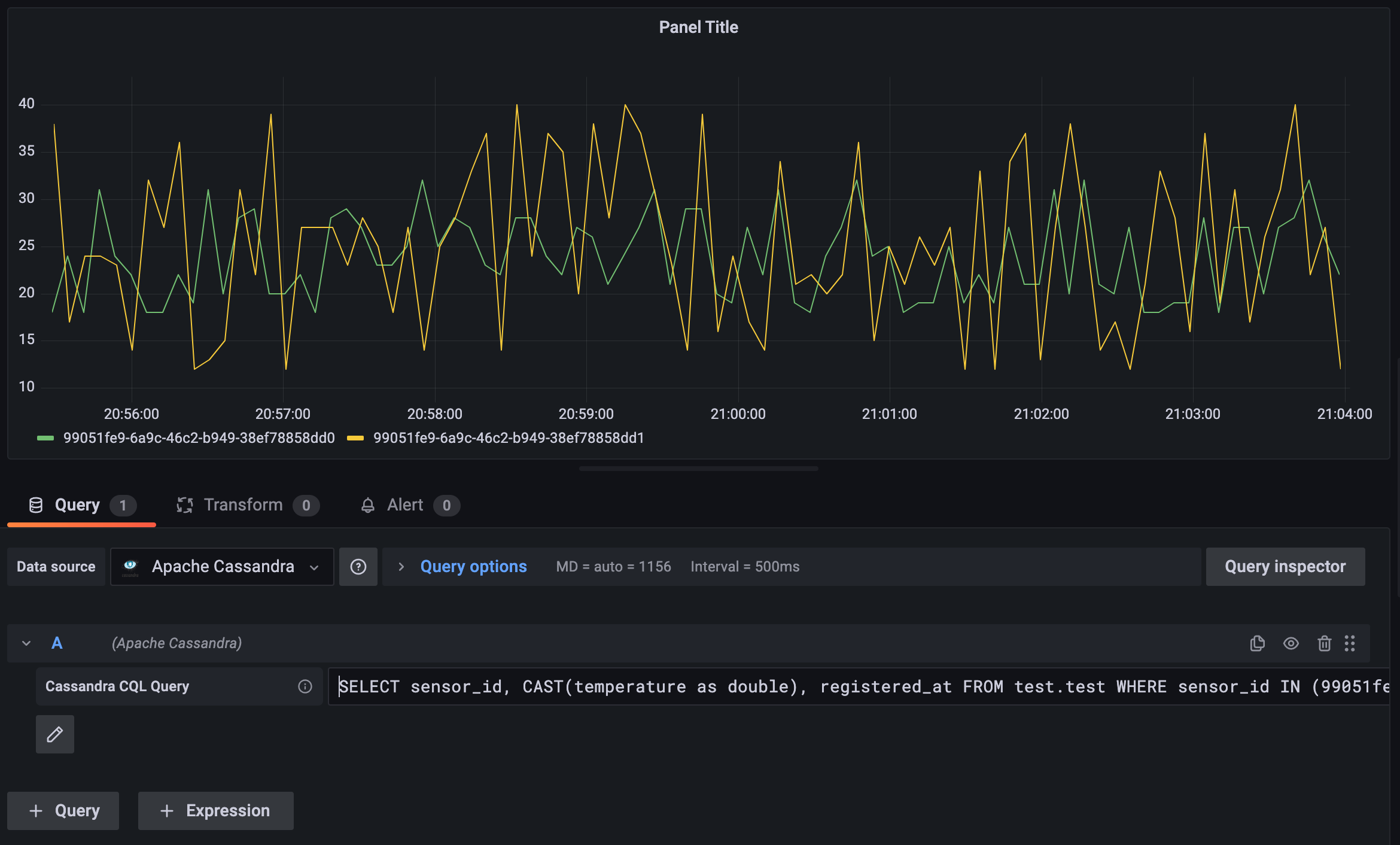
查询编辑器
查询编辑器是一种更强大的查询数据方式。要启用查询编辑器,请按下“切换文本编辑模式”按钮。

查询编辑器解锁了 CQL 的所有可能性,包括用户定义函数、聚合等。
示例(使用查询配置器案例中的示例表)
SELECT sensor_id, temperature, registered_at, location FROM test.test WHERE sensor_id IN (99051fe9-6a9c-46c2-b949-38ef78858dd1, 99051fe9-6a9c-46c2-b949-38ef78858dd0) AND registered_at > $__timeFrom and registered_at < $__timeTo
- SELECT 表达式中字段的顺序无关紧要,除了 ID 字段。此字段用于区分不同的时间序列,因此将其或任何其他基数较低的列放在第一个位置很重要。
- 标识符 - SELECT 表达式中的第一个属性应该是 ID,即唯一标识数据的内容(例如
sensor_id) - 值 - 如果查询结果将用于绘制图表,则返回的字段中应至少有一个数值。
- 时间戳 - 如果查询结果将用于绘制图表,则应有一个时间戳值。
- 可以有任意数量的附加字段,但是在使用多个数值字段时要小心,因为 Grafana 将它们解释为值并因此绘制在时间序列图表上。
- 查询返回的任何字段都可在 Alias 模板中使用,例如
{{ location }}。数据源会插值这些字符串并更新图表图例。 - 数据源将尝试保留所有字段,但并非总是可能,因为 Cassandra 和 Grafana 支持不同的类型集。不支持的字段将从响应中移除。
- 要按时间过滤数据,请在示例中使用
$__timeFrom和$__timeTo占位符。数据源将用面板中的时间值替换它们。注意,添加占位符很重要,否则查询将尝试获取整个时间段的数据。不要尝试自行指定时间范围,只需放入占位符即可。指定时间限制是 Grafana 的任务。

表格模式
除了时间序列模式,数据源还支持表格模式,使用 Cassandra 查询结果绘制表格。使用 Merge、Sort by、Organize fields 和其他转换,以任何所需的方式塑造表格。有两种方式绘制的不是整个时间序列,而是只有最近(最新)值。
- 低效方式
如果表是使用默认升序排序创建的,则最新值始终存储在分区的末尾。要检索它,查询中必须使用 ORDER BY 和 LIMIT 子句
SELECT sensor_id, temperature, registered_at, location
FROM test.test
WHERE sensor_id = 99051fe9-6a9c-46c2-b949-38ef78858dd0
AND registered_at > $__timeFrom and registered_at < $__timeTo
ORDER BY registered_at
LIMIT 1
请注意,WHERE IN () 子句不能与 ORDER BY 一起使用,因此对于任何额外的 sensor_id,查询必须重复。
- 高效方式
要高效地查询最新值,必须在创建表时指定排序
CREATE TABLE IF NOT EXISTS temperature (
sensor_id uuid,
registered_at timestamp,
temperature int,
location text,
PRIMARY KEY ((sensor_id), registered_at)
) WITH CLUSTERING ORDER BY (registered_at DESC);
之后,最新值将始终存储在分区的开头,只需使用 LIMIT 子句即可查询
SELECT sensor_id, temperature, registered_at, room_name
FROM test.test
WHERE sensor_id IN (99051fe9-6a9c-46c2-b949-38ef78858dd0, 99051fe9-6a9c-46c2-b949-38ef78858dd0)
AND registered_at > $__timeFrom AND registered_at < $__timeTo
PER PARTITION LIMIT 1
请注意,这里使用 PER PARTITION LIMIT 1 代替 LIMIT 1,以查询每个分区的一行,而不是总共一行。
变量
注释
告警
支持告警,但有一些限制。Grafana 在告警中不支持长(窄)序列,因此在将查询结果传递给 Grafana 之前,必须将其转换为宽序列。数据源以一种相当简单的方式执行此操作 - 它使用所有非时间序列字段创建标签,然后从响应中删除这些字段。基本上,此查询(使用示例表)
SELECT sensor_id, temperature, registered_at, location
FROM test.test
WHERE sensor_id IN (99051fe9-6a9c-46c2-b949-38ef78858dd0, 99051fe9-6a9c-46c2-b949-38ef78858dd0)
AND registered_at > $__timeFrom AND registered_at < $__timeTo
将生成两个用于告警的宽序列
99051fe9-6a9c-46c2-b949-38ef78858dd0 {location="kitchen", sensor_id="99051fe9-6a9c-46c2-b949-38ef78858dd0"} 99051fe9-6a9c-46c2-b949-38ef78858dd1 {location="bedroom", sensor_id="99051fe9-6a9c-46c2-b949-38ef78858dd1"}
关于序列类型的更多信息,请参阅Grafana 开发者文档。
提示与技巧
Unix 时间戳格式
通常没有问题 - Cassandra 可以使用不同的格式存储时间戳,如文档所示。然而,这并非总是足够的。一种可能的情况是 Unix 时间,它只是秒或毫秒的数字,通常存储为整数类型。
- 如果时间以毫秒数的形式存储在
bigint列中,那么在将数据返回给 Grafana 之前,应将其转换为timestamp类型
SELECT sensor_id, temperature, dateOf(maxTimeuuid(registered_at)), location
FROM test.test WHERE sensor_id = 99051fe9-6a9c-46c2-b949-38ef78858dd0
AND registered_at > $__timeFrom AND registered_at < $__timeTo
即使时间存储为毫秒数,此查询也会返回正确的时间戳。
- 如果时间以秒数的形式存储,则无法原生将其转换为时间戳,但有一个技巧
SELECT sensor_id, temperature, dateOf(maxTimeuuid(registered_at*1000)), location
FROM test.test WHERE sensor_id = 99051fe9-6a9c-46c2-b949-38ef78858dd0
AND registered_at > $__unixEpochFrom AND registered_at < $__unixEpochTo
- 此查询中有两个重要部分
dateOf(maxTimeuuid(registered_at*1000))用于将秒转换为毫秒(registered_at*1000),然后将毫秒转换为timestamp类型,再将其传递给 Grafana。$__unixEpochFrom和$__unixEpochTo是以秒为单位的 Unix 时间变量,用于填充查询的条件部分。
Cassandra 胖分区
Cassandra 将数据存储在**分区**中,分区是数据库的最小存储单元。这意味着使用示例表
CREATE TABLE IF NOT EXISTS temperature (
sensor_id uuid,
registered_at timestamp,
temperature int,
PRIMARY KEY ((sensor_id), registered_at)
);
将导致分区膨胀和性能下降,因为特定 sensor_id 的所有时间数据都存储在一个分区中(PRIMARY KEY 的第一部分是 PARTITION KEY)。为了避免这种情况,有一种称为**分桶 (bucketing)** 的技术,它基本上意味着将分区分割成更小的块。例如,我们可以按时间分割示例表的分区:年、月、日,甚至小时或更小的时间单位。选择哪种方式取决于每个分区存储多少数据。为了实现这一点,示例表必须修改成这样
CREATE TABLE IF NOT EXISTS temperature (
sensor_id uuid,
date date,
registered_at timestamp,
temperature int,
PRIMARY KEY ((sensor_id, date), registered_at)
);
修改后,由于按日期进行分桶,数据库模式变得更加高效,查询将采用以下形式
SELECT sensor_id, temperature, registered_at
FROM temperature
WHERE sensor_id IN (99051fe9-6a9c-46c2-b949-38ef78858dd1, 99051fe9-6a9c-46c2-b949-38ef78858dd0)
AND date = '${__from:date:YYYY-MM-DD}'
AND registered_at > $__timeFrom
AND registered_at < $__timeTo
请注意,这里使用了 $__from 和 $__to 变量。它们是 Grafana 内置变量,它们具有格式化能力,非常适合我们的用例。如果时间范围包含多天,则每天都必须添加到 AND date IN (...) 条件中。另一种更方便的方式是考虑使用更大的分桶,例如按月而不是按天分桶。
开发
在 Grafana Cloud 上安装 Apache Cassandra
在 Grafana Cloud 实例上安装插件是一键操作;更新也一样。很酷吧?
请注意,可能需要最多 1 分钟插件才会显示在您的 Grafana 中。
在 Grafana Cloud 实例上安装插件是一键操作;更新也一样。很酷吧?
请注意,可能需要最多 1 分钟插件才会显示在您的 Grafana 中。
在 Grafana Cloud 实例上安装插件是一键操作;更新也一样。很酷吧?
请注意,可能需要最多 1 分钟插件才会显示在您的 Grafana 中。
在 Grafana Cloud 实例上安装插件是一键操作;更新也一样。很酷吧?
请注意,可能需要最多 1 分钟插件才会显示在您的 Grafana 中。
在 Grafana Cloud 实例上安装插件是一键操作;更新也一样。很酷吧?
请注意,可能需要最多 1 分钟插件才会显示在您的 Grafana 中。
在 Grafana Cloud 实例上安装插件是一键操作;更新也一样。很酷吧?
请注意,可能需要最多 1 分钟插件才会显示在您的 Grafana 中。
在 Grafana Cloud 实例上安装插件是一键操作;更新也一样。很酷吧?
请注意,可能需要最多 1 分钟插件才会显示在您的 Grafana 中。
有关更多信息,请访问有关插件安装的文档。
在本地 Grafana 上安装
对于本地实例,插件通过简单的 CLI 命令进行安装和更新。插件不会自动更新,但是当更新可用时,您会在 Grafana 中收到通知。
1. 安装数据源
使用 grafana-cli 工具从命令行安装 Apache Cassandra
grafana-cli plugins install 插件将安装到您的 grafana 插件目录中;默认目录为 /var/lib/grafana/plugins。更多关于 cli 工具的信息。
2. 配置数据源
从 Grafana 主菜单访问,新安装的数据源可以在“数据源”部分立即添加。
接下来,点击右上角的“添加数据源”按钮。该数据源将在类型选择框中可供选择。
要查看已安装数据源列表,请点击主菜单中的“插件”项。核心数据源和已安装数据源都将显示。
v2.0.0
重要提示 v2 不支持旧版 Grafana(任何版本低于 7.0)
- 添加了对 Grafana 8.x 的支持 (#89)
- 添加了告警功能 (#91)
- 添加了表格格式支持 (#66)
- 添加了别名功能 (#92)
- UX 查询编辑器改进 (#93)
感谢 @futuarmo 的所有贡献
v1.1.4
- 可配置的连接超时
- 可配置的 TLS 设置(允许/禁止自签名证书)
- UI 配置改进
- 前端依赖更新
v1.0.1
- 支持 linux ARM64 平台
- 更新了依赖项
v1.0.0 初始版本
- 初次实现