处理告警中的连接错误
连接问题是导致误导性告警或未被发现的故障的常见原因之一。
可能你的目标离线了,或者 Prometheus 无法抓取它。又或者你的告警查询失败了,因为其目标超时或网络中断。这些情况可能看起来相似,但在告警设置中需要考虑不同的因素。
本指南将详细介绍如何检测和处理这些类型的故障,无论你是在 Prometheus 中编写告警规则、使用 Grafana Alerting 还是两者结合使用。它涵盖了可用性监控和告警查询故障,并概述了提高告警可靠性的策略。
理解告警中的连接问题
通常,连接问题属于以下几种常见场景
- 服务器或容器崩溃或已关闭。
- 服务过载或超时。
- 身份验证配置错误或权限不正确。
- 网络问题,如 DNS 问题或 ISP 中断。
当讨论告警中的连接错误时,通常指以下两种用例之一
你的目标宕机或不可达。
服务崩溃、主机宕机,或防火墙或 DNS 问题阻止了连接。这些是可用性问题。你的告警查询失败。
告警无法评估其查询——可能是因为数据源超时或查询无效。这些是执行错误。
尽早区分这些情况会有所帮助,因为它们的表现不同,需要不同的策略。
请记住,大多数告警规则不会直接命中目标。它们从像 Prometheus 这样的监控系统中查询指标,Prometheus 从你的实际基础设施或应用中抓取数据。这带来了两种典型的告警设置,其中可能会出现连接问题
告警规则 → 目标
例如,查询外部数据源(如数据库)的告警规则。告警规则 → Prometheus ← 目标
在可观测性技术栈中更常见。例如,Prometheus 抓取节点或容器数据,然后告警规则稍后查询指标。在第二种设置中,你可能会在任意一侧遇到连接问题。如果 Prometheus 未能抓取到目标,你的告警规则可能不会触发,即使很可能有问题发生。
使用 Prometheus 的 up 指标检测目标可用性
Prometheus 定期根据 scrape_interval 周期从其目标抓取指标。默认的抓取间隔是 60 秒,这通常被认为是常见做法。
Prometheus 为每个抓取目标提供了一个内置指标 up,这是指示抓取是否成功的简单方法
up == 1:你的目标可达;Prometheus 按预期收集了目标指标。up == 0:Prometheus 无法到达你的目标——表示可能宕机或出现网络错误。
检测目标不可达的典型 PromQL 告警规则表达式是
up == 0
但是这个告警规则可能会导致告警噪声,因为一次短暂的故障(一次抓取失败)就会触发告警。为了减少噪声,你应该增加一个延迟
up == 0 for: 5m
Prometheus 中的 for 选项(或 Grafana 中的待处理周期)会延迟告警,直到条件在整个持续时间内都为真。
在此示例中,等待 5 分钟有助于跳过临时故障。由于 Prometheus 默认每分钟抓取一次指标,告警仅在连续五次抓取失败后触发。
然而,这种 up 告警有一些注意事项
- 故障可能发生在抓取间隔之间:两次评估之间开始和结束的中断将不被检测到。你可以缩短
for持续时间,但这可能导致临时故障触发误报。 - 间歇性恢复会重置
for计时器:一次成功的抓取会重置告警计时器,掩盖间歇性中断。
短暂的连接中断在实际环境中很常见,因此预计 up 告警会有些不稳定。例如
抓取结果 (up) | 告警规则评估 |
|---|---|
00:00 up == 0 | 计时器开始 |
01:00 up == 0 | 计时器继续 |
02:00 up == 0 | 计时器继续 |
03:00 up == 1 | 成功抓取重置计时器 |
04:00 up == 0 | 计时器重新开始 |
05:00 up == 0 | 尚未告警——计时器未达到 for 持续时间 |
周期越长,这种情况越有可能发生。
一次恢复就会重置告警,这就是为什么 up == 0 for: 5m 有时可能不可靠的原因。即使目标大部分时间都处于宕机状态,告警也不会触发,让你无法知晓潜在的持续问题。
使用 avg_over_time
解决这些问题的一种方法是通过在相似或更长的时间段内平均 up 指标来平滑信号
avg_over_time(up[10m]) < 0.8
当目标在过去 10 分钟内不可达时间超过 20% 时,此告警规则就会触发,而不是寻找连续的抓取失败。如果抓取间隔为一分钟,过去 10 分钟内三次或更多次抓取失败现在会触发告警。
由于此查询使用阈值和时间窗口来控制准确性,你现在可以缩短 for 持续时间(或 Grafana 中的待处理周期)至更短的值——0m 或 1m——以便告警更快地触发。
这种方法让你在检测实际崩溃或网络问题时更具灵活性。一如既往,请根据你的噪声容忍度和目标的关键程度调整阈值和周期。
使用合成检查监控外部可用性
Prometheus 通常与其监控的目标运行在同一网络中。这意味着 Prometheus 可能能够到达目标,但这并不能确保外部用户能够到达它。
防火墙、DNS 配置错误或其他网络问题可能会阻止公共流量,而 Prometheus 同时成功抓取 up 指标。
这时合成监控就派上用场了。像Blackbox Exporter 这样的工具让你能够持续验证服务是否可用以及是否可以从网络外部访问——而不仅仅是内部访问。
Blackbox Exporter 将这些检查的结果作为指标暴露出来,Prometheus 可以像抓取其他任何目标一样抓取这些指标。例如,probe_success 指标报告探测是否能够到达服务。设置如下
告警规则 → Prometheus ← Blackbox Exporter (外部探测) → 目标
要检测服务何时无法从外部访问,你可以使用 probe_success 指标定义告警
probe_success == 0 for: 5m
当探测连续失败 5 分钟时,此告警会触发——表明服务无法从外部访问。
然后,你可以结合内部和外部检查,使连接错误的检测更加可靠。此告警可以捕获内部抓取失败或服务外部不可达的情况。
up == 0 or probe_success == 0
与 up 指标一样,你可能希望使用 avg_over_time() 来平滑它,以便进行更可靠的检测。平滑后的版本可能看起来像
avg_over_time(up[10m]) < 0.8 or avg_over_time(probe_success[10m]) < 0.8
当 Prometheus 在过去 10 分钟内成功抓取目标的次数不足 80%(即失败超过 20%)时,或者当外部探测失败时间超过 20% 时,此告警就会触发。这种平滑技术可以应用于任何二进制可用性信号。
当只有部分主机停止上报数据时
在许多设置中,Prometheus 会在同一目标下抓取多个主机的数据——例如,共享同一个 job 标签的一组服务器或容器。主机离线而其他主机继续正常上报指标的情况很常见。
如果你的告警仅检查 umum up 指标而不按标签(如 instance、host 或 pod)进行细分,你可能会错过某些主机停止上报的情况。例如,一个仅查看所有实例聚合状态的告警很可能无法发现单个实例丢失的情况。
这在这种情况下不是连接错误——不是告警或 Prometheus 无法访问任何东西,而是有一个或多个特定目标变得静默了。这类问题不会被 up == 0 告警捕获到。
对于这些情况,请参阅补充指南处理缺失数据——它涵盖了告警查询完全没有返回数据,或者只有部分目标停止上报数据的常见场景。这些不是完全的可用性故障或执行错误,但仍然可能导致告警检测出现盲点。
处理 Grafana Alerting 中的查询错误
并非所有连接问题都源于目标离线。有时,告警规则在查询其目标时会失败。这些不是可用性问题——它们是查询执行错误:可能是数据源超时、网络断开或查询无效。
这些错误会导致告警失效。但它们来自技术栈中不同的部分:在告警规则和数据源之间,而不是在数据源(例如 Prometheus)和其目标之间。
这个区别很重要。可用性问题通常使用像 up 或 probe_success 这样的指标来处理,而执行错误需要不同的设置。
Grafana Alerting 提供了内置的执行错误处理功能,无论数据源类型如何,包括 Prometheus 以及 Graphite、InfluxDB、PostgreSQL 等。默认情况下,Grafana Alerting 会自动处理查询错误,因此你不会错过关键故障。当告警规则执行失败时,Grafana 会触发一个特殊的 DatasourceError 告警。
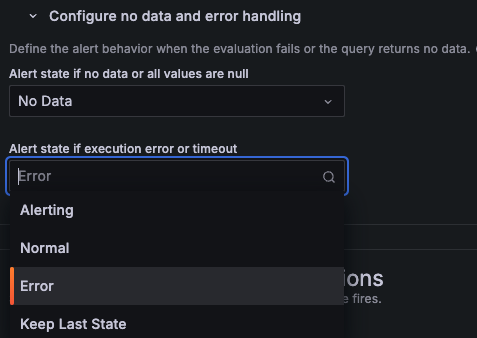
你可以根据告警的关键程度以及是否已有其他告警检测到该问题来配置此行为。在配置无数据和错误处理中,点击执行错误或超时时的告警状态,然后为告警选择所需选项
错误(默认):触发单独的
DatasourceError告警。此默认设置确保告警规则始终告知查询错误,但也可能产生噪声。告警中:将错误视为告警条件正在触发。Grafana 将该规则的所有现有实例转换为
Alerting状态。正常:忽略查询错误,并将所有告警实例转换为
Normal状态。如果错误不关键,或者你已经有其他告警来检测连接问题,这会很有用。保持上次状态:保持之前的状态,直到查询再次成功。适用于不稳定环境,避免告警闪烁。
![A screenshot of the `Configure error handling` option in Grafana Alerting.]()
即使告警规则查询的是 Prometheus 本身,而不仅仅是外部数据源,这也适用。
设计连接错误告警
实践中,首先决定是否要创建明确的告警规则——例如,使用 up 或 probe_success——来检测目标何时宕机或存在连接问题。
然后,对于每个告警规则,根据你是否已有专门的连接告警、目标的稳定性以及告警的关键程度来选择错误处理行为。根据症状的严重性来优先处理告警,而不是仅仅基于可能不影响用户的基础设施信号。
减少冗余错误通知
单个数据源错误可能导致多个告警同时触发,有时会给你带来大量告警并产生过多噪声。
如前所述,你可以控制 Grafana 告警的错误处理行为。保持上次状态或正常选项可以阻止告警触发,并有助于避免冗余告警,特别是对于已经由 up 或 probe_success 告警覆盖的服务。
使用默认行为时,单个连接错误很可能会触发多个 DatasourceError 告警。
这些告警与原始告警是分开的——它们不仅仅是原始告警的不同状态。它们会立即触发,忽略待处理周期,并且不继承所有标签。如果你期望它们表现得像原始告警一样,这可能会让你措手不及。
考虑不要以对待原始告警相同的方式处理这些告警,并为其通知实现专门的策略
通过对
DatasourceError告警进行分组来减少重复通知。使用datasource_uid标签对来自同一数据源的错误进行分组。将
DatasourceError告警分开路由,根据其影响和紧急程度发送给不同的团队或渠道。
有关如何配置分组和路由的详细信息,请参阅处理通知和无数据和错误告警文档。
总结
连接问题是导致告警噪声过多或具有误导性的常见原因之一。本指南涵盖了两种不同的类型
可用性问题,即目标本身宕机或不可达(例如,由于崩溃或网络故障)。
查询执行错误,即告警规则无法访问其数据源(例如,由于超时、无效查询或数据源中断)。
这些问题来自技术栈中不同的部分,需要各自的技术来处理。Prometheus 和 Grafana 都允许你检测它们,结合不同的技术可以使你的告警更具弹性。
使用 Prometheus 时,避免完全依赖 up == 0。平滑查询以应对间歇性故障,并使用合成监控检测来自网络外部的可达性问题。
在 Grafana Alerting 中,明确配置错误处理。并非所有告警都同等重要或具有相同的紧急程度。根据告警的可靠性和严重性以及你是否已有专门针对连接问题的告警来调整错误处理行为。
并且不要忘记第三种情况:缺失数据。如果集群中的单个主机悄悄消失,你可能不会收到告警。如果你正在处理停止上报数据的单个实例,请参阅处理缺失数据指南以继续探索此主题。