处理 Grafana 告警中的缺失数据
缺失数据,或者当目标停止报告指标数据时,是排查告警问题时最常见的问题之一。在云原生环境中,这种情况经常发生——Pod 或节点根据需求缩减,或者整个 Job 悄然消失。
发生这种情况时,告警不会触发,你可能不会注意到系统已停止报告数据。
有时只是少数实例缺乏数据。有时则是连接问题,导致整个目标无法访问。
本指南涵盖了底层数据缺失的不同场景,以及如何设计你的告警来处理这些情况。如果你正在排查无法访问的主机或网络故障,请同时参阅处理连接错误。
无数据 (No Data) vs. 系列缺失 (Missing Series)
当实例停止报告数据时,有一些常见原因,类似于连接错误:
- 主机崩溃:系统宕机,Prometheus 停止抓取目标。
- 临时网络故障:间歇性抓取失败导致数据中断。
- 部署变更:停用、Kubernetes Pod 驱逐或资源缩减。
- 短暂性工作负载:指标有意停止报告。
- 等等。
首先要理解的是查询失败(或连接错误)、无数据 (No Data) 和 系列缺失 (Missing Series) 之间的区别。
告警查询通常会返回多个时间序列——每个实例、Pod、区域或标签组合对应一个。这被称为多维度告警,意味着一个告警规则可以触发多个告警实例(告警)。
例如,假设有一个记录的指标 http_request_latency_seconds,它报告应用程序部署区域的每秒延迟。该查询为每个区域返回一个序列——例如 region1 和 region2——并仅生成两个告警实例。在这种情况下,你可能会遇到:
- 如果告警规则查询失败,则为连接错误。
- 如果查询成功运行但完全没有返回数据,则为无数据 (No Data)。
- 如果之前返回数据的特定系列(一个或多个)缺失,而其他系列仍返回数据,则为系列缺失 (Missing Series)。
在 无数据 (No Data) 和 系列缺失 (Missing Series) 两种情况下,查询技术上仍然“有效”,但除非你明确配置了处理这些情况,否则告警不会触发。
让我们通过前面的示例来讲解这两种情况,其中告警在任何区域延迟超过 2 秒时触发:avg_over_time(http_request_latency_seconds[5m]) > 2
无数据 (No Data) 场景: 查询未返回任何序列的数据
| 时间 | region1 | region2 | 告警触发 |
|---|---|---|---|
| 00:00 | 1.5 秒 🟢 | 1 秒 🟢 | ✅ 无告警 |
| 01:00 | 无数据 ⚠️ | 无数据 ⚠️ | ⚠️ 无告警(静默失败) |
| 02:00 | 无数据 ⚠️ | 无数据 ⚠️ | ⚠️ 无告警(静默失败) |
| 03:00 | 1.4 秒 🟢 | 1 秒 🟢 | ✅ 无告警 |
系列缺失 (MissingSeries) 场景: 仅特定系列(region2)消失
| 时间 | region1 | region2 | 告警触发 |
|---|---|---|---|
| 00:00 | 1.5 秒 🟢 | 1 秒 🟢 | ✅ 无告警 |
| 01:00 | 1.6 秒 🟢 | 系列缺失 ⚠️ | ⚠️ 无告警(静默失败) |
| 02:00 | 1.6 秒 🟢 | 系列缺失 ⚠️ | ⚠️ 无告警(静默失败) |
| 03:00 | 1.4 秒 🟢 | 1 秒 🟢 | ✅ 无告警 |
在这两种情况下,都发生了静默故障。
在 Prometheus 中检测缺失数据
当查询没有返回数据时,Prometheus 不会触发告警。它只是简单地假设没有需要报告的内容,就像查询错误一样。缺失数据不会触发现有告警,除非你明确检查了它。
在 Prometheus 中,捕获缺失数据的一种常见方法是使用 absent_over_time 函数。
absent_over_time(http_request_latency_seconds[5m]) == 1
当 http_request_latency_seconds 的所有系列都缺失 5 分钟时,这会触发——捕获当整个指标消失时的 无数据 (No Data) 情况。
然而,absent_over_time() 无法检测哪些特定系列缺失,因为它不保留标签。告警不会告诉你哪些系列停止报告数据——只会告诉你查询没有返回数据。
如果你想按区域或标签检查缺失数据,可以在告警查询中按如下方式指定标签:
absent_over_time(http_request_latency_seconds{region="region1"}[5m]) == 1或absent_over_time(http_request_latency_seconds{region="region2"}[5m]) == 1
但这扩展性不好。为每个标签集硬编码查询是很脆弱的,尤其是在动态云环境中,实例可能随时出现或消失。
在 Grafana 告警中处理无数据
虽然 Prometheus 提供了 absent_over_time() 等函数来检测缺失数据,但并非所有可用于 Grafana 告警的数据源(如 Graphite、InfluxDB、PostgreSQL 等)都支持类似的功能。
为了处理这种情况,Grafana Alerting 实现了一个内置的 无数据 (No Data) 状态逻辑,这样你就无需使用 absent_* 查询来检测缺失数据。相反,你可以在告警规则设置中配置当未返回数据时告警的行为方式。
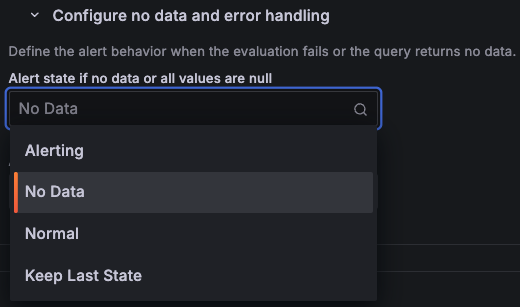
类似于错误处理,Grafana 默认会触发一个特殊的 无数据 (No data) 告警,并允许你控制此行为。在配置无数据和错误处理中,点击如果无数据或所有值为空时的告警状态,然后选择以下选项之一:
无数据 (No Data)(默认):触发一个新的
DatasourceNoData告警,将 无数据 视为一个特定问题。告警中 (Alerting): 当数据消失时,将每个现有告警实例转换为
告警中 (Alerting)状态。正常 (Normal):忽略缺失数据,并将所有实例转换为
正常 (Normal)状态。当接收到间歇性数据时(例如来自实验性服务、零星操作或定期报告),此选项很有用。保持上次状态 (Keep Last State):将告警保持在其先前的状态,直到数据返回。这在指标短暂中断经常发生的环境中很常见,例如不稳定的 exporter 或嘈杂环境。
![A screenshot of the `Configure no data handling` option in Grafana Alerting.]()
处理 DatasourceNoData 通知
当 Grafana 触发 无数据 (NoData) 告警时,它会创建一个独立的告警实例,与原始告警实例分开。这些告警行为有所不同:
- 它们使用一个专用的
alertname: DatasourceNoData。 - 它们不继承原始告警实例的所有标签。
- 它们立即触发,忽略待处理周期。
因此,DatasourceNoData 告警可能需要专门的设置来处理其通知。有关通用建议,请参阅减少冗余的 DatasourceError 告警——类似的做法也适用于 无数据 (NoData) 告警。
清理系列缺失的告警实例
当只有部分系列消失而不是全部时,会发生 系列缺失 (MissingSeries)。这种情况虽然细微,但很重要。
Grafana 在两个评估间隔后将缺失的系列标记为过期 (stale),并触发告警实例清理过程。以下是后台发生的情况:
- 缺失数据的告警实例会将其上次状态保持两个评估间隔。
- 如果在此之后仍然缺失
- Grafana 添加注释
grafana_state_reason: MissingSeries。 - 告警实例转换为
正常 (Normal)状态。 - 如果告警之前正在触发,则发送已解决通知。
- 告警实例将从 Grafana UI 中移除。
- Grafana 添加注释
如果告警实例过期,在它消失之前,你会在告警历史中看到 Normal (Missing Series)。下表显示了先前示例的清理过程:
| 时间 | region1 | region2 | 告警触发 |
|---|---|---|---|
| 00:00 | 1.5 秒 🟢 | 1 秒 🟢 | 🟢🟢 无告警 |
| 01:00 | 3 秒 🔴告警 | 3 秒 🔴告警 | 🔴🔴 两个区域都触发了告警实例 |
| 02:00 | 1.6 秒 🟢 | 系列缺失 ⚠️告警中 (Alerting) ️ | 🟢🔴 Region2 缺失,状态保持。 |
| 03:00 | 1.6 秒 🟢 | 系列缺失 ⚠️ 告警中 (Alerting)️ | 🟢🔴Region2 缺失,状态保持。 |
| 04:00 | 1.4 秒 🟢 | — | 🟢 🟢 region2 正常 (系列缺失),已解决,实例已清理;📩 通知已发送。 |
| 05:00 | 1.4 秒 🟢 | — | 🟢 无告警 |
为什么系列缺失 (MissingSeries) 不匹配无数据 (No Data) 的行为?
在动态环境(如自动扩缩组、短暂 Pod、竞价型实例)中,系列自然会来来往往。系列缺失 (MissingSeries) 通常表示基础设施或部署变更。
默认情况下,无数据 (No Data) 会触发告警,以指示潜在问题。
系列缺失 (MissingSeries) 的清理过程旨在防止 Pod 或实例消失时告警反复触发,从而减少告警噪音。
在频繁发生扩缩容的环境中,优先使用基于症状的告警,而非单个基础设施信号,并使用聚合告警,除非你明确需要跟踪单个实例。
处理系列缺失 (MissingSeries) 通知
过期告警实例在从触发状态(如 告警中 (Alerting)、无数据 (No Data) 或 错误 (Error))转换为 正常 (Normal) 时,会触发已解决通知。
你可以在通知中显示 MissingSeries 注释,以表明告警并非因恢复而解决,而是由于系列数据缺失而被清理。
审查这些通知,确认是否发生了故障或告警是否不必要。为了减少噪音:
- 在计划性维护或发布期间静默或关闭告警。
- 调整告警规则,避免对你预期会出现和消失的系列触发告警,而是使用聚合告警。
总结
缺失数据并非总是故障。在动态环境中,当某些目标停止报告数据时,这是一个常见场景。
Grafana Alerting 会自动处理不同的场景。以下是思考方式:
- 使用 Grafana 的 无数据 (No Data) 处理选项来定义查询未返回任何内容时发生的情况。
- 理解
DatasourceNoData和MissingSeries通知,因为它们的行为与常规告警不同。 - 在 Prometheus 中使用
absent()或absent_over_time()来精细检测指标或标签完全消失的情况。 - 默认情况下不要对每个实例都触发告警。在动态环境中,最好聚合并基于症状触发告警——除非缺失的单个实例直接影响用户。
- 如果你因数据消失而收到太多噪音,请考虑调整告警、使用
保持上次状态 (Keep Last State)或以不同方式路由这些告警。 - 对于涉及告警查询失败的连接问题,请参阅相关指南:处理 Grafana 告警中的连接错误。