PostgreSQL 查询编辑器
Grafana 查询编辑器对于每个数据源都是唯一的。
有关 Grafana 查询编辑器的常规信息,请参阅查询编辑器。
有关在 Grafana 中查询数据源的常规信息,请参阅查询和转换数据。
PostgreSQL 查询编辑器位于探索页面。您也可以从仪表盘面板访问 PostgreSQL 查询编辑器。单击面板右上角的省略号并选择**编辑**。

PostgreSQL 查询编辑器组件
PostgreSQL 查询编辑器有两种模式:**构建器**和**代码**。
构建器模式可帮助您使用可视化界面构建查询。代码模式允许进行高级查询并支持编写复杂的 SQL 查询。
PostgreSQL 构建器模式
以下组件将帮助您构建 PostgreSQL 查询
- **格式** - 从下拉菜单中选择 PostgreSQL 查询的格式响应。默认值为**表**。如果您使用**时间序列**格式选项,其中一列必须是
time。有关详细信息,请参阅时间序列查询。 - **表** - 从下拉菜单中选择一个表。表对应于所选数据库。
- **数据操作** - 可选 从下拉菜单中选择一个聚合操作。您可以通过单击**+号**添加多个数据操作。单击**垃圾桶图标**移除数据操作。
- **列** - 选择要运行聚合操作的列。
- **别名** - 可选 从下拉菜单中添加别名。您也可以在框中输入自己的别名并单击**回车**。单击**X**移除别名。
- **过滤** - 切换以添加过滤器。
- **按列值过滤** - 可选 如果您切换**过滤**,可以从下拉菜单中添加要过滤的列。要过滤更多列,请单击条件下拉菜单右侧的**+号**。您可以从条件旁边的下拉菜单中选择各种运算符。添加多个过滤器时,您可以添加
AND运算符以显示所有为真的条件,或添加OR运算符以显示任何为真的条件。使用第二个下拉菜单选择一个过滤器。要移除过滤器,请单击该过滤器下拉菜单旁边的X按钮。选择日期类型列后,您可以从运算符列表中选择**宏**并选择timeFilter,这将使用选定的日期列向查询添加$__timeFilter宏。 - **分组** - 切换以添加**按列分组**。
- **按列分组** - 从下拉菜单中选择要过滤的列。单击**+号**按多列过滤。单击**X**移除过滤器。
- **排序** - 切换以添加
ORDER BY语句。 - **排序方式** - 从下拉菜单中选择要排序的列。选择升序 (
ASC) 或降序 (DESC)。 - **限制** - 您可以添加一个可选的限制来限制检索结果的数量。默认值为 50。
- **预览** - 切换以预览查询构建器生成的 SQL 查询。预览默认为启用。
PostgreSQL 代码模式
要创建高级查询,请单击编辑器窗口右上角的**代码**切换到**代码模式**。代码模式支持表、列、SQL 关键字、标准 SQL 函数、Grafana 模板变量和 Grafana 宏的自动补全。在指定表之前,无法补全列。
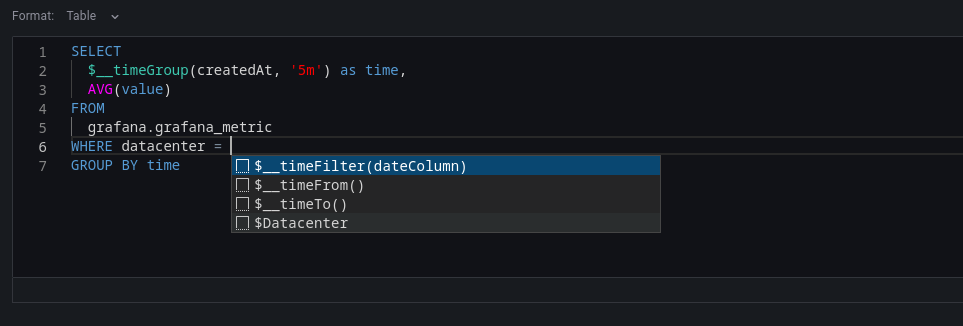
选择**表**或**时间序列**作为格式。单击右下角的 **{}** 格式化查询。单击**向下箭头**展开代码模式编辑器。**CTRL/CMD + 回车**是执行查询的键盘快捷键。
警告
在代码模式下对查询所做的更改不会转移到构建器模式,并将被丢弃。系统将提示您将代码复制到剪贴板以保存任何更改。
宏
您可以向查询中添加宏来简化语法并启用动态元素,例如日期范围过滤器。
| 宏示例 | 描述 |
|---|---|
$__time(dateColumn) | 将值替换为转换为 UNIX 时间戳的表达式,并将列重命名为 time_sec。示例:UNIX_TIMESTAMP(dateColumn) AS time_sec。 |
$__timeEpoch(dateColumn) | 将值替换为转换为 UNIX Epoch 时间戳的表达式,并将列重命名为 time_sec。示例:UNIX_TIMESTAMP(dateColumn) AS time_sec。 |
$__timeFilter(dateColumn) | 使用指定的列名替换时间范围过滤器。示例:dateColumn BETWEEN FROM_UNIXTIME(1494410783) AND FROM_UNIXTIME(1494410983) |
$__timeFrom() | 将值替换为当前活动时间选择的开始时间。示例:FROM_UNIXTIME(1494410783) |
$__timeTo() | 将值替换为当前活动时间选择的结束时间。示例:FROM_UNIXTIME(1494410983) |
$__timeGroup(dateColumn,'5m') | 将值替换为适合在 GROUP BY 子句中使用的表达式。示例:cast(cast(UNIX_TIMESTAMP(dateColumn)/(300) AS signed)*300 AS signed) |
$__timeGroup(dateColumn,'5m', 0) | 与 $__timeGroup(dateColumn,'5m') 宏相同,但包含一个填充参数,以确保 Grafana 添加序列中的缺失点,并使用 0 作为默认值。**这仅适用于时间序列查询。** |
$__timeGroup(dateColumn,'5m', NULL) | 与 $__timeGroup(dateColumn,'5m', 0) 相同,但 NULL 用作缺失点的值。_这仅适用于时间序列查询。_ |
$__timeGroup(dateColumn,'5m', previous) | 与 $__timeGroup(dateColumn,'5m', previous) 宏相同,但使用序列中的先前值作为填充值。如果不存在先前值,则使用 NULL。_这仅适用于时间序列查询。_ |
$__timeGroupAlias(dateColumn,'5m') | 将值替换为与 $__timeGroup 相同,但添加了列别名。 |
$__unixEpochFilter(dateColumn) | 使用指定的列名替换时间范围过滤器,其中时间表示为 UNIX 时间戳。示例:dateColumn > 1494410783 AND dateColumn < 1494497183 |
$__unixEpochFrom() | 将值替换为当前活动时间选择的开始时间,表示为 UNIX 时间戳。示例:1494410783 |
$__unixEpochTo() | 将值替换为当前活动时间选择的结束时间,表示为 UNIX 时间戳。示例:1494497183 |
$__unixEpochNanoFilter(dateColumn) | 使用指定的列名替换时间范围过滤器,其中时间表示为纳秒时间戳。示例:dateColumn > 1494410783152415214 AND dateColumn < 1494497183142514872 |
$__unixEpochNanoFrom() | 将值替换为当前活动时间选择的开始时间,表示为纳秒时间戳。示例:1494410783152415214 |
$__unixEpochNanoTo() | 将值替换为当前活动时间选择的结束时间,表示为纳秒时间戳。示例:1494497183142514872 |
$__unixEpochGroup(dateColumn,'5m', [fillmode]) | 与 $__timeGroup 相同,但用于存储为 Unix 时间戳的时间。fillMode 仅适用于时间序列查询。 |
$__unixEpochGroupAlias(dateColumn,'5m', [fillmode]) | 与 $__timeGroup 相同,但也会添加列别名。fillMode 仅适用于时间序列查询。 |
表 SQL 查询
如果将**格式**选项设置为**表**,则几乎可以执行任何类型的 SQL 查询。表面板将自动显示查询结果中的列和行。

您可以使用 SQL 关键字 AS 语法更改或自定义表面板列的名称。
SELECT
title as "Title",
"user".login as "Created By",
dashboard.created as "Created On"
FROM dashboard
INNER JOIN "user" on "user".id = dashboard.created_by
WHERE $__timeFilter(dashboard.created)时间序列查询
将**格式**选项设置为**时间序列**以创建并运行时间序列查询。
注意
要运行时间序列查询,您必须包含一个名为
time的列,该列返回 SQLdatetime值或表示 UNIX epoch 时间(秒)的数字数据类型。此外,查询结果必须按time列排序,以便在面板中正确可视化。
本节中的示例引用下表中的数据
+---------------------+--------------+---------------------+----------+
| time_date_time | value_double | CreatedAt | hostname |
+---------------------+--------------+---------------------+----------+
| 2020-01-02 03:05:00 | 3.0 | 2020-01-02 03:05:00 | 10.0.1.1 |
| 2020-01-02 03:06:00 | 4.0 | 2020-01-02 03:06:00 | 10.0.1.2 |
| 2020-01-02 03:10:00 | 6.0 | 2020-01-02 03:10:00 | 10.0.1.1 |
| 2020-01-02 03:11:00 | 7.0 | 2020-01-02 03:11:00 | 10.0.1.2 |
| 2020-01-02 03:20:00 | 5.0 | 2020-01-02 03:20:00 | 10.0.1.2 |
+---------------------+--------------+---------------------+----------+时间序列查询结果以宽数据帧格式返回。在数据帧查询结果中,除时间和字符串类型列外的任何列都转换为值字段。另一方面,字符串列成为字段标签。
注意
为了向后兼容,此规则有一个例外,适用于返回三列的查询,其中一列是名为
metric的字符串列。在这种情况下,`metric` 列不会转换为字段标签,而是用作字段名称,而序列名称设置为其值。请参阅以下示例作为参考。
带有 metric 列的示例
SELECT
$__timeGroupAlias("time_date_time",'5m'),
min("value_double"),
'min' as metric
FROM test_data
WHERE $__timeFilter("time_date_time")
GROUP BY time
ORDER BY time数据帧结果
+---------------------+-----------------+
| Name: time | Name: min |
| Labels: | Labels: |
| Type: []time.Time | Type: []float64 |
+---------------------+-----------------+
| 2020-01-02 03:05:00 | 3 |
| 2020-01-02 03:10:00 | 6 |
+---------------------+-----------------+要自定义默认序列名称格式,请参阅标准选项定义。
以下是时间序列查询示例。
使用 $__timeGroupAlias 宏中的填充参数将空值转换为零的示例
SELECT
$__timeGroupAlias("createdAt",'5m',0),
sum(value) as value,
hostname
FROM test_data
WHERE
$__timeFilter("createdAt")
GROUP BY time, hostname
ORDER BY time根据以下示例中的数据帧结果,时间序列面板将生成两个名为 _value 10.0.1.1_ 和 _value 10.0.1.2_ 的序列。要将序列名称显示为 _10.0.1.1_ 和 _10.0.1.2_,请使用标准选项定义显示值 ${__field.labels.hostname}。
数据帧结果
+---------------------+---------------------------+---------------------------+
| Name: time | Name: value | Name: value |
| Labels: | Labels: hostname=10.0.1.1 | Labels: hostname=10.0.1.2 |
| Type: []time.Time | Type: []float64 | Type: []float64 |
+---------------------+---------------------------+---------------------------+
| 2020-01-02 03:05:00 | 3 | 4 |
| 2020-01-02 03:10:00 | 6 | 7 |
+---------------------+---------------------------+---------------------------+带有多个列的示例
SELECT
$__timeGroupAlias("time_date_time",'5m'),
min("value_double") as "min_value",
max("value_double") as "max_value"
FROM test_data
WHERE $__timeFilter("time_date_time")
GROUP BY time
ORDER BY time数据帧结果
+---------------------+-----------------+-----------------+
| Name: time | Name: min_value | Name: max_value |
| Labels: | Labels: | Labels: |
| Type: []time.Time | Type: []float64 | Type: []float64 |
+---------------------+-----------------+-----------------+
| 2020-01-02 03:04:00 | 3 | 4 |
| 2020-01-02 03:05:00 | 6 | 7 |
+---------------------+-----------------+-----------------+模板化
您可以使用变量代替在指标查询中硬编码服务器、应用程序或传感器名称等值。变量显示为仪表盘顶部的下拉选择框。这些下拉菜单可以轻松更改仪表盘中显示的数据。
有关创建模板变量及其不同类型的介绍,请参阅模板。
查询变量
如果添加 Query 模板变量,您可以编写 PostgreSQL 查询来检索度量名称、键名称或键值等项目,这些项目将显示在下拉菜单中。
例如,您可以通过在模板变量 _Query_ 设置中创建以下查询来使用变量检索表中 hostname 列中的所有值。
SELECT hostname FROM host查询可以返回多列,Grafana 将根据查询结果自动生成列表。例如,以下查询返回一个包含 hostname 和 hostname2 值的列表。
SELECT host.hostname, other_host.hostname2 FROM host JOIN other_host ON host.city = other_host.city要使用依赖于时间范围的宏,例如 $__timeFilter(column),您必须将模板变量的刷新模式设置为_时间范围更改时_。
SELECT event_name FROM event_log WHERE $__timeFilter(time_column)另一种选择是能够创建键/值变量的查询。查询应返回两个名为 __text 和 __value 的列。__text 列必须包含唯一值(如果不是,则仅使用第一个值)。这允许下拉选项将文本友好的名称显示为文本,同时将 ID 用作值。例如,查询可以使用 hostname 作为文本,id 作为值
SELECT hostname AS __text, id AS __value FROM host您还可以创建嵌套变量。例如,如果您有一个名为 region 的变量,您可以配置 hosts 变量,使其仅显示当前所选区域内的所有主机,如以下示例所示。如果 region 是一个多值变量,请使用 IN 运算符而不是 = 来匹配多个值。
SELECT hostname FROM host WHERE region IN($region)在查询变量中使用 __searchFilter 过滤结果
在查询字段中使用 __searchFilter 可以根据用户在下拉选择框中的输入来过滤查询结果。如果您不输入任何内容,__searchFilter 的默认值为 %。
请注意,您必须将 __searchFilter 表达式用引号括起来,因为 Grafana 不会自动添加引号。
以下示例演示了如何在查询字段中使用 __searchFilter 以便用户在下拉选择框中输入时实时搜索 hostname。
SELECT hostname FROM my_host WHERE hostname LIKE '$__searchFilter'在查询中使用变量
只有当模板变量是 multi-value 时,模板变量值才会被引用。
如果变量是多值变量,请使用 IN 比较运算符代替 = 来匹配多个值。
您可以使用两种不同的语法
$ 示例,模板变量名为 hostname
SELECT
atimestamp as time,
aint as value
FROM table
WHERE $__timeFilter(atimestamp) and hostname in($hostname)
ORDER BY atimestamp ASC[[varname]] 示例,模板变量名为 hostname
SELECT
atimestamp as time,
aint as value
FROM table
WHERE $__timeFilter(atimestamp) and hostname in([[hostname]])
ORDER BY atimestamp ASC禁用多值变量的引用
Grafana 会自动将多值变量格式化为带引号的逗号分隔字符串。例如,如果选择了 server01 和 server02,则格式化为 `'server01'`、`'server02'`。要移除引号,请为变量启用 CSV 格式化选项
${servers:csv}
有关变量格式化选项的更多信息,请参阅变量文档。
注释
注释允许您在图表上方叠加丰富的事件信息。通过**仪表盘设置 > 注释视图**添加注释查询。
使用包含 epoch 值的 time 列的示例查询
SELECT
epoch_time as time,
metric1 as text,
concat_ws(', ', metric1::text, metric2::text) as tags
FROM
public.test_data
WHERE
$__unixEpochFilter(epoch_time)使用包含 epoch 值的 time 和 timeend 列的示例区域查询
SELECT
epoch_time as time,
epoch_time_end as timeend,
metric1 as text,
concat_ws(', ', metric1::text, metric2::text) as tags
FROM
public.test_data
WHERE
$__unixEpochFilter(epoch_time)使用包含原生 SQL 日期/时间数据类型的 time 列的示例查询
SELECT
native_date_time as time,
metric1 as text,
concat_ws(', ', metric1::text, metric2::text) as tags
FROM
public.test_data
WHERE
$__timeFilter(native_date_time)| 名称 | 描述 |
|---|---|
time | 日期/时间字段的名称,可以是具有原生 SQL 日期/时间数据类型或 epoch 值的列。 |
timeend | 结束日期/时间字段的可选名称,可以是具有原生 SQL 日期/时间数据类型或 epoch 值的列。 |
text | 事件描述字段。 |
tags | 用作事件标签的可选字段名称,格式为逗号分隔的字符串。 |
警报
使用时间序列查询创建警报。表格格式的查询尚不支持用于警报规则条件。
有关警报的更多信息,请参阅以下内容