
部署 Grafana Alloy
Alloy 是一款灵活的、厂商中立的遥测收集器。这种灵活性意味着 Alloy 不强制采用特定的部署拓扑结构,而可以在多种场景下工作。
本页列出了 Alloy 部署常用的拓扑结构,以及何时考虑使用每种拓扑结构、可能遇到的问题以及扩展注意事项。
作为集中式收集服务
建议将 Alloy 作为集中式服务部署,用于收集应用程序遥测数据。这种拓扑结构允许您使用少量收集器来协调服务发现、收集和远程写入。
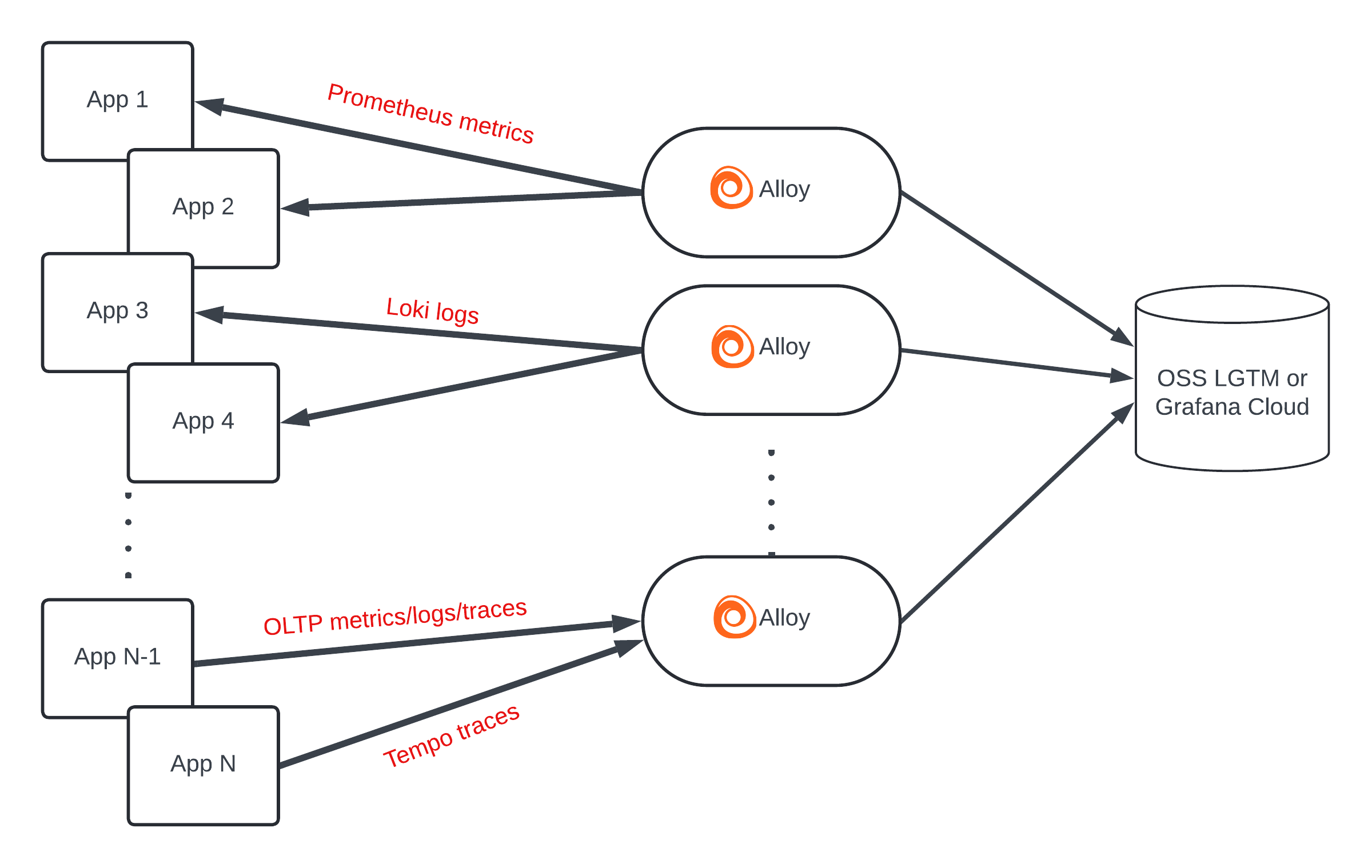
使用这种拓扑结构需要在独立的 инфраструк 上部署 Alloy,并确保它们能够通过网络发现并访问这些应用程序。Alloy 部署规模的主要预测因素是它正在抓取的活动 Prometheus 指标序列的数量。一个经验法则式是每个序列大约需要 10 KB 内存。我们建议您在活动序列达到 100 万个左右时开始考虑横向扩展。
使用 Kubernetes StatefulSets
建议将 Alloy 作为 StatefulSet 部署,用于 Prometheus 指标收集。持久化的 Pod 标识符使得能够一致地将卷与 Pod 匹配,以便您可以使用它们作为 WAL 目录。
在不需要持久化存储的情况下,例如仅处理追踪数据的 pipeline,您也可以使用 Kubernetes Deployment。
优点
- 使用集群进行直接扩展
- 最大程度地减少“嘈杂邻居”效应
- 易于元监控
缺点
- 需要在独立的 infrastructure 上运行
适用于
- 可扩展的遥测收集
不适用于
- 主机级别指标和日志
作为主机守护程序
每台机器部署一个 Alloy 实例是收集机器级别 Prometheus 指标和日志所必需的,例如 node_exporter 硬件和网络指标或 journald 系统日志。
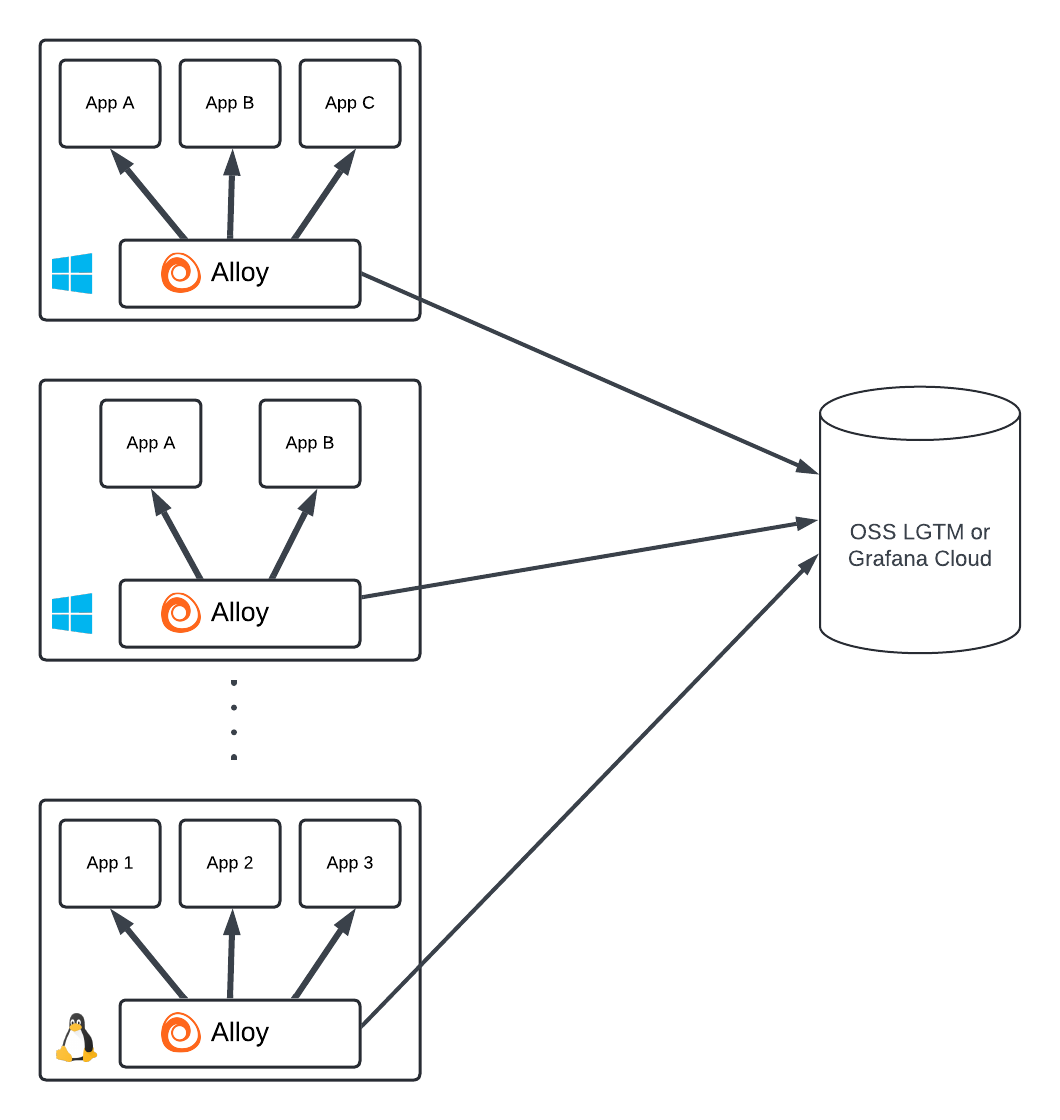
每个 Alloy 实例都需要为每个发送数据的远程端点打开一个出站连接。这可能导致出口基础设施上的 NAT 端口耗尽。每个出口 IP 在不同端口上最多可以支持 (65535 - 1024 = 64511) 个出站连接。因此,如果所有 Alloy 都在发送 Prometheus 指标和日志数据,一个出口 IP 最多可以支持 32,255 个收集器。
使用 Kubernetes DaemonSets
主机守护程序拓扑结构最简单的用例是 Kubernetes DaemonSet,它对于节点级别可观测性(例如 cAdvisor 指标)和收集 Pod 日志是必需的。
优点
- 无需在独立的 infrastructure 上运行
- 通常会产生更小规模的收集器
- 到被插桩应用程序的网络延迟更低
缺点
- 需要规划在新机器上配置 Alloy 的流程,并保持配置最新以避免配置漂移
- 使用 Kubernetes DaemonSets 时无法独立扩展
- 扩展此拓扑结构可能会给外部 API(如服务发现)和网络基础设施(如防火墙、代理服务器和出口点)带来压力
适用于
- 收集机器级别 Prometheus 指标和日志(例如,node_exporter 硬件指标、Kubernetes Pod 日志)
不适用于
- Alloy 规模变得非常大而可能成为嘈杂邻居的场景
- 收集不可预测的遥测数据量
作为容器 Sidecar
仅建议将 Alloy 作为容器 Sidecar 部署,用于生命周期较短的应用程序或专门的 Alloy 部署。
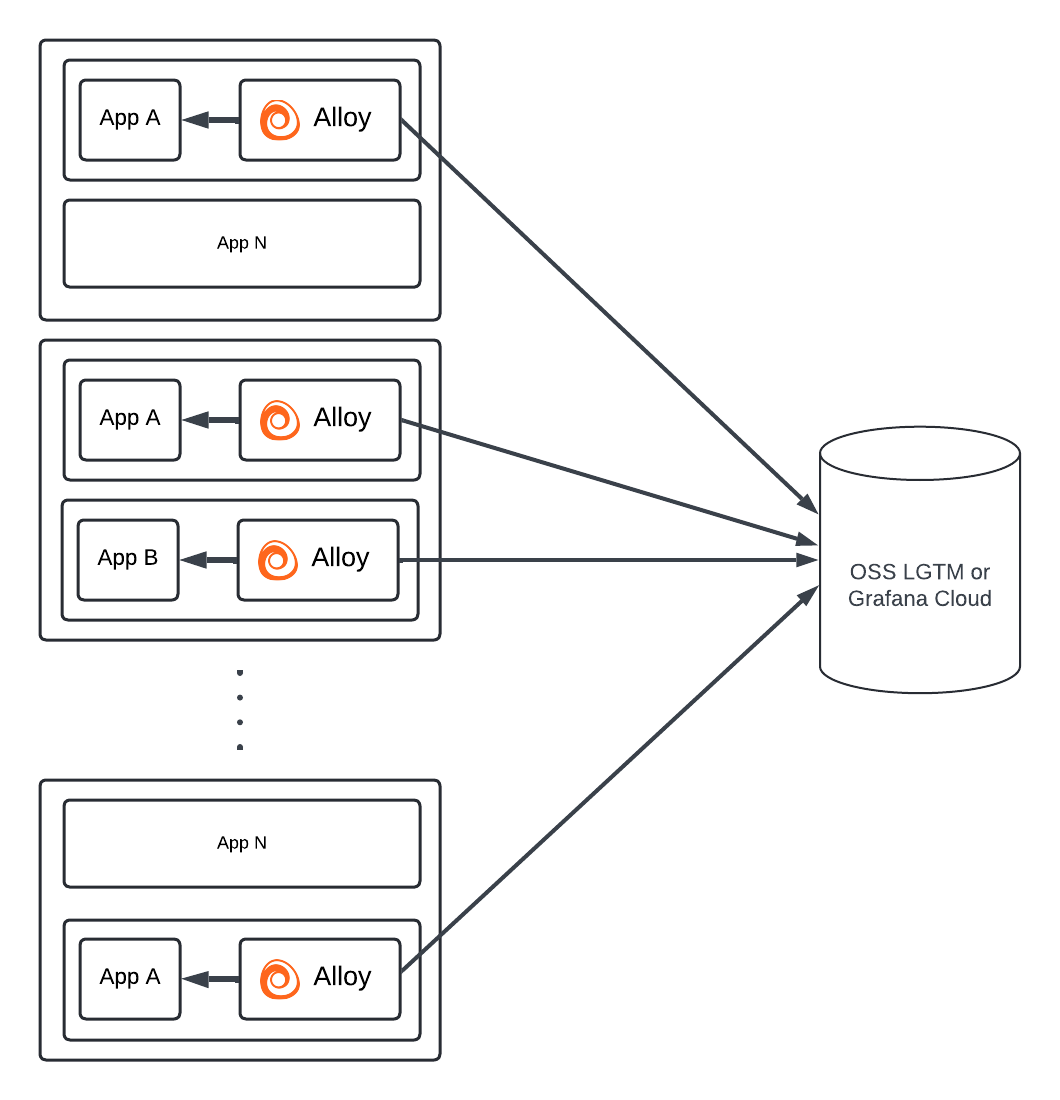
使用 Kubernetes Pod Sidecars
在 Kubernetes 环境中,Sidecar 模型包括在 Pod 上将 Alloy 作为额外的容器部署。Pod 的控制器、网络配置、启用的能力和可用资源在实际应用程序和 Sidecar Alloy 之间共享。
优点
- 无需在独立的 infrastructure 上运行
- 与伙伴应用程序的网络连接直接简便
缺点
- 无法单独扩展
- 使资源消耗更难监控和预测
- 每个 Alloy 实例没有自己的生命周期,这使得从网络中断等情况中恢复变得更加困难
适用于
- 无服务器服务
- 使用推送模型工作的作业/批处理应用程序
- 无法通过网络访问的隔离应用程序
不适用于
- 长时间运行的应用程序
- Alloy 部署规模变得非常大而可能成为嘈杂邻居的场景
在不同的 Alloy 实例中处理不同类型的遥测数据
如果 Alloy 的负载很小,您可以在同一个 Alloy 进程中处理所有必要的遥测信号。例如,单个 Alloy 部署可以处理所有传入的指标、日志、追踪和分析数据。
但是,如果 Alloy 的负载很大,在不同的 Alloy 部署中处理不同的遥测信号可能会更有益。
这提供了更好的稳定性,因为进程之间是隔离的。例如,处理追踪数据的过载 Alloy 实例不会影响处理指标的 Alloy 实例。不同类型的信号收集需要不同的扩展方法
- “Pull” 组件,如
prometheus.scrape和pyroscope.scrape,使用哈希模共享或集群进行扩展。 - “Push” 组件,如
otelcol.receiver.otlp,通过在组件前放置负载均衡器进行扩展。
追踪
用于追踪的 Alloy 实例的扩展与 OpenTelemetry Collector 实例的扩展非常相似。这种相似性是因为大多数用于追踪的 Alloy 组件都是基于 OTel Collector 的组件。
何时扩展
要决定是否需要扩展,请检查以下指标,例如
- 从接收器(如
otelcol.receiver.otlp)获取的otelcol_receiver_refused_spans_total。 - 从处理器(如
otelcol.processor.batch)获取的otelcol_receiver_refused_spans_total。 - 从导出器(如
otelcol.exporter.otlp和otelcol.exporter.loadbalancing)获取的otelcol_exporter_send_failed_spans_total。
有状态和无状态组件
在追踪的背景下,“有状态组件”是指需要聚合某些 Span 才能正常工作的组件。“无状态 Alloy”是指不包含有状态组件的 Alloy 实例。
扩展有状态的 Alloy 实例更困难,因为必须根据 Span 属性(例如 Trace ID 或一个 service.name 属性)将 Span 转发到特定的 Alloy 实例。您可以使用 otelcol.exporter.loadbalancing 来转发 Span。
有状态组件示例
otelcol.processor.tail_samplingotelcol.connector.spanmetricsotelcol.connector.servicegraph
“无状态组件”不需要聚合特定的 Span 即可正常工作。即使它只包含 Trace 的一部分 Span,也能正常工作。
无状态 Alloy 实例无需使用 otelcol.exporter.loadbalancing 即可扩展。例如,您可以使用现成的负载均衡器进行轮询负载均衡。
无状态组件示例
otelcol.processor.probabilistic_samplerotelcol.processor.transformotelcol.processor.attributesotelcol.processor.span
此页面有帮助吗?
来自 Grafana Labs 的相关资源


