
MongoDB 模板和变量
您可以使用变量,而不是在指标查询中硬编码服务器、应用和传感器名称等详细信息。Grafana 在面板顶部的下拉选择框中列出这些变量,帮助您更改面板中显示的数据。**模板**是任何包含变量的查询。
有关模板和变量的介绍,请参阅以下文档
要添加新的 MongoDB 查询变量,请参阅添加和管理变量。使用 MongoDB 作为您的数据源。
以下是检索 1980 年后所有电影标题的示例查询
sample_mflix.movies.aggregate([
{"$match": {year: {"$gt": 1980}}},
{"$project": {"_id": 0, "movie_title": "$title"}}
])复合变量
MongoDB 支持**复合**变量,其中单个变量代表多个值,以实现复杂的多键过滤。
复合变量使用指南
- 命名: 每个独立名称以一个下划线 (_) 开头,并使用下划线连接。避免空格。示例:
_var1_var2。 - 查询: 使用别名,其中独立名称用连字符 (-) 分隔。示例:
val1-val2。 - 引用: 使用标准变量语法调用您的变量。示例:
$_var1或$_var2。
示例:按电影名称和年份过滤结果
创建一个变量并将其命名为
_movie_year。选择 MongoDB 作为数据源。
使用以下查询检索包含单个 movie-year 属性的项目数组
sample_mflix.movies.aggregate([ {"$match": {year: {"$gt": 1980}}}, {"$project": {"_id": 0, "movie_year": {"$concat": ["$title", " - ", {"$toString":"$year"}]}}} ]) // [{"movie-year": "Ted - 2016"}, {"movie-year": "The Terminator - 1985"}]在您的查询中将
$_movie和$_year作为单独的模板变量引用sample_mflix.movies.find({"title":"$_movie", year: $_year})在您的 MongoDB 查询中使用该变量,并采用适当的变量语法。
使用即时过滤器
除了任何名称的标准即时过滤器类型变量外,您必须创建第二个辅助变量。它应该是一个 constant 类型变量,名称为 mongo_adhoc_query,其值与查询编辑器兼容。查询结果将填充 UI 的可选过滤器。由于此变量没有其他用途,您可以选择将其隐藏起来。
除了标准的即时过滤器变量(任何名称均可)之外,您还必须创建第二个辅助变量。此辅助变量应满足以下条件:
- 为
constant类型 - 命名为
mongo_adhoc_query - 其值与查询编辑器兼容。
查询结果将填充 UI 的可选过滤器。由于此变量没有其他用途,您可以选择将其隐藏起来。
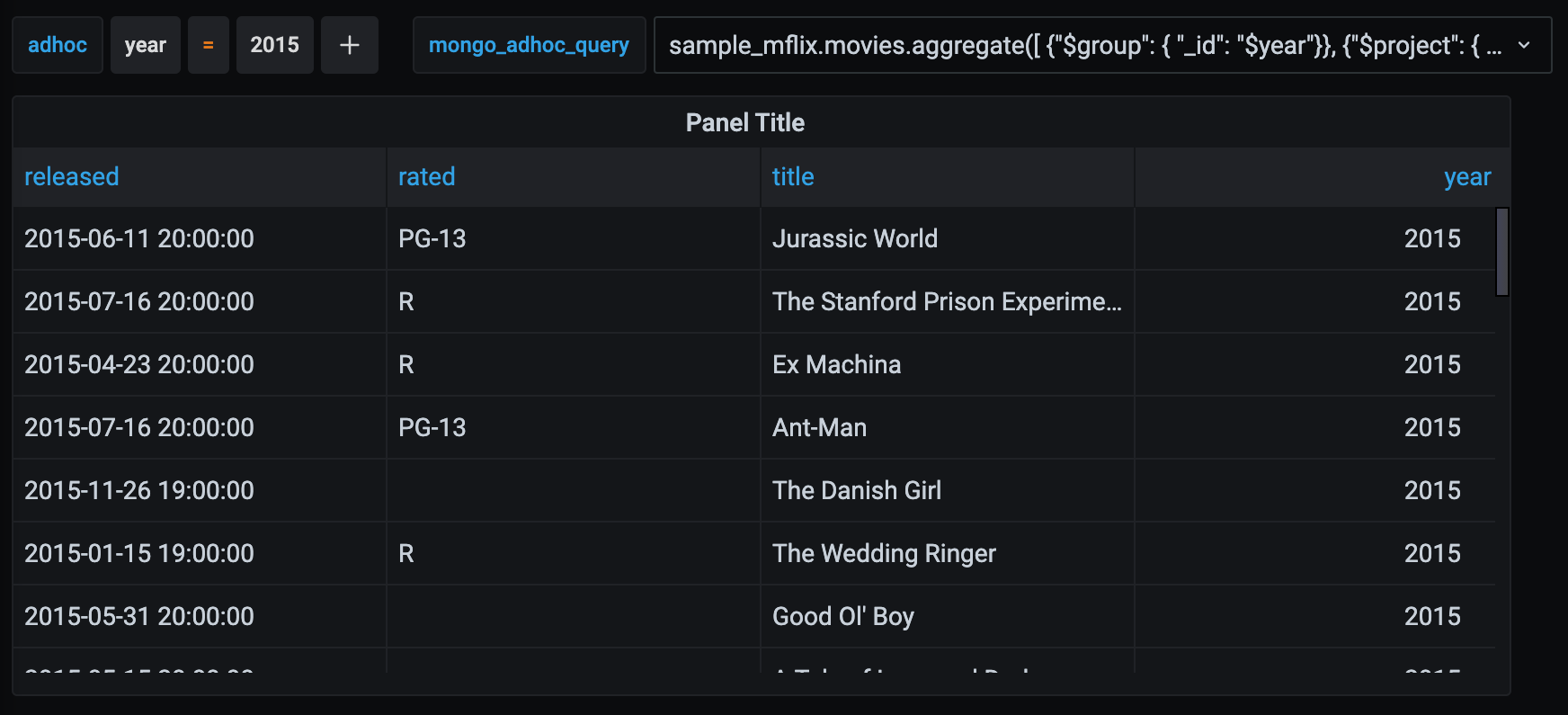
请考虑以下查询
sample_mflix.movies.aggregate([ {"$group": { "_id": "$year"}}, {"$project": { "year": "$_id", "_id": 0 }} ] )添加选定值后,输出如下所示
其他支持的功能
支持以下功能,并提供示例查询
- 支持
ObjectId类型
sample_mflix.movies.find({"_id": ObjectId("573a1390f29313caabcd4803")})
sample_mflix.movies.find({"_id": {$in : [ObjectID("573a1391f29313caabcd6f98"), ObjectID("573a1392f29313caabcd9dee"), ObjectID("573a1392f29313caabcd9ca6")] }})支持 Regex 搜索
- 使用双引号
sample_mflix.movies.find({"title": {$regex: "ace", $options: "$i"} })- 使用单引号
sample_mflix.movies.find({"title": {$regex: 'ace', $options: "$i"} })- 使用模式
sample_mflix.movies.find({"title": /ace/i })支持
$__timeFrom/$__timeTo宏
sample_mflix.movies.find({"tomatoes.dvd": { $gt: $__timeFrom}}).limit(10)
sample_mflix.movies.find({ $and: [{ "tomatoes.dvd": { $gte: $__timeFrom }}, { "tomatoes.dvd": { $lt: $__timeTo }}]})- 支持
ISODate类型
sample_mflix.movies.find({"tomatoes.dvd": { $gte: ISODate("2013-03-01") }})
sample_mflix.movies.find({"tomatoes.dvd": { $gte: ISODate(1719600176123) }})
sample_mflix.movies.find({"tomatoes.dvd": { $gte: ISODate("2024-07-04T13:06:55Z") }})
sample_mflix.movies.find({"tomatoes.dvd": { $gte: ISODate() }})- 支持
new Date类型
sample_mflix.movies.find({"tomatoes.dvd": { $gte: new Date("2013-03-01") }})
sample_mflix.movies.find({"tomatoes.dvd": { $gte: new Date(1719600176123) }})
sample_mflix.movies.find({"tomatoes.dvd": { $gte: new Date("2024-07-04T13:06:55Z") }})
sample_mflix.movies.find({"tomatoes.dvd": { $gte: new Date() }})- 支持
Date日期字符串类型
sample_mflix.movies.find({"tomatoes.dvd": { $gte: Date("2013-03-01") }})
sample_mflix.movies.find({"tomatoes.dvd": { $gte: Date(1719600176123) }})
sample_mflix.movies.find({"tomatoes.dvd": { $gte: Date("2024-07-04T13:06:55Z") }})
sample_mflix.movies.find({"tomatoes.dvd": { $gte: Date() }})- 支持 "
$$NOW" 日期字符串类型
sample_mflix.movies.find({"tomatoes.dvd": { $gte: "$$NOW" } }})- 支持
Date.now()时间戳(自 Unix 纪元以来的毫秒数)类型
sample_mflix.movies.find({"tomatoes.dvd": { $gte: Date.now() } }})从版本 1.21.0 开始,插件支持 Date.now() 后的基本算术运算。例如,可用于获取 15 秒前的时间戳
sample_mflix.movies.find({"tomatoes.dvd": { $gte: Date.now() - 15 * 1000, $lt: Date.now() } }})调试响应大小
调试响应大小是指分析和排查系统返回响应的大小,这有助于识别性能问题以及数据被截断或丢失的问题。
注意
Grafana Cloud 目前不支持调试响应大小功能。
GF_PLUGIN_LOGGER_LEVEL 可以配置为环境变量或在 grafana.ini 配置文件中配置,示例如下
[plugin.grafana-mongodb-datasource]
# the log level to capture
# either 1 (traces) or 2 (debug) will work
logger_level = 2每次查询后,MongoDB 插件会记录有关响应大小的信息。
本页面是否有帮助?
来自 Grafana Labs 的相关资源


