
插件 〉Azure Data Explorer 数据源

Azure Data Explorer 数据源
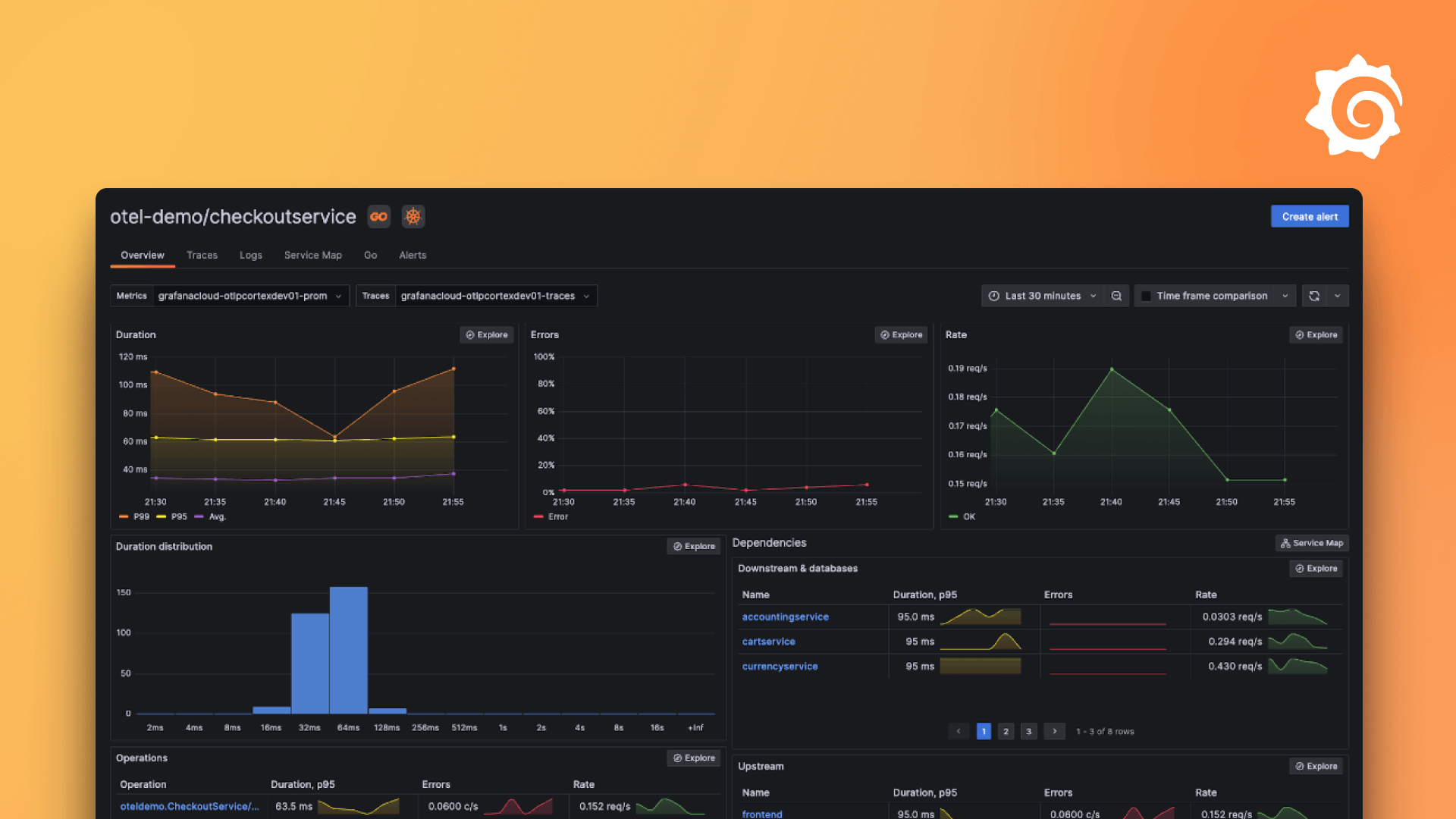
Grafana 的 Azure Data Explorer 数据源
Azure Data Explorer 是一个日志分析云平台,针对即席大数据查询进行了优化。
安装
此插件有以下最低要求
- v4.0.0+:Grafana 8.0.0
- v3.0.0+:Grafana 7.1.0
- < v3.0.0 需要 Grafana 6.3.6。
有关如何在 Grafana Cloud 或本地安装插件的详细说明,请查看插件安装文档。
强制执行可信 Azure Data Explorer 端点
为增加安全性,可以强制执行一个可信 ADX 端点列表,集群 URL 将对照此列表进行验证。这可以防止请求被重定向到第三方端点。
在 Grafana 配置文件的 `[plugin.grafana-azure-data-explorer-datasource]` 部分设置 `enforce_trusted_endpoints` 可以启用此功能。
[plugin.grafana-azure-data-explorer-datasource]
enforce_trusted_endpoints = true
配置 Azure Data Explorer 数据源
配置 ADX 以使用此数据源:
- 创建 Azure Active Directory (AAD) 应用程序和 AAD 服务主体。
- 在 Azure Data Explorer WebExplorer 中,将 AAD 应用程序连接到 Azure Data Explorer 数据库用户。
- 使用 AAD 应用程序在 Grafana 中配置数据源连接。
- (可选) 若要在创建查询时使用下拉集群选择器,请向包含集群的订阅授予读取者访问权限。
创建 Azure Active Directory 服务主体
有关如何设置可以访问资源的 Microsoft Entra 应用程序和服务主体的详细说明,请遵循 Microsoft 的此指南:创建可以访问资源的 Microsoft Entra 应用程序和服务主体
创建 AAD 应用程序的另一种方法是使用 Azure CLI。有关 Azure CLI 命令的更多信息,请参阅az ad sp create-for-rbac
az ad sp create-for-rbac -n "http://url.to.your.grafana:3000"
这应该返回以下内容:
{
"appId": "XXXXXXXX-XXXX-XXXX-XXXX-XXXXXXXXXXXX",
"displayName": "azure-cli-2018-09-20-13-42-58",
"name": "http://url.to.your.grafana:3000",
"password": "XXXXXXXX-XXXX-XXXX-XXXX-XXXXXXXXXXXX",
"tenant": "XXXXXXXX-XXXX-XXXX-XXXX-XXXXXXXXXXXX"
}
将读取者角色分配给服务主体并移除贡献者角色
az role assignment create --assignee <your appId> --role Reader
az role assignment delete --assignee <your appId> --role Contributor
将 AAD 连接到 Azure Data Explorer 用户
上面创建的 AAD 应用程序需要被授予对您的 Azure Data Explorer 数据库的查看者访问权限(在本例中数据库名为 Grafana)。这可以通过使用点命令 `add` 来完成。`.add` 的参数包含由分号分隔的客户端 ID 和租户 ID。
.add database Grafana viewers ('aadapp=<your client id>;<your tenantid>')
包含客户端/应用程序 ID 和租户 ID 的实际示例:
.add database Grafana viewers ('aadapp=377a87d4-2cd3-44c0-b35a-8887a12fxxx;e7f3f661-a933-4b3f-8176-51c4f982exxx')
如果命令成功,您应该会看到类似这样的结果:

配置 Grafana
通过填写以下字段添加数据源:
| 字段 | 描述 |
|---|---|
| 目录(租户)ID | (Azure Active Directory -> 属性 -> 目录 ID) |
| 应用程序(客户端)ID | (Azure Active Directory -> 应用注册 -> 选择您的应用 -> 应用程序 ID) |
| 客户端密钥 | (Azure Active Directory -> 应用注册 -> 选择您的应用 -> 密钥) |
| 默认集群 | (选项) 如果创建查询时未选择集群,将使用默认集群。 |
附加设置
附加设置是可选设置,可以配置以更好地控制您的数据源。通过展开数据源配置页面底部的附加设置部分可以访问附加设置。
| 字段 | 描述 |
|---|---|
| 查询超时 | 此值控制客户端查询超时。 |
| 使用动态缓存 | 启用此功能后,Grafana 将按查询动态应用缓存设置,并忽略默认缓存最大有效期。时间序列查询的 bin size 将用于扩大时间范围并作为缓存最大有效期。 |
| 缓存最大有效期 | 默认情况下,缓存是禁用的。如果需要启用查询缓存,请指定缓存的最大存活时间范围。 |
| 数据一致性 | 查询一致性控制查询和更新如何同步。默认为强一致性 (Strong)。更多信息请参阅查询一致性 |
| 默认编辑器模式 | 此设置决定编辑器将以何种模式打开。默认为可视化 (Visual)。 |
| 默认数据库 | 如果未选择数据库,将使用默认数据库。选择默认数据库需要一个默认集群。要加载默认数据库选项,必须使用有效的 Azure 连接保存数据源。 |
| 使用托管 schema | 如果启用,表、函数和物化视图将映射到用户友好的名称。 |
| 向主机发送用户名头部 | 启用此功能后,Grafana 在向 ADX 发送请求时,将在 `x-ms-user-id` 头部和 `x-ms-client-request-id` 头部中传递登录用户的用户名。这在 ADX 中需要进行追踪时会很有用。 |
配置 On-Behalf-Of 身份验证(Beta 版)
{{% admonition type="caution" */%}} 此功能为 Beta 版,可能存在破坏性变更 {{%/* /admonition %}}
有关设置和使用 OBO 流程的信息,请参阅on-behalf-of 文档
查询数据源
在查询数据源之前,选择查询头部选项:集群、数据库和格式。您可以使用查询构建器、KQL 或 OpenAI 创建查询。
查询头部
集群
选择要查询的集群。如果数据源设置中设置了默认集群,则会自动填充集群选择器。如果没有集群可供选择,请参阅配置 Azure Data Explorer 数据源
数据库
选择要查询的数据库。如果数据源设置中设置了默认数据库,则会自动填充数据库选择器。
格式化为
使用“格式化为”下拉选择器,查询可以格式化为表格 (Table)、时间序列 (Time Series)、追踪 (Trace) 或 ADX 时间序列 (ADX time series) 数据。
表格 (Table) 查询主要用于表格面板 (Table panel),显示为列和行的列表。此示例查询返回具有六个指定列的行:
AzureActivity | where $__timeFilter() | project TimeGenerated, ResourceGroup, Category, OperationName, ActivityStatus, Caller | order by TimeGenerated desc时间序列 (Time series) 查询用于图形面板 (Graph Panel)(以及像单一状态面板 (Single Stat panel) 这样的其他面板)。查询必须精确包含一个 datetime 列、一个或多个数值列,并且可选包含一个或多个字符串列作为标签。时间列也应按升序排列。这是一个示例查询,它返回按 Category 列和小时分组的聚合计数:
AzureActivity | where $__timeFilter(TimeGenerated) | summarize count() by Category, bin(TimeGenerated, 1h) | order by TimeGenerated asc数值列被视为指标,可选字符串列被视为标签。对于每个值列 + 一组唯一的字符串列值,都会返回一个时间序列。每个序列的名称格式为 valueColumnName {stringColumnName=columnValue, ... }。
例如,以下查询将生成类似 `AvgDirectDeaths {EventType=Excessive Heat, State=DELAWARE}``EventCount {EventType=Excessive Heat, State=NEW JERSEY}` 的序列。
StormEvents | where $__timeFilter(StartTime) | summarize EventCount=count(), AvgDirectDeaths=avg(DeathsDirect) by EventType, State, bin(StartTime, $__timeInterval) | order by StartTime asc追踪 (Trace) 格式选项可用于使用内置的追踪可视化功能显示适当格式的数据。要使用此可视化功能,数据必须按照此处定义的 schema 呈现。该 schema 包含 `logs`、`serviceTags` 和 `tags` 字段,它们应为 JSON 对象。如果 ADX 中的 schema 与以下内容匹配,这些字段将被转换为期望的数据结构:
- `logs` - 具有一个数值 `timestamp` 字段和一个键值对象 `fields` 字段的 JSON 对象数组。
- `serviceTags` 和 `tags` - 没有嵌套对象的典型键值 JSON 对象。
键的值应为基本类型而非复杂类型。为空时传递的正确值应为 `null`,或者对于 `serviceTags` 和 `tags` 为空 JSON 对象,对于 `logs` 为空数组。
ADX 时间序列 (ADX time series) 用于使用 Kusto `make-series` 运算符的查询。查询必须精确包含一个名为 `Timestamp` 的 datetime 列,以及至少一个值列。还可以选择包含作为标签的字符串列。
示例
let T = range Timestamp from $__timeFrom to ($__timeTo + -30m) step 1m | extend Person = dynamic(["Torkel", "Daniel", "Kyle", "Sofia"]) | extend Place = dynamic(["EU", "EU", "US", "EU"]) | mvexpand Person, Place | extend HatInventory = rand(5) | project Timestamp, tostring(Person), tostring(Place), HatInventory;T | make-series AvgHatInventory=avg(HatInventory) default=double(null) on Timestamp from $__timeFrom to $__timeTo step 1m by Person, Place | extend series_decompose_forecast(AvgHatInventory, 30) | project-away *residual, *baseline, *seasonal
查询构建器
| 字段 | 描述 |
|---|---|
| 表 | 选择一个表。 |
| 列 | 选择列的子集以获得更快的结果。时间序列需要时间和数值;其他列呈现为维度。有关维度的更多信息,请参阅时间序列维度。 |
| 过滤器 | (可选) 为选定的列添加过滤器。过滤器的值将限于列的数据类型。 |
| 聚合 | (可选) 为选定的列添加聚合。从下拉菜单中选择聚合类型,并选择要聚合的列。 |
| 分组依据 | (可选) 为选定的列添加分组依据。对于时间分组依据,选择一个时间范围桶。 |
| 时间偏移 (已废弃,请在查询选项中使用 grafana 时间偏移) | (可选) 按预定的持续时间偏移 Grafana 宏生成的时间范围。 |
查询构建器中支持 `dynamic` 类型的列。这包括数组、JSON 对象以及数组中的嵌套对象。一个限制是仅查询前 50,000 行的数据,因此构建器选择器中只会列出包含在前 50,000 行中的属性作为选项。如果默认不显示其他值,可以手动写入不同的选择器中。此外,由于这些查询使用了 `mv-expand`,它们可能会消耗大量资源。
有关通过 KQL 编辑器正确处理动态列的更多详细信息,请参阅以下文档。
Kusto 数据类型 - 有关 Kusto 支持的数据类型的文档。
Dynamic 数据类型 - 有关 dynamic 数据类型的详细文档。
使用 Kusto 查询语言 (KQL) 查询
查询使用 Kusto 查询语言编写;有关更多信息,请参阅Kusto 查询语言 (KQL) 概述。
OpenAI 查询生成器
{{% admonition type="note" */%}} 您必须启用 LLM 插件才能使用此功能。{{%/* /admonition %}}
LLM 插件可以在LLM 应用中安装。安装插件后,请启用它。
要使用查询生成器,请键入关于您想查看的数据的语句或问题,然后点击生成查询 (Generate query)。在生成的查询 (Generated query) 字段中查看和编辑生成的 KQL 查询。对查询满意后,点击运行查询 (Run query) 运行查询。
时间宏
为了更轻松地编写查询,可以在查询的 `where` 子句中使用一些 Grafana 宏:
- `$__timeFilter()` - 展开为 `TimeGenerated ≥ datetime(2018-06-05T18:09:58.907Z) and TimeGenerated ≤ datetime(2018-06-05T20:09:58.907Z)`,其中起始和结束时间取自 Grafana 时间选择器。
- `$__timeFilter(datetimeColumn)` - 展开为 `datetimeColumn ≥ datetime(2018-06-05T18:09:58.907Z) and datetimeColumn ≤ datetime(2018-06-05T20:09:58.907Z)`,其中起始和结束时间取自 Grafana 时间选择器。
- `$__timeFrom` - 展开为 `datetime(2018-06-05T18:09:58.907Z)`,即查询的开始时间。
- `$__timeTo` - 展开为 `datetime(2018-06-05T20:09:58.907Z)`,即查询的结束时间。
- `$__timeInterval` - 展开为 `5000ms`,这是 Grafana 根据查询的时间范围推荐的 bin size(以毫秒为单位)。在告警中,这将始终为 `1000ms`,建议不要在告警查询中使用此宏。
模板宏
`$__escapeMulti($myVar)` - 用于包含非法字符的多值模板变量。如果 $myVar 的值为 `'\\grafana-vm\Network(eth0)\Total','\\hello!'`,它会展开为:`@'\\grafana-vm\Network(eth0)\Total', @'\\hello!'`。如果使用单值变量,则无需此宏,只需直接在行内转义变量即可 - `@'\$myVar'`。
`$__contains(colName, $myVar)` - 用于多值模板变量。如果 $myVar 的值为 `'value1','value2'`,它会展开为:`colName in ('value1','value2')`。
如果使用“全部”(`All`) 选项,请勾选“包含全部选项”(`Include All Option`) 复选框,并在“自定义全部值”(`Custom all value`) 字段中键入以下值:`all`。如果 $myVar 的值为 `all`,则宏将展开为 `1 == 1`。对于有很多选项的模板变量,这可以通过不构建一个大的 where..in 子句来提高查询性能。
使用变量进行模板化
您可以在指标查询中使用变量,而不是硬编码服务器、应用程序和传感器名称等内容。变量在仪表盘顶部显示为下拉选择框。这些下拉菜单可以轻松更改仪表盘中显示的数据。
在仪表盘设置中创建变量。通常,您需要编写 KQL 查询来获取下拉列表的值列表。不过,也可以使用硬编码的值列表。
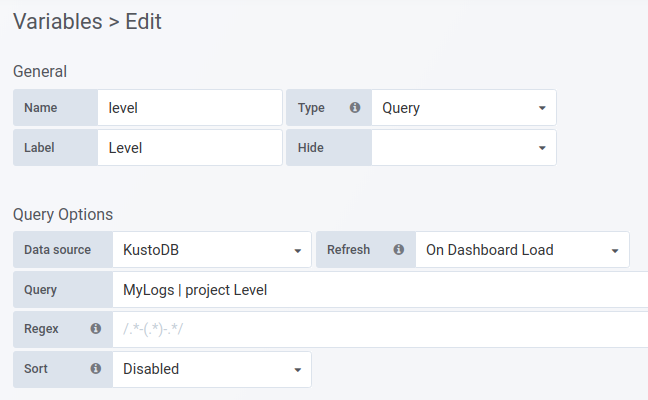
为您的变量填写名称。`Name` 字段是变量的名称。还有一个 `Label` 字段用于友好名称。
在查询选项 (Query Options) 部分,在数据源 (Data source) 下拉列表中选择 `Azure Data Explorer` 数据源。
在查询 (Query) 字段中编写查询。使用 `project` 指定一个列 - 结果应为字符串值列表。
在底部,您将看到查询返回值的预览:
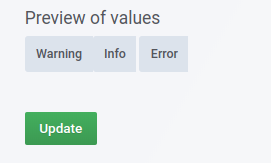
在查询中使用变量(在本例中变量名为 `level`):
MyLogs | where Level == '$level'对于允许多个值的变量,请使用 `in` 运算符代替:
MyLogs | where Level in ($level)
在Grafana 文档中阅读更多关于模板化和变量的信息。
数据库变量
无法使用 Kusto 查询语言获取数据库列表。在按使用变量进行模板化部分所述创建模板变量时,请在查询 (Query) 字段中使用以下函数返回数据库列表:
databases()
此变量可以在数据库下拉菜单中使用。这使您无需编辑面板中的查询即可切换数据库。
要使用变量,请在下拉菜单中键入变量的名称。例如,如果变量名称为 `database`,则键入 `$database`。
注解
注解是叠加在图表上方的事件。查询每行最多可以有三列,其中 datetime 列是必需的。注解渲染成本较高,因此限制返回的行数非常重要。
- datetime 类型的列。
- 带有别名 Text 或 text 的列,用于注解文本。
- 带有别名 Tags 或 tags 的列,用于注解标签。这应该返回一个逗号分隔的标签字符串,例如 'tag1,tag2'。
示例查询
MyLogs
| where $__timeFilter(Timestamp)
| project Timestamp, Text=Message , Tags="tag1,tag2"
了解更多
在 Grafana Cloud 上安装 Azure Data Explorer 数据源
在 Grafana Cloud 实例上安装插件是一键安装的;更新也是一样。很酷,对吧?
请注意,插件可能需要最多 1 分钟才能在您的 Grafana 中显示。
在 Grafana Cloud 实例上安装插件是一键安装的;更新也是一样。很酷,对吧?
请注意,插件可能需要最多 1 分钟才能在您的 Grafana 中显示。
在 Grafana Cloud 实例上安装插件是一键安装的;更新也是一样。很酷,对吧?
请注意,插件可能需要最多 1 分钟才能在您的 Grafana 中显示。
在 Grafana Cloud 实例上安装插件是一键安装的;更新也是一样。很酷,对吧?
请注意,插件可能需要最多 1 分钟才能在您的 Grafana 中显示。
在 Grafana Cloud 实例上安装插件是一键安装的;更新也是一样。很酷,对吧?
请注意,插件可能需要最多 1 分钟才能在您的 Grafana 中显示。
在 Grafana Cloud 实例上安装插件是一键安装的;更新也是一样。很酷,对吧?
请注意,插件可能需要最多 1 分钟才能在您的 Grafana 中显示。
在 Grafana Cloud 实例上安装插件是一键安装的;更新也是一样。很酷,对吧?
请注意,插件可能需要最多 1 分钟才能在您的 Grafana 中显示。
更多信息,请访问插件安装文档。
在本地 Grafana 上安装
对于本地实例,插件通过简单的 CLI 命令安装和更新。插件不会自动更新,但您会在 Grafana 中收到更新通知。
1. 安装数据源
使用 grafana-cli 工具从命令行安装 Azure Data Explorer 数据源:
grafana-cli plugins install 插件将安装到您的 grafana 插件目录;默认路径为 /var/lib/grafana/plugins。CLI 工具的更多信息。
2. 配置数据源
从 Grafana 主菜单访问,新安装的数据源可以立即在数据源 (Data Sources) 部分添加。
接下来,点击右上角的添加数据源 (Add data source) 按钮。该数据源将在类型 (Type) 选择框中可供选择。
要查看已安装数据源列表,请点击主菜单中的插件 (Plugins) 项。核心数据源和已安装数据源都会显示。
更新日志
[6.0.0]
- 添加加载指示器 #1210
- 提高最低 Grafana 版本到 10.4.0
- 依赖更新
[5.1.1]
[5.1.0]
- 支持使用 Shift+Enter 运行查询 #971
- 使用 grafana-azure-sdk-react 统一凭据 #1075
- 支持在数据源配置中设置 `application` 值 #1107
- 从 @grafana/experimental 迁移到 @grafana/plugin-ui #1168
- 依赖更新
[5.0.7]
[5.0.6]
- 添加 errorsource #996
- 依赖更新
[5.0.5]
[5.0.4]
- 修复:现在从上下文加载自定义云 #921
[5.0.3]
- 升级依赖
[5.0.2]
- 升级依赖
- 修复:重新添加一些旧版端点以兼容旧版本 Grafana。
- 修复:确保多选模板变量在查询构建器中正常工作。
[5.0.1]
- 升级依赖
- 修复:如果未指定,则将查询数据库设置为默认值 #863
[5.0.0]
- 破坏性变更:旧版查询编辑器已移除。adxLegacyEditor 功能开关将不再起作用。
- 移除对已弃用的 Grafana API 的引用。
- 依赖更新。
- 改进错误消息。
- 修复:绕过集群请求的可信端点强制执行。
[4.10.0]
- 功能:支持私有数据源连接(安全 socks 代理)。
- 功能:为 KQL 查询添加解释功能。
- 功能:添加日志可视化支持。
[4.9.0]
- 新功能:添加查询集群选择支持。
- 功能:添加通过 ESM 加载 Monaco Editor 的兼容性。
[4.8.0]
- 新功能:OpenAI:集成 LLM 插件
- 将 github.com/grafana/grafana-plugin-sdk-go 从 0.180.0 升级到 0.195.0
[4.7.1]
- 升级依赖
- 更新变量编辑器
[4.7.0]
- 新功能:添加对Workload Identity 身份验证的支持。
[4.6.3]
- 新功能:添加对在集群 URL 中仅强制执行已知 Azure Data Explorer 端点。
[4.6.2]
- 修复:QueryEditor 组件中的无限重新渲染。
[4.6.1]
- 修复:允许动态值在追踪中为空。
[4.6.0]
- 新功能:添加追踪数据和追踪可视化支持。
- 依赖更新。
- 修复:修复了阻止切换回 ADX 数据源的错误。
- 修复:使用生成查询功能时,现在会在尝试查询之前验证令牌。
- 修复:布尔值可以按 ADX 允许的方式表示为数字或 bool。
[4.5.0]
- 添加 OpenAI 集成,允许用户通过自然语言生成 KQL 查询。
- 实验性 - 添加对当前用户授权的支持。
[4.4.1]
使用最新的 Go 版本 1.20.4 构建
[4.4.0]
更新后端依赖
[4.3.0]
此版本改进了 Azure Data Explorer 模板变量的编辑器
- 新功能:为数据库、表和列添加了预定义查询,以简化模板变量的使用。
- 新功能:查询构建器和 KQL 编辑器都可用于查询模板变量。
- 新功能:Azure Data Explorer 模板变量查询现在支持宏和模板变量。
此版本还包括:
- 修复:在使用 KQL 编辑器时,ADX 时间序列格式现已保留。
- 修复:配置编辑器标签宽度现在一致。
- 修复:字段聚焦现在按预期工作。
- 重构:OBO 令牌提供程序使用可配置的中间件。
- 重构:已移除 Grafana 中已弃用的 metricFindQuery 函数以及其他 rxjs 函数。
[4.2.0]
此版本改进了插件查询构建器
- 新功能:现在可以在查询中过滤列,从而提高查询性能。
- 查询预览包含 Kusto 的语法高亮。
- 所有其他组件已重构以匹配最新的 Grafana UI。
除此之外,此版本还包括:
- 重构:身份验证和配置已重构以匹配其他 Azure 插件。
- 修复:配置 On-Behalf-Of 身份验证的数据源的健康检查。
- 修复:返回空数据的告警查询。
[4.1.10]
- 修复:对于不遵循语义版本控制的 Grafana 版本加载了无效的代码编辑器 (由 @aangelisc 在 https://github.com/grafana/azure-data-explorer-datasource/pull/506 中贡献)
- 修复卸载 ADX 查询编辑器时的错误 (由 @aangelisc 在 https://github.com/grafana/azure-data-explorer-datasource/pull/519 中贡献)
- 安全:构建过程中的 Go 版本升级到 1.19.3
[4.1.9]
- 安全:构建过程中的 Go 版本升级到 1.19.2
- 修复:Schema 映射显示宏函数
[4.1.8]
- 在仪表盘加载时报告交互以进行功能追踪
[4.1.7]
- 修复创建告警时崩溃的问题
- 自动补全现在支持动态值
- 修复包含括号的值的模板变量
[4.1.6]
- 更改动态列的默认逻辑:如果 schema 中存在类型,则转换为 double
[4.1.5]
- 修复:更改数据库时更新 KQL 表达式中的表。
[4.1.4]
- 更改默认格式为表格数据,以避免意外的高内存消耗。
- 修复:在查询构建器中引用包含空格的列。
[4.1.3]
- 修复:在查询构建器中正确转换动态类型的列。
[4.1.2]
此版本包含多个 bug 修复
- 修复配置中的重新加载 schema 按钮。
- 修复查询构建器中简单类型的动态解析。
- 修复构建器中“聚合”和“分组依据”的移除逻辑。
- 返回配置的默认数据库,而不是第一个数据库。
[4.1.1]
可视化查询构建器的多项 bug 修复
- 添加物化视图作为表。
- 修复模板变量引用问题。
- 修复具有多种类型的动态字段语法。
[4.1.0]
- 新功能:可视化查询编辑器现在支持 `dynamic` 列。这包括包含一个或多个 `dynamic` 值数组的列。
[4.0.2]
- Beta 功能的破坏性变更:On-Behalf-Of 流程现在默认为禁用
[4.0.1]
- Bug 修复:移除用于 On-Behalf-Of 流程 (Beta) 的自定义令牌缓存,并依赖 Microsoft 身份验证库维护本地缓存。
[4.0.0]
- 破坏性变更:Azure Data Explorer 插件现在需要 Grafana 8.0+ 才能运行。
- 破坏性变更:obo_latency_seconds 指标已移除。
- Bug 修复:包含了新的 Kusto 查询编辑器。注意:此新编辑器仅在使用 Grafana 8.5 或更高版本时可用。修复 #325。
- Bug 修复:从 Where/Aggregate/Group by 子句中过滤动态列,以防止语法错误。
- Bug 修复:在查询构建器中为 timespan 类型添加逻辑运算符。
- 内部:通过 Grafana Azure SDK 进行客户端密钥身份验证。
- 内部:通过 Go 的 MSAL 进行 OBO 身份验证。
[3.7.1]
- Bug 修复:修复国家云的 scope
[3.7.0]
- 杂项:添加了测试覆盖率脚本
[3.7.0-beta1]
- 功能:添加 On-Behalf-Of 令牌授权
- Bug 修复:消除客户端 ID Panic
- Bug 修复:将 azure 错误附加到查询失败消息
- Bug 修复:修复带有连字符的列上的宏正则表达式
- 内部:更新插件依赖
[3.6.1]
- 恢复了在 3.6.0 中所做的更改,并复用先前的代码编辑器,直到修复相关问题。
[3.6.0]
- 将自定义查询编辑器替换为 @grafana/ui 通用编辑器,支持 Kusto。
[3.5.1]
- Bug 修复:修复了 HTTP 超时设置未生效的问题
- Bug 修复:修复了在配置中手动输入与复制/粘贴客户端密钥时的问题
- Bug 修复:修复了注解查询未显示的问题
[3.5.0]
- 添加对国家云的支持
- 用调用资源处理程序替换插件代理路由
- 添加实例管理器、共享 http 客户端并使用新的令牌提供程序
[3.4.1]
- Bug 修复:修复配置页面加载 schema 时出现的错误。
[3.4.0]
注意:最低要求的 Grafana 版本现在是 7.4
- Bug 修复:修复了查询构建器无法处理包含特殊字符的表名的问题
- Bug 修复:修复了清除后空 WHERE 行保留在查询构建器中的问题
- 模板变量现在可以在其他模板变量的查询中使用。
[3.3.2]
- Bug 修复:修复了当 Grafana 从子路径提供服务时 KQL Monaco 编辑器无法加载的问题
- Bug 修复:修复了模板查询变量不工作的问题
[3.3.1]
- Bug 修复:在设置跟踪头部之前检查 plugincontext 用户是否为 nil
[3.3.0]
- 通过将登录的 Grafana 用户名作为头部传递给 ADX 来添加跟踪功能
- 使用 jsoniter 代替 encoding/json 以提高性能
- Bug 修复:在构建查询之前展开查询模板变量
- Bug 修复:修复确认对话框中的小拼写错误
本项目的所有重要更改都将记录在此文件中。
[3.2.1]
- 锁定 grafana-packages 版本并升级工具包。
[3.2.0]
- 添加了对 decimal 数据类型的支持。
- 移除了全局查询限制,以防止数据被截断。
- 改进了可视化查询构建器,使其更易于向查询添加聚合。
- 添加了对处理 schema 映射的支持,以过滤掉可视化查询构建器中可用的数据库 schema 部分。
- Bug 修复:防止创建仪表盘时触发空查询。
- Bug 修复:修复在编辑器处于原始模式时正确选择 ADX 时间序列选项的问题。
- Bug 修复:添加了超时设置,并确保插件正确处理长时间运行查询的超时。
[3.1.0]
- 全局查询限制现在可在数据源设置中配置。
- 自动补全在搜索可能的值时将包含其他过滤器。
- 添加了 !has 和 has_any 运算符。
- 添加数据源设置以在新创建查询时设置默认视图。
- 添加了动态缓存,以启用按查询设置缓存。
- 列名不会将精确匹配排序在顶部。
- 支持自动补全的列现在会在键入之前预填充选项。
- 添加了执行时间偏移查询的支持。
- 为聚合添加了 dcount() 运算符。
- Bug 修复:操作符描述现在更宽,更易读。
- Bug 修复:将模板变量显示为选项。
- Bug 修复:从查询中排除空/缺失的操作符。
- Bug 修复:没有 group-by 的聚合不工作。
- Bug 修复:时间间隔偏差 1000ms。
[3.0.5]
- Bug 修复:在可视化编辑器中为表或数据库选择模板变量时,值未正确设置。现在应该已修复。
[3.0.4]
- Bug 修复:可视化编辑器现在在数据库选择器中包含模板变量。
[3.0.3]
- Bug 修复:当数据源凭据无效时显示正确的错误消息。
- Bug 修复:可视化编辑器现在支持动态列中的时间字段。
[3.0.2]
- Bug 修复:修复了更改数据源时 schema 未更新的问题。
- 提高了加载表 schema 时的性能。
- 提高了自动补全搜索时的性能。
[3.0.1]
- 支持可视化查询编辑器中的值自动补全。
- 支持可视化查询编辑器中的动态列。动态字段会自动从表 schema 中读取,并在构建查询时可供选择。值自动补全也适用于动态列。
- 现有仪表盘的迁移脚本。
- 自动补全和动态列功能的性能改进。
- 提高了加载表 schema 时的性能。
[3.0.0]
- 添加了对新的可视化查询编辑器的支持。
- 将现有查询编辑器移植到 React。
[2.1.0]
- 添加了对用于模板变量查询的 databases() 宏的支持,并且数据库变量可以在查询编辑器中的数据库下拉菜单中使用。这允许用户无需编辑查询即可切换数据库。
[2.0.6]
- v7 的签名插件
[2.0.5]
- Bug 修复,针对问题 #61。这是一个临时修复,因为适当的修复需要重构部分后端。
[2.0.4]
- Bug 修复,针对问题 #73
[2.0.3]
- Monaco 加载器的 Bug 修复
[2.0.2]
- Bug 修复,针对问题 #60
- 更新了软件包
[2.0.1]
- 向插件添加键值支持(基于 mysql 插件)
- 指标命名和别名的新功能
[2.0.0]
- 时间序列查询现在支持告警。
- 时间序列查询现在支持多个数值列和多个字符串列。
- 使用 Kusto `make-series` 运算符创建的 Kusto“时间序列”类型现已支持。
- 已添加宏,以避免与 Grafana 内置的查询宏冲突:$__timeFrom、$__timeTo 和 $__timeInterval。
- 已移除表格和时间序列查询的缓存,直到后端插件支持缓存。
- 查询不再在没有 ORDER by 子句时附加它,但是如果时间序列未排序,查询编辑器中会有警告。
[1.3.2] - 2019-06-19
- Bug 修复,针对问题 #8
- 更新了软件包
- 添加了 circleci
v1.3.0
- 如果查询中未指定 ORDER by 子句,则添加一个。它使用 from 子句或 summarize...bin() 中的 datetime 字段。
- 从配置页面移除了 Subscription Id 字段,因为不再需要它。
v1.2.0
- 添加了缓存配置选项。默认的内存缓存周期是 30 秒,新的“最小缓存周期”选项允许您更改它。
v1.1.0
- 添加了 $__escapeMulti 宏
v1.0.0
- Azure Data Explorer 数据源的第一个版本。