转换数据
转换是操纵查询返回数据的一种强大方式,可在系统应用可视化之前进行。使用转换,您可以
- 重命名字段
- 连接时间序列/类 SQL 数据
- 跨查询执行数学运算
- 将一个转换的输出用作另一个转换的输入
对于依赖于同一数据集多个视图的用户,转换提供了一种创建和维护大量仪表盘的高效方法。
您还可以将一个转换的输出用作另一个转换的输入,这将带来性能提升。
有时系统无法绘制转换后的数据图表。发生这种情况时,点击可视化上方的
表格视图开关,切换到数据的表格视图。这可以帮助您了解转换的最终结果。
转换类型
Grafana 提供了多种转换数据的方式。有关完整的转换列表,请参阅转换函数。
转换顺序
当存在多个转换时,Grafana 会按照它们列出的顺序应用。每个转换都会创建一个结果集,该结果集随后传递给处理管道中的下一个转换。
Grafana 应用转换的顺序直接影响结果。例如,如果您使用 Reduce 转换将一列的所有结果浓缩为一个单一值,那么您只能对该单一值应用转换。
转换中的仪表盘变量
转换中的所有文本输入字段都接受变量语法
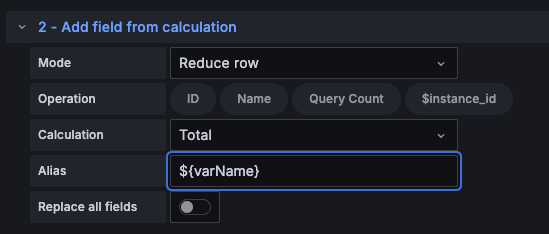
在转换中使用仪表盘变量时,变量会在转换应用于数据之前自动插值。
有关示例,请参阅按名称过滤字段转换中的使用仪表盘变量。
向数据添加转换函数
以下步骤指导您向数据添加转换。本文档不包含每种转换类型的步骤。有关完整的转换列表,请参阅转换函数。
- 导航到要添加一个或多个转换的面板。
- 将鼠标悬停在面板的任意部分,以显示右上角的动作菜单。
- 点击菜单并选择 编辑。
- 点击转换选项卡。
- 点击一个转换。将出现一个转换行,您可以在其中配置转换选项。有关如何配置转换的更多信息,请参阅转换函数。有关可用计算的信息,请参阅计算类型。
- 要应用另一个转换,请点击添加转换。此转换作用于前一个转换返回的结果集。
![Transform tab in the panel editor]()
调试转换
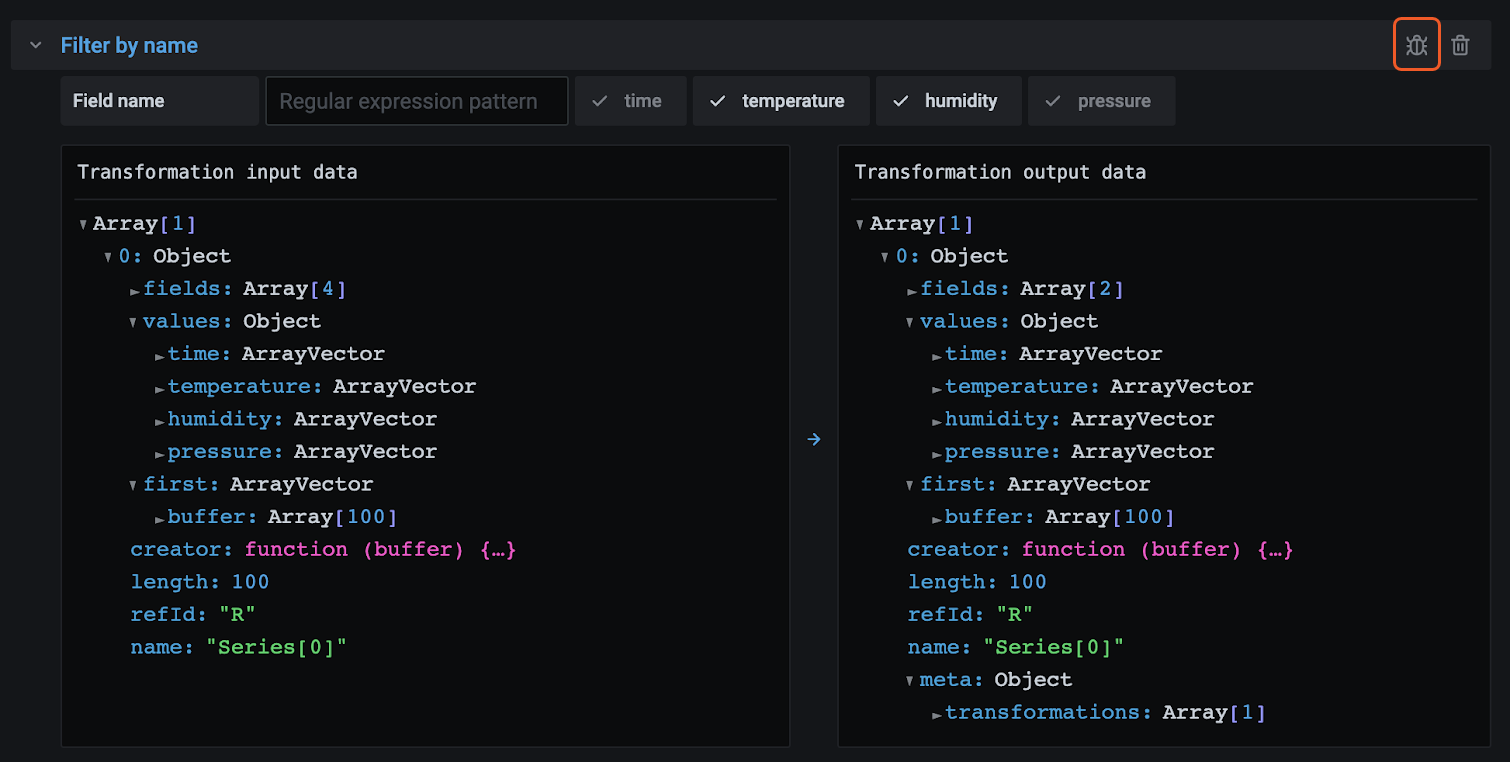
要查看转换的输入和输出结果集,请点击转换行右侧的 bug 图标。
输入和输出结果集可以帮助您调试转换。
禁用转换
您可以点击转换行右上角的眼睛图标来禁用或隐藏一个或多个转换。这将禁用该特定转换的应用操作,并有助于识别您连续更改多个转换时出现的问题。

过滤转换
如果您的面板使用多个查询,您可以过滤这些查询并将选定的转换仅应用于其中一个查询。为此,请点击转换行右上角的过滤图标。这将打开一个下拉列表,其中包含面板上使用的查询列表。在此处,您可以选择要转换的查询。
您还可以按注解(包括 exemplars)进行过滤,以便对其应用转换。执行此操作时,字段列表会更改以反映注解或 exemplar 工具提示中的字段。
如果您的面板有多个查询或数据源(即面板或注解数据),过滤图标始终显示,但如果应用了合并查询输出的先前转换,它可能不起作用。这是因为一个转换会接收前一个转换的输出。
删除转换
建议您移除不需要的转换。删除转换后,您将从可视化中移除数据。
开始之前
- 识别所有依赖于此转换的仪表盘,并通知受影响的仪表盘用户。
删除转换的步骤:
- 打开面板进行编辑。
- 点击转换选项卡。
- 点击要删除的转换旁边的垃圾桶图标。

转换函数
您可以对数据执行以下转换。
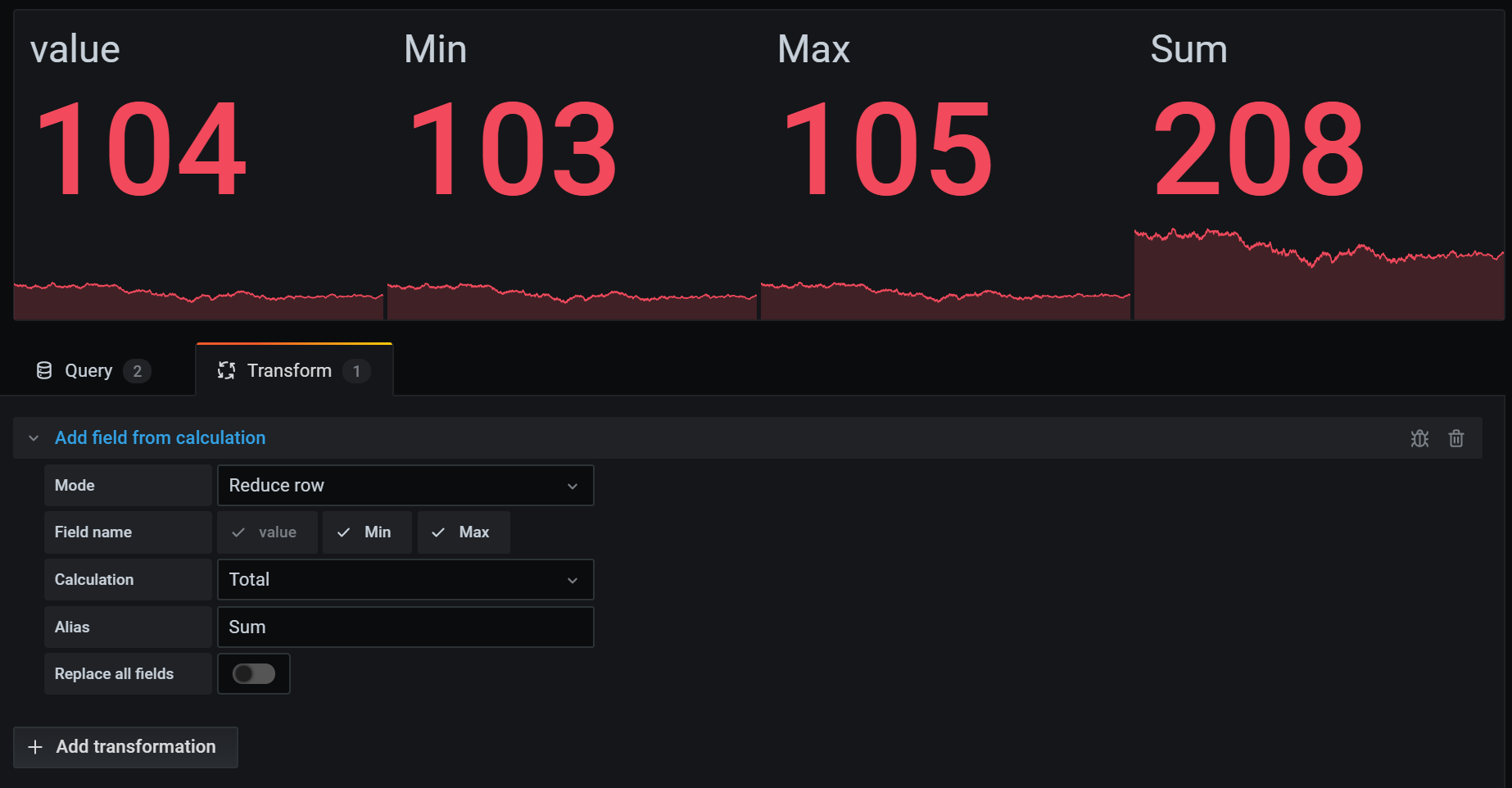
从计算添加字段
使用此转换添加一个由其他两个字段计算出的新字段。每个转换允许您添加一个新字段。
- 模式 - 选择一种模式
- 行归约 - 独立地对选定字段的每一行应用选定的计算。
- 二元运算 - 对来自两个选定字段的单行中的值应用基本二元运算(例如,求和或相乘)。
- 一元运算 - 对来自选定字段的单行中的值应用基本一元运算。可用操作包括
- 绝对值 (abs) - 返回给定表达式的绝对值。它表示其与零的距离,为一个正数。
- 自然指数 (exp) - 返回 e 的给定表达式次幂。
- 自然对数 (ln) - 返回给定表达式的自然对数。
- 向下取整 (floor) - 返回小于或等于给定表达式的最大整数。
- 向上取整 (ceil) - 返回大于或等于给定表达式的最小整数。
- 累积函数 - 对当前行和所有先前行应用函数。
- 总计 - 计算包括当前行在内的累积总计。
- 平均值 - 计算包括当前行在内的平均值。
- 窗口函数 - 应用窗口函数。窗口可以是尾随或居中。对于尾随窗口,当前行将是窗口中的最后一行。对于居中窗口,窗口将以当前行为中心。对于偶数大小的窗口,窗口将以当前行和前一行之间为中心。
- 平均值 - 计算移动平均值或滑动平均值。
- 标准差 - 计算移动标准差。
- 方差 - 计算移动方差。
- 行索引 - 插入一个包含行索引的字段。
- 字段名称 - 选择要用于新字段计算的字段名称。
- 计算 - 如果您选择行归约模式,则会出现计算字段。点击该字段查看可用于创建新字段的计算选项列表。有关可用计算的信息,请参阅计算类型。
- 操作 - 如果您选择二元运算或一元运算模式,则会出现操作字段。这些字段允许您对来自选定字段的单行中的值应用基本数学运算。您也可以对二元运算使用数值。
- 所有数值字段 - 将二元运算的左侧设置为对所有数值字段应用计算。
- 作为百分位 - 如果您选择行索引模式,则会出现作为百分位开关。此开关允许您将行索引转换为总行数的百分比。
- 别名 - (可选)输入新字段的名称。如果留空,则字段将根据计算结果命名。
- 替换所有字段 - (可选)如果要隐藏所有其他字段并在可视化中仅显示计算出的字段,请选择此选项。
在下面的示例中,我们将两个字段相加并将其命名为 Sum。
连接字段
使用此转换将所有帧中的所有字段合并为一个结果。
例如,如果您有两个独立的查询分别获取温度和正常运行时间数据(查询 A)以及空气质量指数和错误信息(查询 B),应用连接转换会生成一个合并的数据帧,其中包含在一个视图中所有相关信息。
考虑以下情况
查询 A
| 温度 | 正常运行时间 |
|---|---|
| 15.4 | 1230233 |
查询 B
| AQI | 错误 |
|---|---|
| 3.2 | 5 |
连接字段后,数据帧将是
| 温度 | 正常运行时间 | AQI | 错误 |
|---|---|---|---|
| 15.4 | 1230233 | 3.2 | 5 |
此转换简化了合并来自不同来源数据的过程,为分析和可视化提供了全面的视图。
从查询结果获取配置
使用此转换选择一个查询并提取标准选项,例如 Min、Max、Unit 和 Thresholds,并将其应用于其他查询结果。此功能可根据特定查询返回的数据实现动态可视化配置。
选项
- 配置查询 - 选择返回要用作配置的数据的查询。
- 应用于 - 选择应应用配置的字段或序列。
- 应用于选项 - 根据您在应用于中的选择,指定字段类型或使用字段名称正则表达式。
字段映射表
在配置选项下方,您将找到字段映射表。此表列出了配置查询返回的数据中找到的所有字段,以及 Use as 和 Select 选项。它提供了对字段到配置属性映射的控制,对于多行,它允许您选择要选择哪个值。
示例
输入[0] (来自查询: A, 名称: ServerA)
| 时间 | 值 |
|---|---|
| 1626178119127 | 10 |
| 1626178119129 | 30 |
输入[1] (来自查询: B)
| 时间 | 值 |
|---|---|
| 1626178119127 | 100 |
| 1626178119129 | 100 |
输出 (与 Input[0] 相同,但现在在 Value 字段上应用了配置)
| 时间 | 值 (配置: 最大值=100) |
|---|---|
| 1626178119127 | 10 |
| 1626178119129 | 30 |
源数据中的每一行都成为一个单独的字段。现在每个字段都有一个最大配置选项集。Min、Max、Unit 和 Thresholds 等选项是字段配置的一部分。如果设置了这些选项,可视化将使用它们,而不是在面板编辑器选项窗格中手动配置的任何选项。
值映射
您还可以将查询结果转换为值映射。使用此选项,配置查询结果中的每一行都定义一个单独的值映射行。请参阅以下示例。
配置查询结果
| 值 | 文本 | 颜色 |
|---|---|---|
| L | 低 | 蓝色 |
| M | 中 | 绿色 |
| H | 高 | 红色 |
在字段映射中指定
| 字段 | 用作 | 选择 |
|---|---|---|
| 值 | 值映射 / 值 | 所有值 |
| 文本 | 值映射 / 文本 | 所有值 |
| 颜色 | 值映射 / 颜色 | 所有值 |
Grafana 从您的查询结果构建值映射,并将其应用于真实数据查询结果。您应该会看到值根据配置查询结果进行映射和着色。
注意: 当您使用此转换设置阈值时,可视化将继续使用面板的基本阈值。
转换字段类型
使用此转换修改指定字段的字段类型。
此转换具有以下选项
- 字段 - 从可用字段中选择
- 转换为 - 选择要转换到的字段类型 (FieldType)
- 数值 - 尝试将值转换为数字
- 字符串 - 将值转换为字符串
- 时间 - 尝试将值解析为时间
- 输入将按照 Moment.js 解析格式 进行解析
- 它将把数值输入解析为以毫秒为单位的 Unix epoch 时间戳。如果您的输入是以秒为单位,则必须将其乘以 1000。
- 将显示一个选项,允许您通过字符串(例如 yyyy-mm-dd 或 DD MM YYYY hh:mm:ss)指定输入日期格式 (DateFormat)
- 布尔值 - 将值转换为布尔值
- 枚举 - 将值转换为枚举
- 将显示一个表格来管理枚举
- 其他 - 尝试将值解析为 JSON
例如,考虑以下查询,通过将时间字段选为 Time 并将日期格式指定为 YYYY,可以对其进行修改。
示例查询
| 时间 | 标记 | 值 |
|---|---|---|
| 2017-07-01 | 上方 | 25 |
| 2018-08-02 | 下方 | 22 |
| 2019-09-02 | 下方 | 29 |
| 2020-10-04 | 上方 | 22 |
结果
转换后的查询
| 时间 | 标记 | 值 |
|---|---|---|
| 2017-01-01 00:00:00 | 上方 | 25 |
| 2018-01-01 00:00:00 | 下方 | 22 |
| 2019-01-01 00:00:00 | 下方 | 29 |
| 2020-01-01 00:00:00 | 上方 | 22 |
此转换允许您灵活地调整数据类型,确保可视化中的兼容性和一致性。
提取字段
使用此转换选择一个数据源并以不同的格式从中提取内容。此转换具有以下字段
- 源 - 选择数据源的字段。
- 格式 - 选择以下之一
- JSON - 从源解析 JSON 内容。
- 键值对 - 从源中解析格式为 'a=b' 或 'c:d' 的内容。
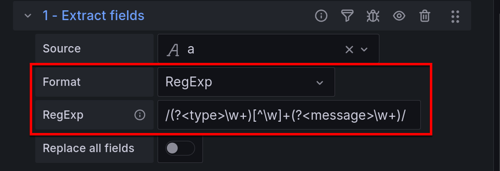
- 正则表达式 - 使用带有 命名捕获组(例如
/(?<NewField>.*)/)的正则表达式解析内容。![Example of a regular expression]()
- 自动 - 自动发现字段。
- 替换所有字段 - (可选)选择此选项以隐藏所有其他字段,并在可视化中仅显示计算出的字段。
- 保留时间 - (可选)仅在替换所有字段为 true 时可用。在输出中保留时间字段。
考虑以下数据集
数据集示例
| 时间戳 | json_data |
|---|---|
| 1636678740000000000 | {“value”: 1} |
| 1636678680000000000 | {“value”: 5} |
| 1636678620000000000 | {“value”: 12} |
您可以使用此配置准备数据,供时间序列面板使用
- 源: json_data
- 格式: JSON
- 字段: value
- 别名: my_value
- 替换所有字段: true
- 保留时间: true
这将生成以下输出
转换后的数据
| 时间戳 | my_value |
|---|---|
| 1636678740000000000 | 1 |
| 1636678680000000000 | 5 |
| 1636678620000000000 | 12 |
此转换允许您以各种方式提取和格式化数据。您可以根据特定数据需求自定义提取格式。
从资源查找字段
使用此转换通过从外部源查找附加字段来丰富字段值。
此转换具有以下字段
- 字段 - 从您的数据集中选择一个文本字段。
- 查找 - 从国家、美国州和机场中选择。
此转换目前支持空间数据。
例如,如果您有以下数据
数据集示例
| 位置 | 值 |
|---|---|
| AL | 0 |
| AK | 10 |
| 亚利桑那 | 5 |
| 阿肯色 | 1 |
| 某个地方 | 5 |
使用此配置
- 字段: location
- 查找: 美国州
您将获得以下输出
转换后的数据
| 位置 | ID | 名称 | 经度 | 纬度 | 值 |
|---|---|---|---|---|---|
| AL | AL | 阿拉巴马 | -80.891064 | 12.448457 | 0 |
| AK | AK | 阿肯色 | -100.891064 | 24.448457 | 10 |
| 亚利桑那 | 5 | ||||
| 阿肯色 | 1 | ||||
| 某个地方 | 5 |
此转换允许您通过从外部源获取附加信息来增强数据,为分析和可视化提供更全面的数据集。
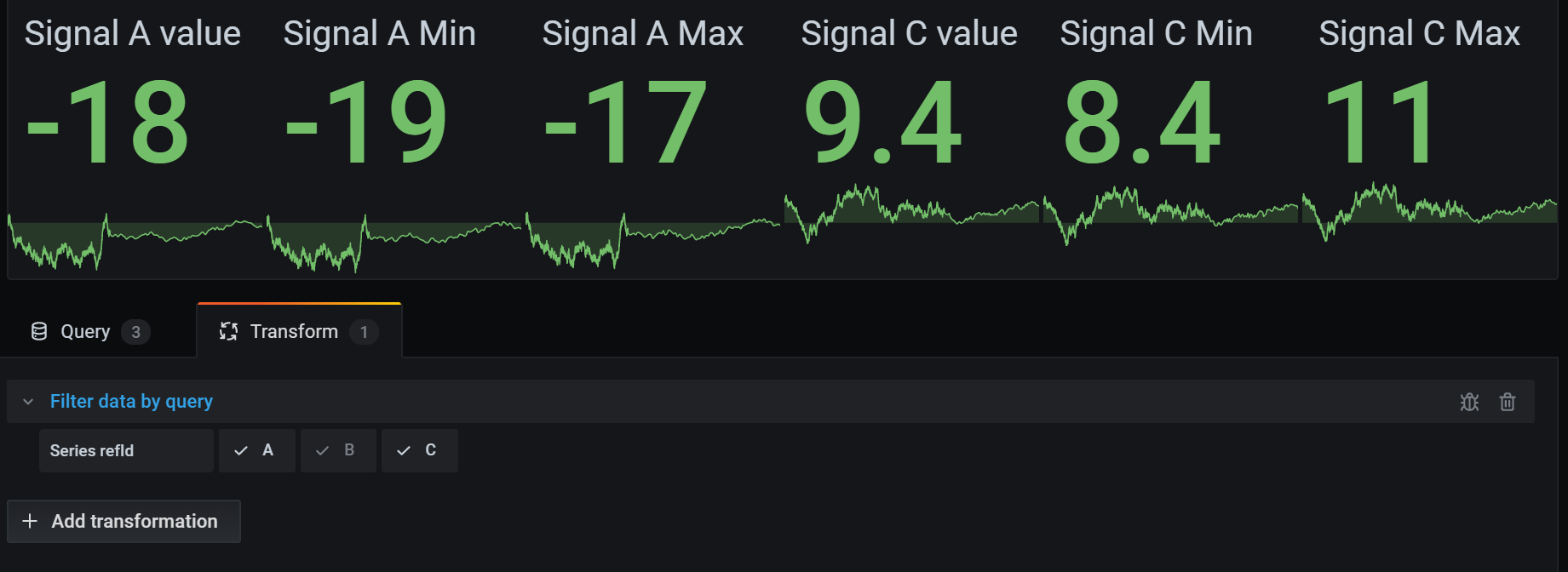
按查询 refId 过滤数据
使用此转换隐藏具有多个查询的面板中的一个或多个查询。
Grafana 以深灰色文本显示查询标识字母。点击查询标识符以切换过滤。如果查询字母为白色,则显示结果。如果查询字母为深色,则隐藏结果。
注意: 此转换不适用于 Graphite,因为此数据源不支持将返回数据与查询关联。
在下面的示例中,面板包含三个查询(A、B、C)。我们从可视化中移除了查询 B。
按值过滤数据
使用此转换直接在可视化中选择性地过滤数据点。此转换提供了根据应用于所选字段的一个或多个条件来包含或排除数据的选项。
如果您的数据源不支持原生按值过滤,此转换将非常有用。如果您使用的是共享查询,您也可以使用此转换来缩小显示的值范围。
所有字段的可用条件有
- 正则表达式 - 匹配一个正则表达式。
- 为空 - 如果值为 null 则匹配。
- 不为空 - 如果值不为 null 则匹配。
- 等于 - 如果值等于指定值则匹配。
- 不等于 - 如果值不等于指定值则匹配。
字符串字段的可用条件有
- 包含子字符串 - 如果值包含指定的子字符串则匹配(不区分大小写)。
- 不包含子字符串 - 如果值不包含指定的子字符串则匹配(不区分大小写)。
数字字段的可用条件有
- 大于 - 如果值大于指定值则匹配。
- 小于 - 如果值小于指定值则匹配。
- 大于或等于 - 如果值大于或等于指定值则匹配。
- 小于或等于 - 如果值小于或等于指定值则匹配。
- 范围 - 匹配指定最小值和最大值之间的范围,包含最小值和最大值。
考虑以下数据集
数据集示例
| 时间 | 温度 | 海拔 |
|---|---|---|
| 2020-07-07 11:34:23 | 32 | 101 |
| 2020-07-07 11:34:22 | 28 | 125 |
| 2020-07-07 11:34:21 | 26 | 110 |
| 2020-07-07 11:34:20 | 23 | 98 |
| 2020-07-07 10:32:24 | 31 | 95 |
| 2020-07-07 10:31:22 | 20 | 85 |
| 2020-07-07 09:30:57 | 19 | 101 |
如果您包含温度低于 30°C 的数据点,配置将如下所示
- 过滤类型:“包含”
- 条件:行中“温度”匹配“小于”的值“30”
您将得到以下结果,其中只包含温度低于 30°C 的数据
转换后的数据
| 时间 | 温度 | 海拔 |
|---|---|---|
| 2020-07-07 11:34:22 | 28 | 125 |
| 2020-07-07 11:34:21 | 26 | 110 |
| 2020-07-07 11:34:20 | 23 | 98 |
| 2020-07-07 10:31:22 | 20 | 85 |
| 2020-07-07 09:30:57 | 19 | 101 |
您可以为过滤器添加多个条件。例如,您可能只想在海拔高于 100 时包含数据。为此,请将该条件添加到以下配置中
- 过滤类型:包含“匹配所有”条件的行
- 条件 1:行中“温度”匹配“小于”的值“30”
- 条件 2:行中“海拔”匹配“大于”的值“100”
当您有多个条件时,您可以选择是希望将操作(包含/排除)应用于匹配所有条件的行,还是应用于匹配任何您添加的条件的行。
在上面的示例中,我们选择了匹配所有,因为我们想包含温度低于 30°C *且*海拔高于 100 的行。如果我们想包含温度低于 30°C *或*海拔高于 100 的行,那么我们将选择匹配任何。这将包含原始数据中的第一行,该行的温度为 32°C(不匹配第一个条件),但海拔为 101(匹配第二个条件),因此它被包含在内。
无效或配置不完整的条件将被忽略。
这种多功能的数据过滤转换使您可以根据特定条件选择性地包含或排除数据点。自定义条件以调整您的数据呈现方式,以满足您独特的分析需求。
按名称过滤字段
使用此转换选择性地删除查询结果的部分内容。有三种方法可以按名称过滤字段
使用正则表达式
当您使用正则表达式进行过滤时,匹配该正则表达式的字段名称将被包含。
例如,对于输入数据
| 时间 | dev-eu-west | dev-eu-north | prod-eu-west | prod-eu-north |
|---|---|---|---|---|
| 2023-03-04 23:56:23 | 23.5 | 24.5 | 22.2 | 20.2 |
| 2023-03-04 23:56:23 | 23.6 | 24.4 | 22.1 | 20.1 |
使用正则表达式“prod.*”的结果将是
| 时间 | prod-eu-west | prod-eu-north |
|---|---|---|
| 2023-03-04 23:56:23 | 22.2 | 20.2 |
| 2023-03-04 23:56:23 | 22.1 | 20.1 |
正则表达式可以通过使用 ${variableName} 语法来包含插值的仪表盘变量。
手动选择包含的字段
点击并取消勾选字段名称以将其从结果中删除。通过正则表达式匹配的字段即使未被勾选,仍会被包含。
使用仪表盘变量
启用“从变量”,您可以选择一个用于包含字段的仪表盘变量。通过设置一个具有多个选项的仪表盘变量,相同的字段可以在多个可视化中显示。
这是我们应用移除 Min 字段的转换后的表格。
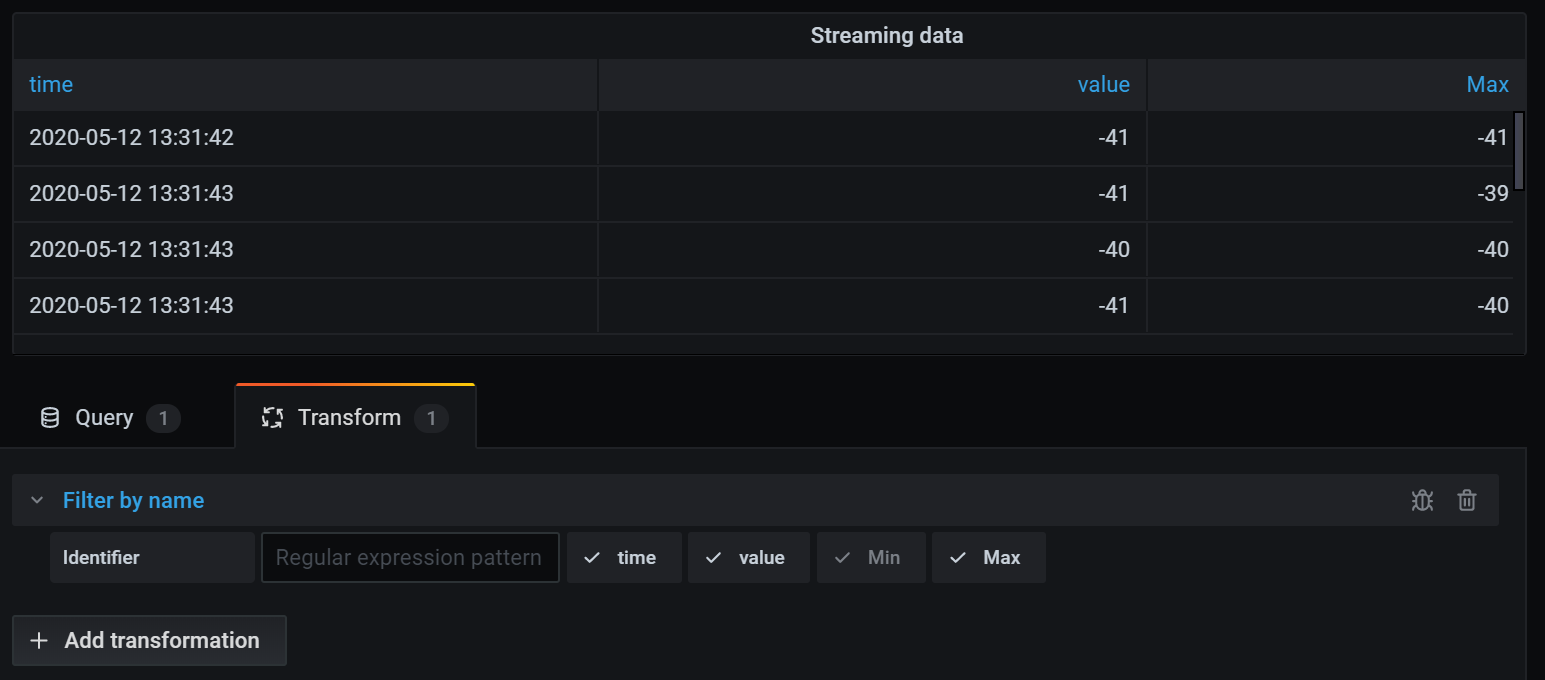
这是使用统计可视化呈现的相同查询。
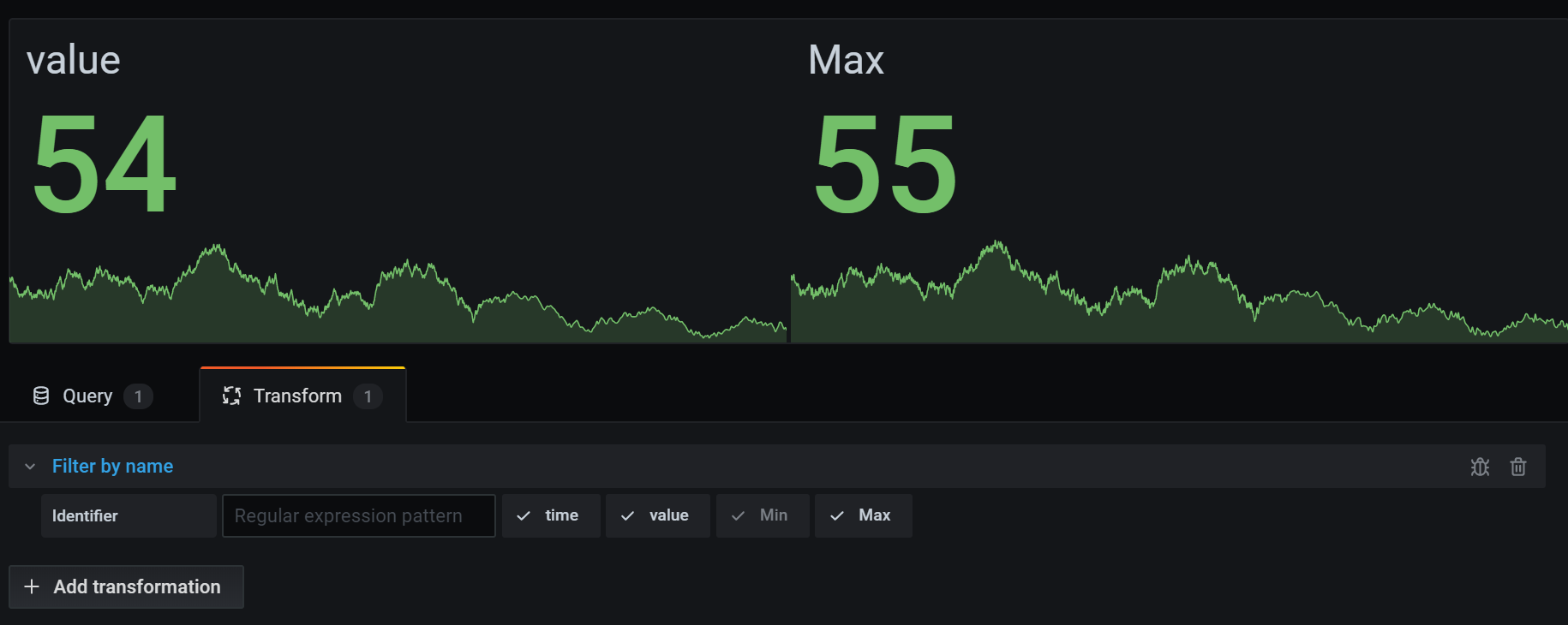
此转换提供了灵活性,可用于定制您的查询结果,以便专注于有效分析和可视化所需的特定字段。
格式化字符串
使用此转换来自定义字符串字段的输出。此转换具有以下字段
- 大写 - 将整个字符串格式化为大写字符。
- 小写 - 将整个字符串格式化为小写字符。
- 句子首字母大写 - 将字符串的第一个字符格式化为大写。
- 标题首字母大写 - 将字符串中每个单词的第一个字符格式化为大写。
- 帕斯卡命名法 - 将字符串中每个单词的第一个字符格式化为大写,并且单词之间不包含空格。
- 驼峰命名法 - 将字符串中除第一个单词外每个单词的第一个字符格式化为大写,并且单词之间不包含空格。
- 蛇形命名法 - 将字符串中所有字符格式化为小写,并且在单词之间使用下划线代替空格。
- 烤串命名法 - 将字符串中所有字符格式化为小写,并且在单词之间使用短划线代替空格。
- 修剪 - 删除字符串中所有前导和尾随空格。
- 子字符串 - 返回字符串的子字符串,使用指定的起始和结束位置。
此转换提供了一种便捷的方式来标准化和调整字符串数据的呈现方式,以实现更好的可视化和分析。
格式化时间
使用此转换来自定义时间字段的输出。输出可以使用Moment.js 格式字符串进行格式化。例如,如果您只想显示时间字段的年份,可以使用格式字符串“YYYY”来显示公历年份(例如,1999 或 2012)。
转换前
| 时间戳 | 事件 |
|---|---|
| 1636678740000000000 | 系统启动 |
| 1636678680000000000 | 用户登录 |
| 1636678620000000000 | 数据更新 |
应用“YYYY-MM-DD HH:mm:ss”后
| 时间戳 | 事件 |
|---|---|
| 2021-11-12 14:25:40 | 系统启动 |
| 2021-11-12 14:24:40 | 用户登录 |
| 2021-11-12 14:23:40 | 数据更新 |
此转换使您可以在可视化中调整时间表示,从而在显示时间数据时提供灵活性和精确度。
注意:此转换在 Grafana 10.1+ 中作为 Alpha 功能提供。
按...分组
使用此转换按指定字段(列)值对数据进行分组,并对每个组执行计算。点击查看计算选项列表。有关可用计算的信息,请参阅计算类型。
这是原始数据示例。
| 时间 | 服务器 ID | CPU 温度 | 服务器状态 |
|---|---|---|---|
| 2020-07-07 11:34:20 | server 1 | 80 | 关机 |
| 2020-07-07 11:34:20 | server 3 | 62 | 正常 |
| 2020-07-07 10:32:20 | server 2 | 90 | 过载 |
| 2020-07-07 10:31:22 | server 3 | 55 | 正常 |
| 2020-07-07 09:30:57 | server 3 | 62 | 正在重启 |
| 2020-07-07 09:30:05 | server 2 | 88 | 正常 |
| 2020-07-07 09:28:06 | server 1 | 80 | 正常 |
| 2020-07-07 09:25:05 | server 2 | 88 | 正常 |
| 2020-07-07 09:23:07 | server 1 | 86 | 正常 |
此转换分为两个步骤。首先,指定一个或多个字段来对数据进行分组。这将把这些字段的所有相同值分组在一起,就像您对它们进行排序一样。例如,如果我们按服务器 ID 字段分组,那么数据将按以下方式分组
| 时间 | 服务器 ID | CPU 温度 | 服务器状态 |
|---|---|---|---|
| 2020-07-07 11:34:20 | server 1 | 80 | 关机 |
| 2020-07-07 09:28:06 | server 1 | 80 | 正常 |
| 2020-07-07 09:23:07 | server 1 | 86 | 正常 |
| 2020-07-07 10:32:20 | server 2 | 90 | 过载 |
| 2020-07-07 09:30:05 | server 2 | 88 | 正常 |
| 2020-07-07 09:25:05 | server 2 | 88 | 正常 |
| 2020-07-07 11:34:20 | server 3 | 62 | 正常 |
| 2020-07-07 10:31:22 | server 3 | 55 | 正常 |
| 2020-07-07 09:30:57 | server 3 | 62 | 正在重启 |
所有具有相同服务器 ID 值的行被分组在一起。
选择要按哪个字段对数据进行分组后,您可以在其他字段上添加各种计算,并将计算应用于每组行。例如,我们可能想计算每个服务器的平均 CPU 温度。因此,我们可以将应用于 CPU 温度字段的平均值计算添加到配置中,以获得以下结果
| 服务器 ID | CPU 温度(平均值) |
|---|---|
| server 1 | 82 |
| server 2 | 88.6 |
| server 3 | 59.6 |
并且我们可以添加不止一个计算。例如
- 对于“时间”字段,我们可以计算最后一个值,以了解每个服务器何时接收到最后一个数据点
- 对于“服务器状态”字段,我们可以计算最后一个值,以了解每个服务器的最后一个状态值是什么
- 对于“温度”字段,我们也可以计算最后一个值,以了解每个服务器的最新监控温度是什么
然后我们将得到
| 服务器 ID | CPU 温度(平均值) | CPU 温度(最后值) | 时间(最后值) | 服务器状态(最后值) |
|---|---|---|---|---|
| server 1 | 82 | 80 | 2020-07-07 11:34:20 | 关机 |
| server 2 | 88.6 | 90 | 2020-07-07 10:32:20 | 过载 |
| server 3 | 59.6 | 62 | 2020-07-07 11:34:20 | 正常 |
此转换允许您从时间序列中提取重要信息并方便地呈现。
分组为矩阵
使用此转换结合三个字段(用作查询输出中的列、行和单元格值字段的输入)并生成一个矩阵。矩阵计算方式如下
原始数据
| 服务器 ID | CPU 温度 | 服务器状态 |
|---|---|---|
| server 1 | 82 | 正常 |
| server 2 | 88.6 | 正常 |
| server 3 | 59.6 | 关机 |
我们可以使用“服务器状态”的值作为列名,“服务器 ID”的值作为行名,“CPU 温度”作为每个单元格的内容来生成一个矩阵。对于存在的列(“服务器状态”)和行组合(“服务器 ID”),将显示相应的单元格内容。对于其余单元格,您可以选择显示以下值:Null、True、False 或空。
输出
| 服务器 ID服务器状态 | 正常 | 关机 |
|---|---|---|
| server 1 | 82 | |
| server 2 | 88.6 | |
| server 3 | 59.6 |
使用此转换通过指定查询结果中的字段来构建矩阵。矩阵输出反映了这些字段中唯一值之间的关系。这有助于您以清晰结构化的矩阵格式呈现复杂关系。
分组为嵌套表
使用此转换按指定字段(列)值对数据进行分组,并对每个组执行计算。将生成共享相同分组字段值的记录,并在嵌套表中显示。
要计算某个字段的统计信息,请单击其旁边的选择框并选择计算选项
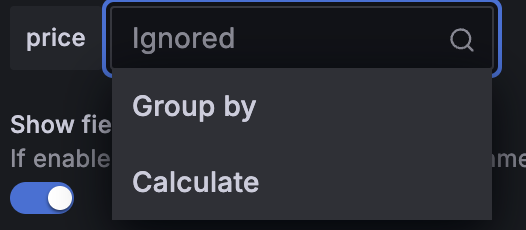
选择计算后,将在相应字段旁边出现另一个选择框,允许选择统计信息
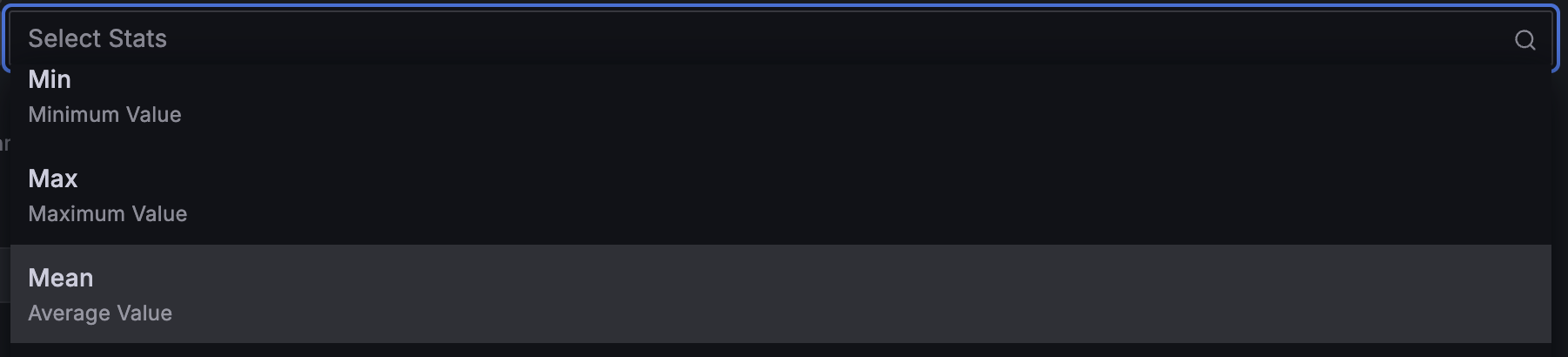
有关可用计算的信息,请参阅计算类型。
这是原始数据示例
| 时间 | 服务器 ID | CPU 温度 | 服务器状态 |
|---|---|---|---|
| 2020-07-07 11:34:20 | server 1 | 80 | 关机 |
| 2020-07-07 11:34:20 | server 3 | 62 | 正常 |
| 2020-07-07 10:32:20 | server 2 | 90 | 过载 |
| 2020-07-07 10:31:22 | server 3 | 55 | 正常 |
| 2020-07-07 09:30:57 | server 3 | 62 | 正在重启 |
| 2020-07-07 09:30:05 | server 2 | 88 | 正常 |
| 2020-07-07 09:28:06 | server 1 | 80 | 正常 |
| 2020-07-07 09:25:05 | server 2 | 88 | 正常 |
| 2020-07-07 09:23:07 | server 1 | 86 | 正常 |
此转换分为两个步骤。首先,指定一个或多个字段来对数据进行分组。这将把这些字段的所有相同值分组在一起,就像您对它们进行排序一样。例如,如果您按服务器 ID 字段分组,Grafana 会按以下方式对数据进行分组
| 服务器 ID | ||||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
| server 1 |
| |||||||||||||
| server 2 |
| |||||||||||||
| server 3 |
|
选择要按哪个字段对数据进行分组后,您可以在其他字段上添加各种计算,并将计算应用于每组行。例如,您可能想计算每个服务器的平均 CPU 温度。为此,请将应用于 CPU 温度字段的平均值计算添加到配置中,以获得以下结果
| 服务器 ID | CPU 温度(平均值) | ||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|
| server 1 | 82 |
| |||||||||
| server 2 | 88.6 |
| |||||||||
| server 3 | 59.6 |
|
创建热力图
使用此转换准备直方图数据,以便可视化随时间变化的趋势。类似于热力图可视化,此转换将直方图指标转换为时间桶。
X 轴桶
此设置确定如何将 X 轴分割成桶。
- 大小 - 在输入字段中指定一个时间间隔。例如,时间范围为“1h”将在 X 轴上创建一小时宽的单元格。
- 计数 - 对于非时间相关的序列,使用此选项来定义桶中的元素数量。
Y 轴桶
此设置确定如何将 Y 轴分割成桶。
- 线性
- 对数 - 选择对数底数为 2 或对数底数为 10。
- 对称对数 - 使用对称对数刻度。选择对数底数为 2 或对数底数为 10,允许存在负值。
假设您有以下数据集
| 时间戳 | 值 |
|---|---|
| 2023-01-01 12:00:00 | 5 |
| 2023-01-01 12:15:00 | 10 |
| 2023-01-01 12:30:00 | 15 |
| 2023-01-01 12:45:00 | 8 |
- 将 X 轴桶设置为“大小:15m”,Y 轴桶设置为“线性”时,直方图将值按 15 分钟的时间间隔在 X 轴上组织,并在 Y 轴上线性组织。
- 当 X 轴桶设置为“计数:2”,Y 轴桶设置为“对数(底数 10)”时,直方图将值按每两个一组在 X 轴上分组,并在 Y 轴上使用对数刻度。
直方图
使用此转换基于输入数据生成直方图,从而可视化值的分布。
- 桶大小 - 桶中最低值和最高值之间的范围(xMin 到 xMax)。
- 桶偏移量 - 非零基桶的偏移量。
- 合并序列 - 使用所有可用序列创建统一的直方图。
原始数据
序列 1
| A | B | C |
|---|---|---|
| 1 | 3 | 5 |
| 2 | 4 | 6 |
| 3 | 5 | 7 |
| 4 | 6 | 8 |
| 5 | 7 | 9 |
序列 2
| C |
|---|
| 5 |
| 6 |
| 7 |
| 8 |
| 9 |
输出
| xMin | xMax | A | B | C | C |
|---|---|---|---|---|---|
| 1 | 2 | 1 | 0 | 0 | 0 |
| 2 | 3 | 1 | 0 | 0 | 0 |
| 3 | 4 | 1 | 1 | 0 | 0 |
| 4 | 5 | 1 | 1 | 0 | 0 |
| 5 | 6 | 1 | 1 | 1 | 1 |
| 6 | 7 | 0 | 1 | 1 | 1 |
| 7 | 8 | 0 | 1 | 1 | 1 |
| 8 | 9 | 0 | 0 | 1 | 1 |
| 9 | 10 | 0 | 0 | 1 | 1 |
使用生成的直方图可视化值的分布,提供关于数据分散性和密度的见解。
按字段连接
使用此转换将多个结果合并到一个表中,从而能够整合来自不同查询的数据。
这对于将多个时间序列结果转换为具有共享时间字段的单个宽表特别有用。
内连接(适用于时间序列或类 SQL 数据)
内连接合并来自多个表的数据,其中所有表在选定字段中共享相同的值。此类型的连接排除在每个结果中值不匹配的数据。
使用此转换将多个查询的结果(基于传递的连接字段或第一个时间列进行组合)合并为一个结果,并删除无法成功连接的行。此转换未针对大型时间序列数据集进行优化。
在以下示例中,两个查询返回时间序列数据。在应用内连接转换之前,它们被可视化为两个单独的表。
查询 A
| 时间 | Job | 正常运行时间 |
|---|---|---|
| 2020-07-07 11:34:20 | node | 25260122 |
| 2020-07-07 11:24:20 | postgre | 123001233 |
| 2020-07-07 11:14:20 | postgre | 345001233 |
查询 B
| 时间 | Server | 错误 |
|---|---|---|
| 2020-07-07 11:34:20 | server 1 | 15 |
| 2020-07-07 11:24:20 | server 2 | 5 |
| 2020-07-07 11:04:20 | server 3 | 10 |
应用内连接转换后的结果如下所示
| 时间 | Job | 正常运行时间 | Server | 错误 |
|---|---|---|---|---|
| 2020-07-07 11:34:20 | node | 25260122 | server 1 | 15 |
| 2020-07-07 11:24:20 | postgre | 123001233 | server 2 | 5 |
这对于非时间序列的表格数据也同样适用。
学生
| 学生 ID | 名称 | 专业 |
|---|---|---|
| 1 | John | 计算机科学 |
| 2 | Emily | 数学 |
| 3 | Michael | 物理 |
| 4 | Jennifer | 化学 |
注册
| 学生 ID | 课程 ID | 成绩 |
|---|---|---|
| 1 | CS101 | A |
| 1 | CS102 | B |
| 2 | MATH201 | A |
| 3 | PHYS101 | B |
| 5 | HIST101 | B |
应用内连接转换后的结果如下所示
| 学生 ID | 名称 | 专业 | 课程 ID | 成绩 |
|---|---|---|---|---|
| 1 | John | 计算机科学 | CS101 | A |
| 1 | John | 计算机科学 | CS102 | B |
| 2 | Emily | 数学 | MATH201 | A |
| 3 | Michael | 物理 | PHYS101 | B |
内连接仅包含两个表中“学生 ID”匹配的行。在此示例中,结果不包含“学生”表中的“Jennifer”,因为在“注册”表中没有她匹配的注册记录。
外连接(适用于时间序列数据)
外连接包含内连接的所有数据以及在每个输入中值不匹配的行。内连接根据时间字段连接查询 A 和查询 B,而外连接则包含所有在时间字段上不匹配的行。
在以下示例中,两个查询返回表格数据。在应用外连接转换之前,它们被可视化为两个表。
查询 A
| 时间 | Job | 正常运行时间 |
|---|---|---|
| 2020-07-07 11:34:20 | node | 25260122 |
| 2020-07-07 11:24:20 | postgre | 123001233 |
| 2020-07-07 11:14:20 | postgre | 345001233 |
查询 B
| 时间 | Server | 错误 |
|---|---|---|
| 2020-07-07 11:34:20 | server 1 | 15 |
| 2020-07-07 11:24:20 | server 2 | 5 |
| 2020-07-07 11:04:20 | server 3 | 10 |
应用外连接转换后的结果如下所示
| 时间 | Job | 正常运行时间 | Server | 错误 |
|---|---|---|---|---|
| 2020-07-07 11:04:20 | server 3 | 10 | ||
| 2020-07-07 11:14:20 | postgre | 345001233 | ||
| 2020-07-07 11:34:20 | node | 25260122 | server 1 | 15 |
| 2020-07-07 11:24:20 | postgre | 123001233 | server 2 | 5 |
在以下示例中,模板查询在表格可视化中显示来自多个服务器的时间序列数据。一次只能查看一个查询的结果。
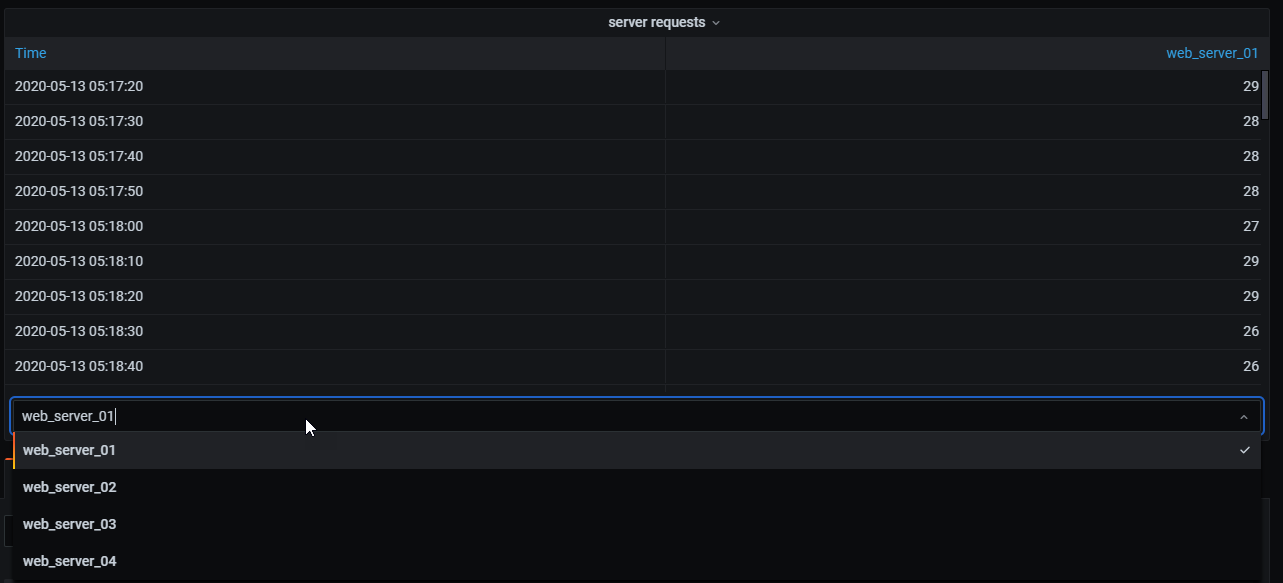
我应用了一个转换,使用时间字段连接查询结果。现在,我可以在这个新表中运行计算、合并和组织结果。
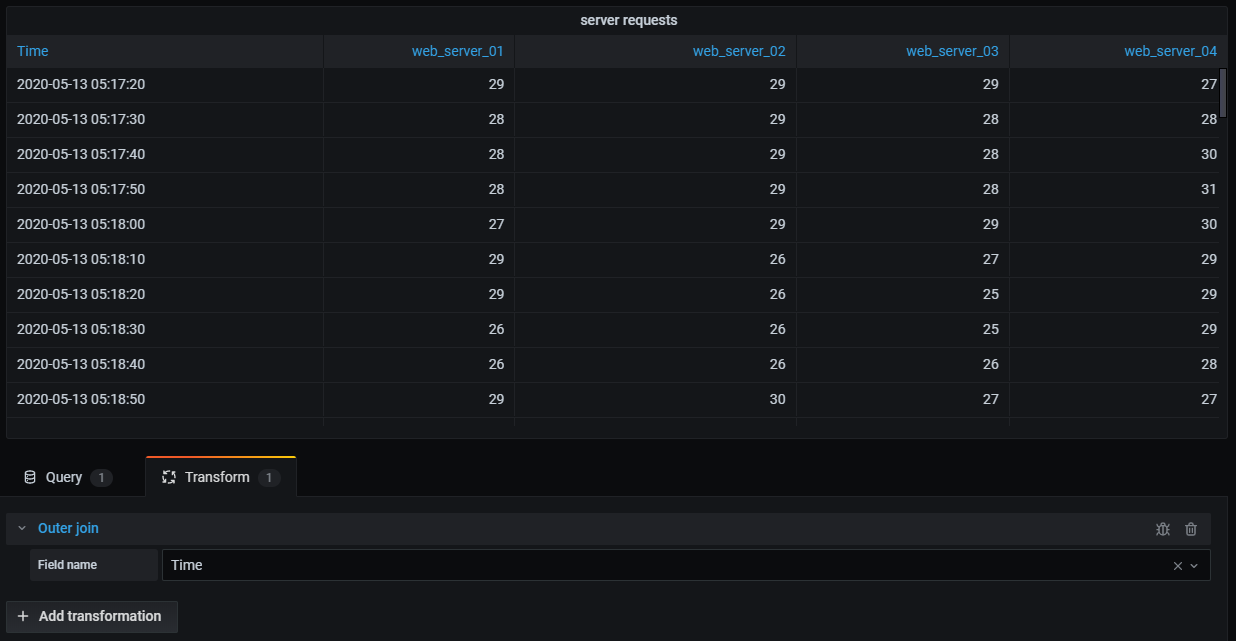
外连接(适用于类 SQL 数据)
表格外连接将多个表组合在一起,结果包含来自一个或两个表的匹配行和不匹配行。
| 学生 ID | 名称 | 专业 |
|---|---|---|
| 1 | John | 计算机科学 |
| 2 | Emily | 数学 |
| 3 | Michael | 物理 |
| 4 | Jennifer | 化学 |
现在可以与...连接
| 学生 ID | 课程 ID | 成绩 |
|---|---|---|
| 1 | CS101 | A |
| 1 | CS102 | B |
| 2 | MATH201 | A |
| 3 | PHYS101 | B |
| 5 | HIST101 | B |
应用外连接转换后的结果如下所示
| 学生 ID | 名称 | 专业 | 课程 ID | 成绩 |
|---|---|---|---|---|
| 1 | John | 计算机科学 | CS101 | A |
| 1 | John | 计算机科学 | CS102 | B |
| 2 | Emily | 数学 | MATH201 | A |
| 3 | Michael | 物理 | PHYS101 | B |
| 4 | Jennifer | 化学 | NULL | NULL |
| 5 | NULL | NULL | HIST101 | B |
通过表连接结合和分析来自各种查询的数据,以获取您信息的全面视图。
按标签连接
使用此转换将多个结果合并到一个表中。
这对于将多个时间序列结果转换为具有共享标签字段的单个宽表特别有用。
- 连接 - 在所有时间序列可用或共同的标签中选择要连接的标签。
- 值 - 输出结果的名称。
示例
输入
series1{what=“Temp”, cluster=“A”, job=“J1”}
| 时间 | 值 |
|---|---|
| 1 | 10 |
| 2 | 200 |
series2{what=“Temp”, cluster=“B”, job=“J1”}
| 时间 | 值 |
|---|---|
| 1 | 10 |
| 2 | 200 |
series3{what=“Speed”, cluster=“B”, job=“J1”}
| 时间 | 值 |
|---|---|
| 22 | 22 |
| 28 | 77 |
配置
值:“what”
输出
| cluster | job | 温度 | Speed |
|---|---|---|---|
| A | J1 | 10 | |
| A | J1 | 200 | |
| B | J1 | 10 | 22 |
| B | J1 | 200 | 77 |
利用此转换有效组合和组织时间序列数据,以获得全面见解。
标签转字段
使用此转换将带有标签或标记的时间序列结果转换为表,结果中包含每个标签的键和值。将标签显示为列或行值,以增强数据可视化。
给定两个时间序列的查询结果
- 序列 1:标签 Server=Server A, Datacenter=EU
- 序列 2:标签 Server=Server B, Datacenter=EU
在“列”模式下,结果如下所示
| 时间 | Server | Datacenter | 值 |
|---|---|---|---|
| 2020-07-07 11:34:20 | Server A | EU | 1 |
| 2020-07-07 11:34:20 | Server B | EU | 2 |
在“行”模式下,每个序列都有一个表,并显示每个标签值,如下所示
| label | value |
|---|---|
| Server | Server A |
| Datacenter | EU |
| label | value |
|---|---|
| Server | Server B |
| Datacenter | EU |
值字段名称
如果您选择“Server”作为值字段名称,则对于 Server 标签的每个值,您将获得一个字段。
| 时间 | Datacenter | Server A | Server B |
|---|---|---|---|
| 2020-07-07 11:34:20 | EU | 1 | 2 |
合并行为
标签转字段转换器内部是两个独立的转换。第一个作用于单个序列,将标签提取到字段中。第二个是 合并转换,它将所有结果连接到一个表中。合并转换尝试基于所有匹配的字段进行连接。此合并步骤是必需的,不能关闭。
为了说明这一点,这里有一个示例,其中您有两个查询,它们返回的时间序列没有重叠的标签。
- 序列 1:标签 Server=ServerA
- 序列 2:标签 Datacenter=EU
这首先会生成这两个表
| 时间 | Server | 值 |
|---|---|---|
| 2020-07-07 11:34:20 | ServerA | 10 |
| 时间 | Datacenter | 值 |
|---|---|---|
| 2020-07-07 11:34:20 | EU | 20 |
合并后
| 时间 | Server | 值 | Datacenter |
|---|---|---|---|
| 2020-07-07 11:34:20 | ServerA | 10 | |
| 2020-07-07 11:34:20 | 20 | EU |
将您的时间序列数据转换为结构化的表格格式,以获得更清晰、更有条理的表示。
限制
使用此转换来限制显示的行数,从而提供数据更集中的视图。这在处理大型数据集时特别有用。
以下示例说明了限制转换对数据源响应的影响
| 时间 | Metric | 值 |
|---|---|---|
| 2020-07-07 11:34:20 | 温度 | 25 |
| 2020-07-07 11:34:20 | Humidity | 22 |
| 2020-07-07 10:32:20 | Humidity | 29 |
| 2020-07-07 10:31:22 | 温度 | 22 |
| 2020-07-07 09:30:57 | Humidity | 33 |
| 2020-07-07 09:30:05 | 温度 | 19 |
这是添加限制转换(值为“3”)后的结果
| 时间 | Metric | 值 |
|---|---|---|
| 2020-07-07 11:34:20 | 温度 | 25 |
| 2020-07-07 11:34:20 | Humidity | 22 |
| 2020-07-07 10:32:20 | Humidity | 29 |
使用负数,您可以保留集合末尾的值。这是添加限制转换(值为“-3”)后的结果
| 时间 | Metric | 值 |
|---|---|---|
| 2020-07-07 10:31:22 | 温度 | 22 |
| 2020-07-07 09:30:57 | Humidity | 33 |
| 2020-07-07 09:30:05 | 温度 | 19 |
此转换帮助您调整数据的可视化呈现,以便专注于最相关的信息。
合并序列/表
使用此转换将多个查询的结果合并到单个结果中,这在使用表格面板可视化时特别有用。如果共享字段包含相同数据,此转换将值合并到同一行。
以下示例说明了合并序列/表转换对返回表格数据的两个查询的影响
查询 A
| 时间 | Job | 正常运行时间 |
|---|---|---|
| 2020-07-07 11:34:20 | node | 25260122 |
| 2020-07-07 11:24:20 | postgre | 123001233 |
查询 B
| 时间 | Job | 错误 |
|---|---|---|
| 2020-07-07 11:34:20 | node | 15 |
| 2020-07-07 11:24:20 | postgre | 5 |
这是应用合并转换后的结果。
| 时间 | Job | 错误 | 正常运行时间 |
|---|---|---|---|
| 2020-07-07 11:34:20 | node | 15 | 25260122 |
| 2020-07-07 11:24:20 | postgre | 5 | 123001233 |
此转换将查询 A 和查询 B 的值合并到一个统一的表中,从而增强数据的呈现效果,以便获得更好的见解。
按名称组织字段
使用此转换可以灵活地重命名、重新排序或隐藏面板中单个查询返回的字段。此转换仅适用于具有单个查询的面板。如果您的面板有多个查询,请考虑使用“外连接”转换或删除额外查询。
转换字段
Grafana 显示查询返回的字段列表,允许您执行以下操作
- 更改字段顺序 - 将鼠标悬停在字段上,当光标变成手形时,将字段拖动到新位置。
- 隐藏或显示字段 - 使用字段名称旁边的眼睛图标来切换特定字段的可见性。
- 重命名字段 - 在“重命名
”框中自定义字段名称。
示例
原始查询结果
| 时间 | Metric | 值 |
|---|---|---|
| 2020-07-07 11:34:20 | 温度 | 25 |
| 2020-07-07 11:34:20 | Humidity | 22 |
| 2020-07-07 10:32:20 | Humidity | 29 |
应用字段覆盖后
| 时间 | Sensor | Reading |
|---|---|---|
| 2020-07-07 11:34:20 | 温度 | 25 |
| 2020-07-07 11:34:20 | Humidity | 22 |
| 2020-07-07 10:32:20 | Humidity | 29 |
此转换使您可以调整查询结果的显示,确保在 Grafana 中清晰且有洞察力地呈现数据。
按值分区
使用此转换简化绘制多个序列的过程,无需使用具有不同“WHERE”子句的多个查询。
在处理指标 SQL 表时特别有用,如下所示
| 时间 | Region | 值 |
|---|---|---|
| 2022-10-20 12:00:00 | US | 1520 |
| 2022-10-20 12:00:00 | EU | 2936 |
| 2022-10-20 01:00:00 | US | 1327 |
| 2022-10-20 01:00:00 | EU | 912 |
使用按值分区转换,您可以发出单个查询,并根据您选择的一个或多个列(字段)中的唯一值分割结果。以下示例使用“Region”
‘SELECT Time, Region, Value FROM metrics WHERE Time > “2022-10-20”’
| 时间 | Region | 值 |
|---|---|---|
| 2022-10-20 12:00:00 | US | 1520 |
| 2022-10-20 01:00:00 | US | 1327 |
| 时间 | Region | 值 |
|---|---|---|
| 2022-10-20 12:00:00 | EU | 2936 |
| 2022-10-20 01:00:00 | EU | 912 |
此转换简化了流程,并增强了在同一时间序列可视化中可视化多个序列的灵活性。
准备时间序列
当数据源返回的时间序列数据格式与所需的可视化不兼容时,使用此转换来解决问题。此转换允许您在宽格式和长格式之间转换时间序列数据,从而提供数据帧结构的灵活性。
可用选项
宽格式时间序列
选择此选项将时间序列数据帧从长格式转换为宽格式。如果您的数据源以长格式返回时间序列数据,而您的可视化需要宽格式,此转换可以简化过程。
宽格式时间序列将数据组合到一个帧中,该帧有一个共享的、升序的时间字段。时间字段不重复,多个值在单独的列中扩展。
示例:从长格式转换为宽格式
| 时间戳 | Variable | 值 |
|---|---|---|
| 2023-01-01 00:00:00 | Value1 | 10 |
| 2023-01-01 00:00:00 | Value2 | 20 |
| 2023-01-01 01:00:00 | Value1 | 15 |
| 2023-01-01 01:00:00 | Value2 | 25 |
转换后
| 时间戳 | Value1 | Value2 |
|---|---|---|
| 2023-01-01 00:00:00 | 10 | 20 |
| 2023-01-01 01:00:00 | 15 | 25 |
多帧时间序列
多帧时间序列将数据分解为多个帧,所有这些帧都包含两个字段:一个时间字段和一个数值字段。时间始终是升序的。字符串值表示为字段标签。
长格式时间序列
长格式时间序列将数据组合到一个帧中,其中第一个字段是升序时间字段。时间字段可能存在重复。字符串值位于单独的字段中,并且可能不止一个。
示例:转换为长格式
| Value1 | Value2 | 时间戳 |
|---|---|---|
| 10 | 20 | 2023-01-03 00:00:00 |
| 30 | 40 | 2023-01-02 00:00:00 |
| 50 | 60 | 2023-01-01 00:00:00 |
| 70 | 80 | 2023-01-01 00:00:00 |
转换后
| 时间戳 | Value1 | Value2 |
|---|---|---|
| 2023-01-01 00:00:00 | 70 | 80 |
| 2023-01-01 01:00:00 | 50 | 60 |
| 2023-01-02 01:00:00 | 30 | 40 |
| 2023-01-03 01:00:00 | 10 | 20 |
降维
使用此转换对数据帧中的每个字段应用计算并返回单个值。此转换对于将多个时间序列数据整合为更紧凑的汇总格式特别有用。应用此转换时会移除时间字段。
考虑输入
查询 A
| 时间 | 温度 | 正常运行时间 |
|---|---|---|
| 2020-07-07 11:34:20 | 12.3 | 256122 |
| 2020-07-07 11:24:20 | 15.4 | 1230233 |
查询 B
| 时间 | AQI | 错误 |
|---|---|---|
| 2020-07-07 11:34:20 | 6.5 | 15 |
| 2020-07-07 11:24:20 | 3.2 | 5 |
降维转换器有两种模式
- 序列转行 - 为每个字段创建一行,为每个计算创建一列。
- 降维字段 - 保留现有的帧结构,但将每个字段折叠为单个值。
例如,如果您将第一个值和最后一个值计算与序列转行转换一起使用,结果将是
| 字段 | 第一个值 | 最后一个值 |
|---|---|---|
| 温度 | 12.3 | 15.4 |
| 正常运行时间 | 256122 | 1230233 |
| AQI | 6.5 | 3.2 |
| 错误 | 15 | 5 |
使用降维字段和最后一个值计算,结果是两个帧,每个帧有一行
查询 A
| 温度 | 正常运行时间 |
|---|---|
| 15.4 | 1230233 |
查询 B
| AQI | 错误 |
|---|---|
| 3.2 | 5 |
这种灵活的转换简化了将多个时间序列的数据整合和汇总为更易于管理和组织的格式的过程。
按正则表达式重命名
使用此转换可以使用正则表达式和替换模式重命名查询结果的部分内容。
您可以指定一个正则表达式(仅应用于匹配项)以及支持反向引用的替换模式。例如,假设您正在可视化每台主机的 CPU 使用率,并且想要删除域名。您可以将正则表达式设置为“/^([^.]+).*/”,将替换模式设置为“$1”,“web-01.example.com”将变为“web-01”。
注意:按正则表达式重命名转换在 Grafana v9.0.0 中得到了改进,允许使用形式为“/
/g”的全局模式。根据使用的正则表达式匹配方式,这可能会导致某些转换的行为略有不同。您可以通过将匹配字符串用正斜杠“(/)”包裹起来来保证与之前相同的行为,例如,“(.*)”将变为“/(.*)/”。
在以下示例中,我们从字段名称中去除前缀“A-”。在转换前图片中,您可以看到所有内容都带有前缀“A-”。
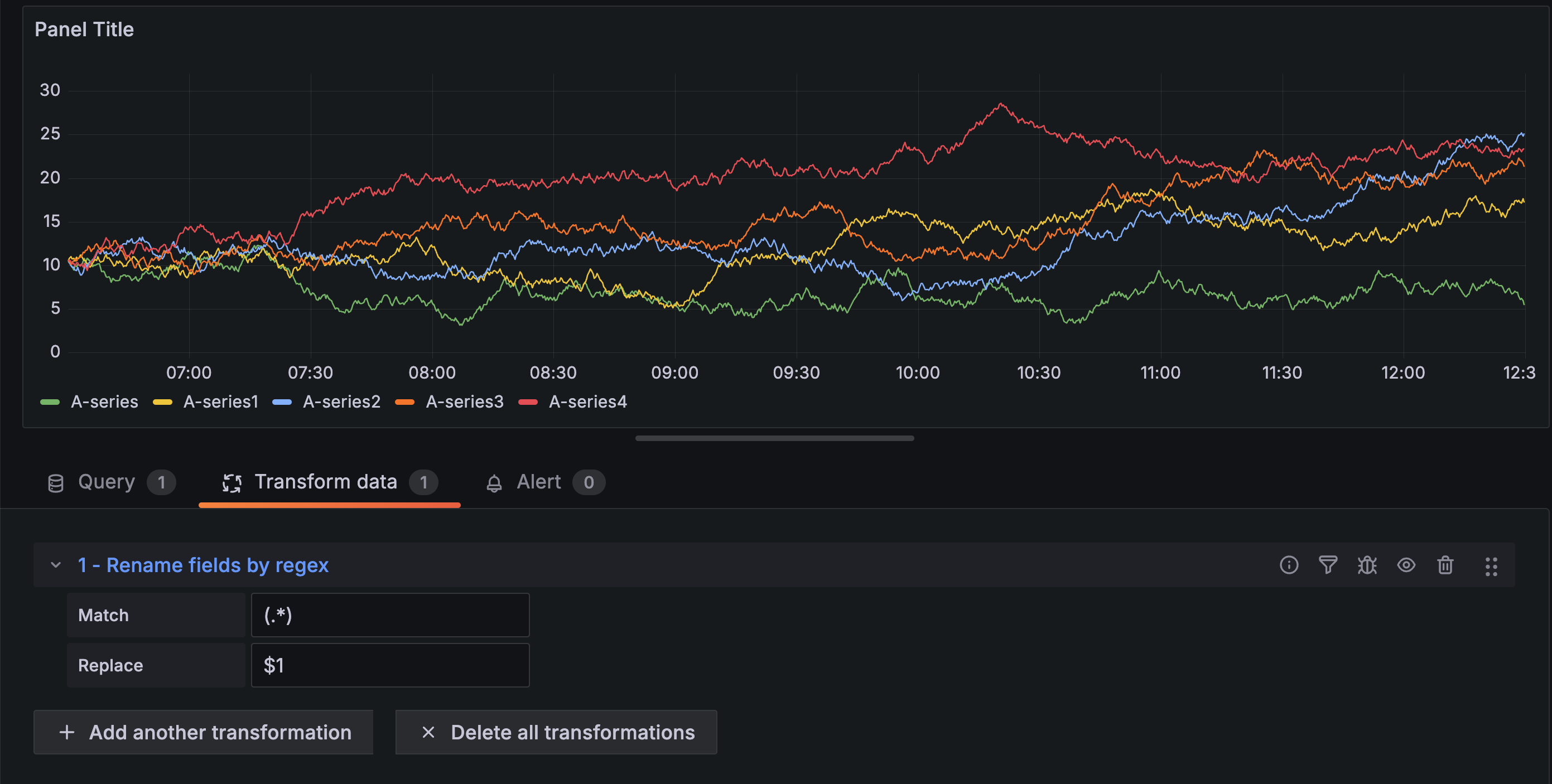
应用转换后,您可以看到只剩下字符串的其余部分。
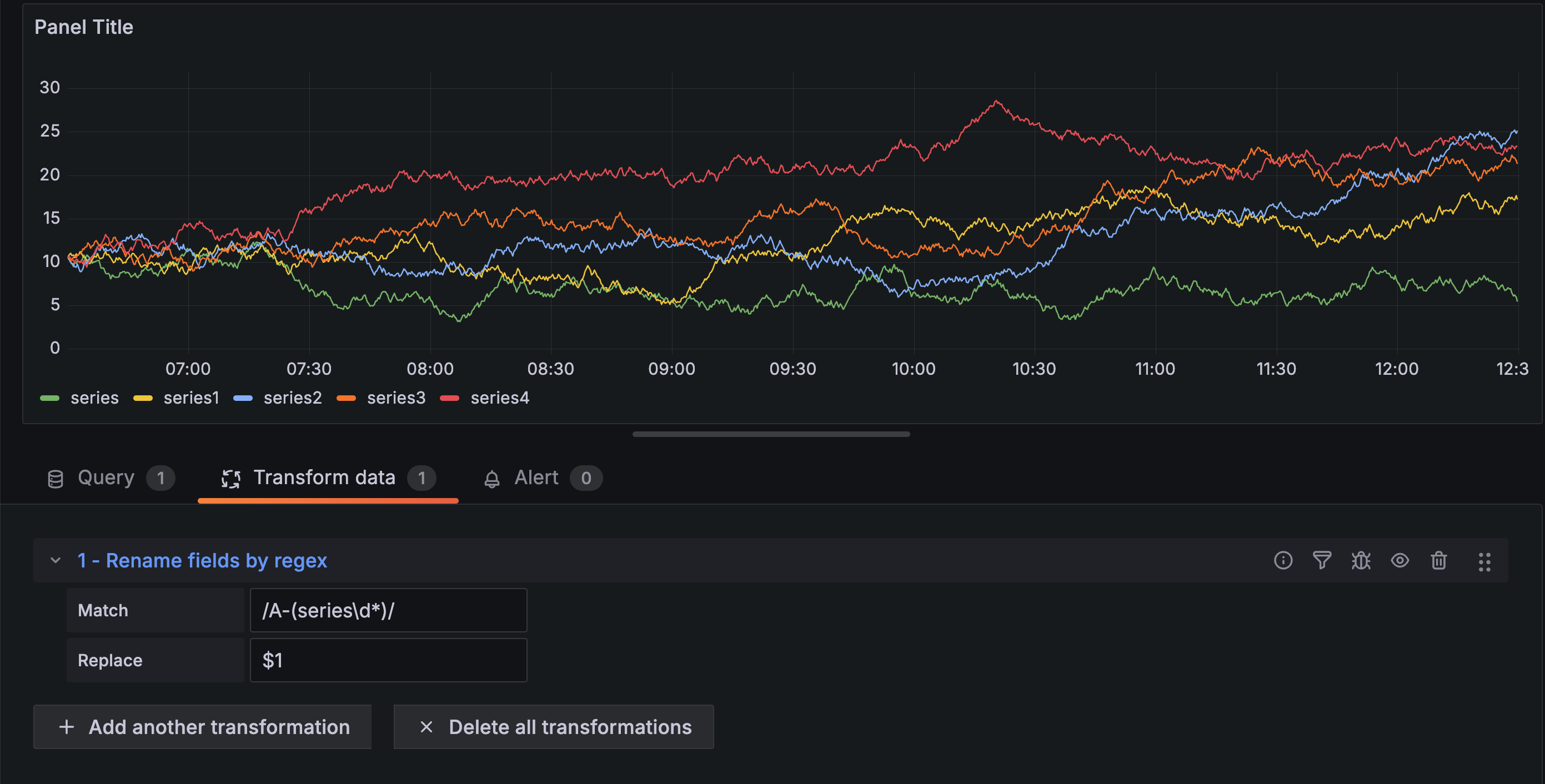
此转换使您能够定制数据以满足可视化需求,从而使您的仪表盘信息更丰富且更用户友好。
行转字段
使用此转换将行转换为单独的字段。这非常有用,因为字段可以单独设置样式和配置。它还可以使用附加字段作为动态字段配置的源或将其映射到字段标签。然后,这些附加标签可用于为结果字段定义更好的显示名称。
此转换包含一个字段表,其中列出了配置查询返回的数据中的所有字段。此表使您可以控制哪个字段应该映射到每个配置属性(用作选项)。如果返回的数据中有多个行,您还可以选择要选择哪个值。
此转换需要
一个字段用作字段名称的来源。
默认情况下,转换使用第一个字符串字段作为来源。您可以通过在要使用的字段的用作列中选择字段名称来覆盖此默认设置。
一个字段用作值的来源。
默认情况下,转换使用第一个数字字段作为来源。但您可以通过在要使用的字段的用作列中选择字段值来覆盖此默认设置。
可用于可视化数据时
- 规
- 统计值
- 饼图
将额外字段映射到标签
如果一个字段没有映射到配置属性,Grafana 将自动将其用作输出字段标签的来源。
示例
| 名称 | DataCenter | 值 |
|---|---|---|
| ServerA | US | 100 |
| ServerB | EU | 200 |
输出
| ServerA (标签: 数据中心: US) | ServerB (标签: 数据中心: EU) |
|---|---|
| 10 | 20 |
现在可以在字段显示名称中使用额外的标签,以提供更完整的字段名称。
如果要从一个查询中提取配置并将其应用于另一个查询,则应使用“从查询结果获取配置”转换。
示例
输入
| 名称 | 值 | 最大值 |
|---|---|---|
| ServerA | 10 | 100 |
| ServerB | 20 | 200 |
| ServerC | 30 | 300 |
输出
| ServerA (配置: max=100) | ServerB (配置: max=200) | ServerC (配置: max=300) |
|---|---|---|
| 10 | 20 | 30 |
如您所见,源数据中的每一行都成为一个单独的字段。现在每个字段也设置了最大值配置选项。最小值、最大值、单位和阈值等选项都是字段配置的一部分,如果像这样设置,可视化将使用它们,而不是面板编辑器选项窗格中手动配置的任何选项。
此转换支持将行转换为单独的字段,促进动态字段配置,并将附加字段映射到标签。
序列转行
使用此转换将来自多个时间序列数据查询的结果合并为一个结果。这在使用表格面板可视化时非常有用。
此转换的结果将包含三列:时间、指标和值。“指标”列是为了方便您查看指标来源于哪个查询而添加的。您可以通过在源查询上定义标签来自定义此值。
在下面的示例中,我们有两个查询返回时间序列数据。在应用转换之前,它们被可视化为两个单独的表。
查询 A
| 时间 | 温度 |
|---|---|
| 2020-07-07 11:34:20 | 25 |
| 2020-07-07 10:31:22 | 22 |
| 2020-07-07 09:30:05 | 19 |
查询 B
| 时间 | Humidity |
|---|---|
| 2020-07-07 11:34:20 | 24 |
| 2020-07-07 10:32:20 | 29 |
| 2020-07-07 09:30:57 | 33 |
这是应用序列转行转换后的结果。
| 时间 | Metric | 值 |
|---|---|---|
| 2020-07-07 11:34:20 | 温度 | 25 |
| 2020-07-07 11:34:20 | Humidity | 22 |
| 2020-07-07 10:32:20 | Humidity | 29 |
| 2020-07-07 10:31:22 | 温度 | 22 |
| 2020-07-07 09:30:57 | Humidity | 33 |
| 2020-07-07 09:30:05 | 温度 | 19 |
此转换促进了多个时间序列查询结果的整合,提供了流线型和统一的数据集,以便在表格格式中进行高效分析和可视化。
按...排序
使用此转换根据指定字段对查询结果中的每个帧进行排序,使您的数据更易于理解和分析。通过配置所需的排序字段,您可以控制数据在表或可视化中呈现的顺序。
使用反转开关可以对指定字段内的值进行逆序排序。当您想快速切换升序和降序以满足分析需求时,此功能特别有用。
例如,在从数据源检索时间序列数据的场景中,可以应用按...排序转换,根据时间戳按升序或降序排列数据帧,具体取决于分析需求。此功能确保您可以轻松浏览和解释时间序列数据,从组织良好、视觉一致的呈现中获得有价值的见解。
空间
使用此转换将空间操作应用于查询结果。
- 动作 - 选择一个动作
- 准备空间字段 - 根据其他字段的结果设置一个几何字段。
- 位置模式 - 选择一个位置模式(这些选项由计算值和转换模式共享)
- 自动 - 根据默认字段名称自动识别位置数据。
- 坐标 - 指定纬度字段和经度字段。
- Geohash - 指定一个 geohash 字段。
- 查找 - 指定 Gazetteer 位置字段。
- 位置模式 - 选择一个位置模式(这些选项由计算值和转换模式共享)
- 计算值 - 使用几何数据定义一个新字段(方向/距离/面积)。
- 函数 - 选择应用于几何数据的数学运算
- 方向 - 计算两点之间的方向。
- 面积 - 计算由几何数据定义的区域。
- 距离 - 计算两点之间的距离。
- 函数 - 选择应用于几何数据的数学运算
- 转换 - 将空间操作应用于几何数据。
- 操作 - 选择应用于几何数据的操作
- 作为线 - 创建一个单线特征,每行一个顶点。
- 线构建器 - 在两点之间创建一条线。
- 操作 - 选择应用于几何数据的操作
- 准备空间字段 - 根据其他字段的结果设置一个几何字段。
此转换允许您操作和分析地理空间数据,支持创建点之间的线、计算空间属性等操作。
时间序列转表转换
使用此转换将时间序列结果转换为表,将时间序列数据帧转换为趋势字段,然后可以与迷你图单元格类型一起使用。如果存在多个时间序列查询,每个查询将生成一个单独的表格数据帧。可以使用连接或合并转换将它们连接起来,生成一个每行包含多个迷你图的单表。
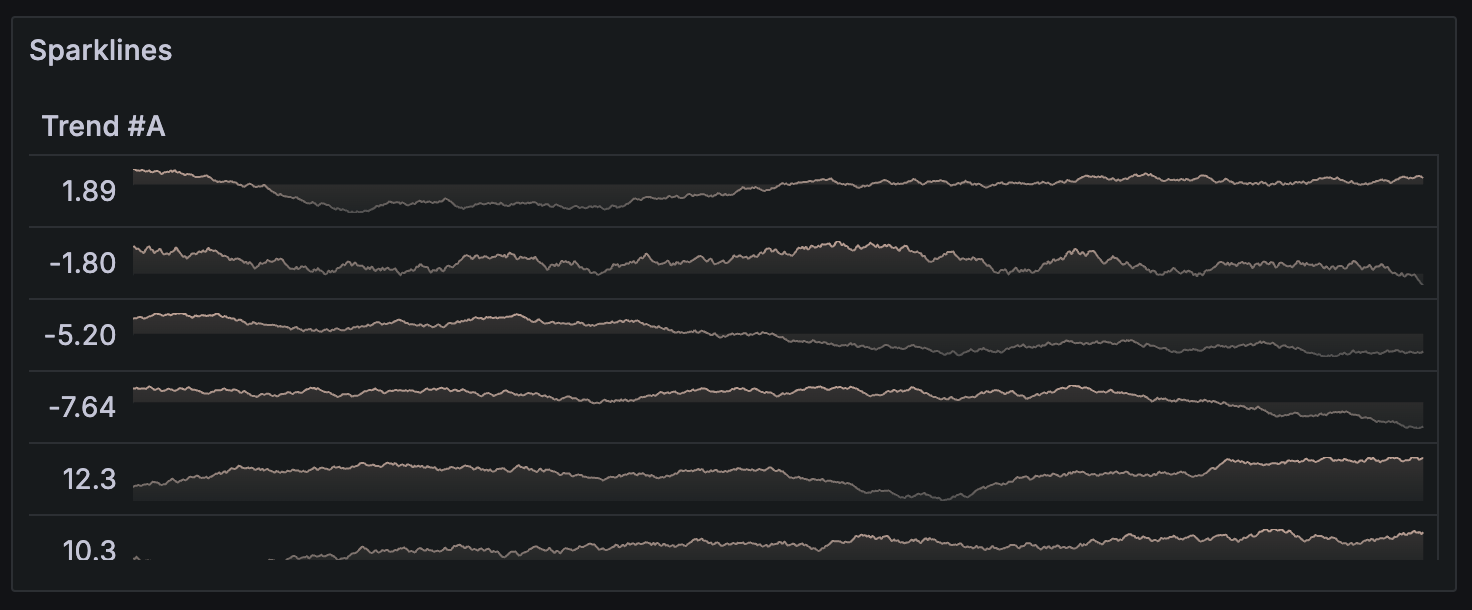
对于每个生成的趋势字段值,可以选择一个计算函数。此值显示在迷你图旁边,将用于排序表格行。
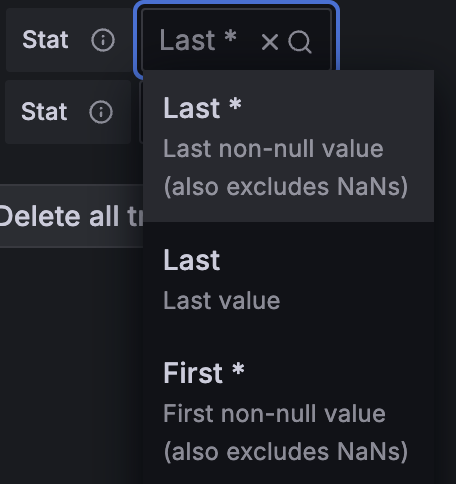
注意:此转换在 Grafana 9.5+ 中作为可选 Beta 功能提供。修改 Grafana 配置文件即可使用此功能。
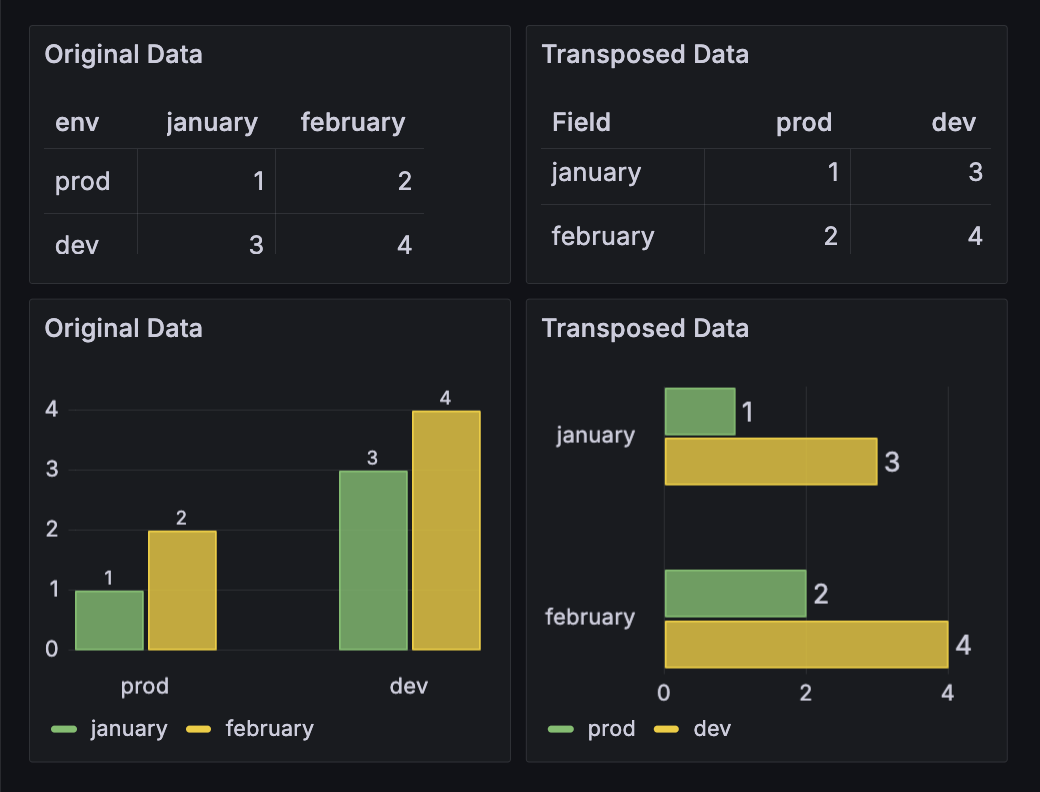
转置
使用此转换来旋转数据帧,将行转换为列,将列转换为行。当您想切换数据方向以更好地适应可视化需求时,此转换特别有用。如果存在多种类型,默认将转换为字符串类型。
转换前
| env | January | February |
|---|---|---|
| prod | 1 | 2 |
| dev | 3 | 4 |
应用转置转换后
| 字段 | prod | dev |
|---|---|---|
| January | 1 | 3 |
| February | 2 | 4 |
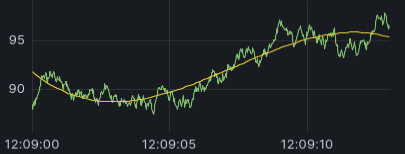
回归分析
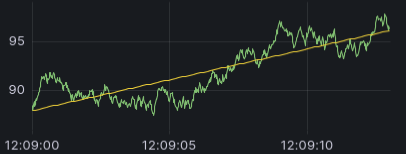
使用此转换创建包含统计模型预测值的新数据帧。这对于在混乱的数据中发现趋势非常有用。它通过使用线性或多项式回归将数学函数拟合到数据来实现。然后,该数据帧可用于可视化以显示趋势线。
有两种不同的模型
- 线性回归 - 将线性函数拟合到数据。
![A time series visualization with a straight line representing the linear function]()
- 多项式回归 - 将多项式函数拟合到数据。
![A time series visualization with a curved line representing the polynomial function]()
注意:此转换目前处于公开预览阶段。Grafana Labs 提供有限的支持,并且在功能正式发布之前可能会发生重大更改。在 Grafana 中启用
regressionTransformation功能开关即可使用此功能。请联系 Grafana 支持以在 Grafana Cloud 中启用此功能。