构建流式数据源插件
本教程将教您如何使用 create-plugin 工具和示例源代码构建 Grafana 流式数据源插件。
流式数据源插件仅在数据源中有新数据可用时刷新插件中的数据。这种方法与仪表盘设置为按指定间隔自动刷新的典型方法不同。流式传输的主要优势在于,它消除了每次需要更新数据时重新运行查询的开销。
本教程展示了如何创建一个包含前端和后端的数据源后端插件。完成本教程后,您将构建一个插件,该插件在后端生成随机数,并作为可视化效果返回给前端。
示例截图和代码
下图显示了一个使用此数据源的面板
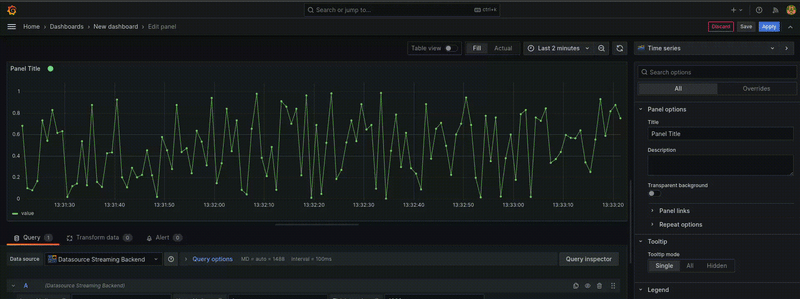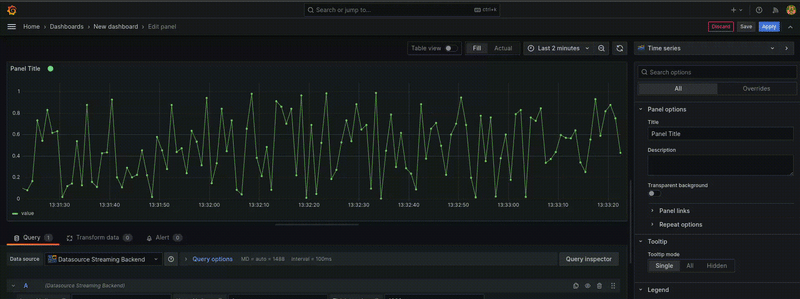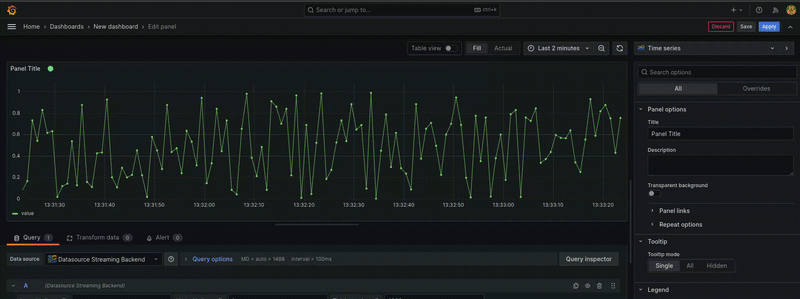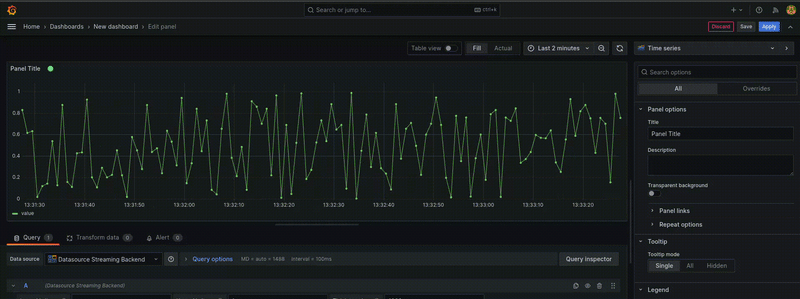
步骤 1:搭建插件框架
您可以从头开始创建所有插件代码,只要您遵循 Grafana 插件规范并实现所有必要的接口。然而,创建插件最简单的方法是使用我们提供的 @grafana/create-plugin 工具。
- 进入您希望创建插件目录的位置并运行
npx @grafana/create-plugin@latest
有关设置开发环境的完整先决条件列表和建议,请参阅开始使用。
Create Plugin 工具将提示您回答有关插件名称和类型、您的组织以及许多其他选项的问题。
- 对于本教程,在插件类型中输入
data source,并指定它包含后端部分。
该工具将创建一个包含所有必要代码和依赖项的骨架,用于运行数据源后端插件。如果您编译代码,您将得到一个非常简单的后端插件。但是,生成的代码还不是一个流式插件,我们需要进行一些修改。
步骤 2:设置前端
由于我们希望将一些参数传递给插件的后端部分,我们首先修改 /src/components/QueryEditor.tsx。此组件定义了用户可以提供给查询的输入。我们将添加三个数字输入,用于生成我们的数据
tickInterval- 数据生成间隔upperLimit- 随机数的上限lowerLimit- 随机数的下限
为此,请按照以下步骤操作。
- 将
/src/components/QueryEditor.tsx中的QueryEditor函数替换为以下代码
export function QueryEditor({ query, onChange, onRunQuery }: Props) {
const onLowerLimitChange = (event: ChangeEvent<HTMLInputElement>) => {
onChange({ ...query, lowerLimit: event.target.valueAsNumber });
};
const onUpperLimitChange = (event: ChangeEvent<HTMLInputElement>) => {
onChange({ ...query, upperLimit: event.target.valueAsNumber });
};
const onTickIntervalChange = (event: ChangeEvent<HTMLInputElement>) => {
onChange({ ...query, tickInterval: event.target.valueAsNumber });
};
const { upperLimit, lowerLimit, tickInterval } = query;
return (
<>
<InlineField label="Lower Limit" labelWidth={16} tooltip="Random numbers lower limit">
<Input onChange={onLowerLimitChange} onBlur={onRunQuery} value={lowerLimit || ''} type="number" />
</InlineField>
<InlineField label="Upper Limit" labelWidth={16} tooltip="Random numbers upper limit">
<Input onChange={onUpperLimitChange} onBlur={onRunQuery} value={upperLimit || ''} type="number" />
</InlineField>
<InlineField label="Tick interval" labelWidth={16} tooltip="Server tick interval">
<Input onChange={onTickIntervalChange} onBlur={onRunQuery} value={tickInterval || ''} type="number" />
</InlineField>
<>
);
}
- 在
src/datasource.ts文件中,通过流通道指示一个查询。此文件是插件前端部分执行查询的位置。将以下方法添加到DataSource类中
query(request: DataQueryRequest<MyQuery>): Observable<DataQueryResponse> {
const observables = request.targets.map((query, index) => {
return getGrafanaLiveSrv().getDataStream({
addr: {
scope: LiveChannelScope.DataSource,
namespace: this.uid,
path: `my-ws/custom-${query.lowerLimit}-${query.upperLimit}-${query.tickInterval}`, // this will allow each new query to create a new connection
data: {
...query,
},
},
});
});
return merge(...observables);
}
调用 getGrafanaLiveSrv() 返回对 Grafana 后端的引用,而 getDataStream 调用则创建流。如本代码片段所示,我们需要提供一些数据来创建流
scope- 定义通道如何使用和控制(指定data source)namespace- 我们特定数据源的唯一标识符path- 用于区分由同一数据源创建的不同通道的部分。在此示例中,我们希望为每个查询创建一个不同的通道,因此我们将使用查询参数作为 path 的一部分。data- 用于在前端和后端之间交换信息
值得一提的是,path 也可以用于与后端部分交换数据,但对于复杂格式,请使用 data 属性。
流由参数组合唯一标识,其格式为:${scope}/${namespace}/${path}。这仅是一个实现细节,除了调试之外,您可能不需要了解这一点。
步骤 3:设置插件后端
现在我们需要在后端添加必要的代码。为此,我们修改 pkg/plugin/datasource.go,这里定义了负责处理前端创建的查询的后端部分。在我们的例子中,由于我们希望处理流,因此需要实现 backend.StreamHandler。
- 在替换
var的部分添加以下内容
var (
_ backend.CheckHealthHandler = (*Datasource)(nil)
_ instancemgmt.InstanceDisposer = (*Datasource)(nil)
_ backend.StreamHandler = (*Datasource)(nil)
)
这意味着我们的 DataSource 将实现 backend.CheckHealthHandler、instancemgmt.InstanceDisposer 和 backend.StreamHandler。前两个所需的方已在框架中提供;因此,我们只需实现 backend.StreamHandler 所需的方法。
- 首先添加
SubscribeStream方法
func (d *Datasource) SubscribeStream(context.Context, *backend.SubscribeStreamRequest) (*backend.SubscribeStreamResponse, error) {
return &backend.SubscribeStreamResponse{
Status: backend.SubscribeStreamStatusOK,
}, nil
}
当用户尝试订阅通道时,将调用此代码。您可以在此处实现权限检查,但在我们的例子中,我们只希望用户在每次尝试时都能成功连接;因此,我们只需返回一个后端状态:SubscribeStreamStatusOK。
- 实现
PublishStream方法
func (d *Datasource) PublishStream(context.Context, *backend.PublishStreamRequest) (*backend.PublishStreamResponse, error) {
return &backend.PublishStreamResponse{
Status: backend.PublishStreamStatusPermissionDenied,
}, nil
}
每当用户尝试发布到通道时,都会调用此代码。由于我们在创建第一个连接后不希望从前端接收任何数据,因此我们只会返回一个 backend.PublishStreamStatusPermissionDenied。
- 为防止出现随机错误,请将默认提供的
CheckHealth方法更改为以下代码
func (d *Datasource) CheckHealth(_ context.Context, req *backend.CheckHealthRequest) (*backend.CheckHealthResult, error) {
return &backend.CheckHealthResult{
Status: backend.HealthStatusOk,
Message: "Data source is working",
}, nil
}
请注意,此代码与流式插件本身无关。它只是为了避免因未更改默认设置而导致的随机错误。
- 最后,实现
RunStream方法
func (d *Datasource) RunStream(ctx context.Context, req *backend.RunStreamRequest, sender *backend.StreamSender) error {
q := Query{}
json.Unmarshal(req.Data, &q)
s := rand.NewSource(time.Now().UnixNano())
r := rand.New(s)
ticker := time.NewTicker(time.Duration(q.TickInterval) * time.Millisecond)
defer ticker.Stop()
for {
select {
case <-ctx.Done():
return ctx.Err()
case <-ticker.C:
// we generate a random value using the intervals provided by the frontend
randomValue := r.Float64()*(q.UpperLimit-q.LowerLimit) + q.LowerLimit
err := sender.SendFrame(
data.NewFrame(
"response",
data.NewField("time", nil, []time.Time{time.Now()}),
data.NewField("value", nil, []float64{randomValue})),
data.IncludeAll,
)
if err != nil {
Logger.Error("Failed send frame", "error", err)
}
}
}
}
实现后,此方法将针对每个连接调用一次,在这里我们可以解析前端发送的数据,以便 Grafana 可以连续发送数据。在此特定示例中,我们将使用前端发送的数据来定义发送帧的频率以及生成的随机数的范围。
因此,方法的第一部分解析数据,并将查询定义为一个 struct。
- 将以下代码添加到
./pkg/plugin/query.go中
type Query struct {
UpperLimit float64 `json:"upperLimit"`
LowerLimit float64 `json:"lowerLimit"`
TickInterval float64 `json:"tickInterval"`
}
在此示例中,我们正在创建一个定时器(ticker)和一个基于此定时器的无限循环。每当定时器超时时,我们将进入 select 的第二个 case,并生成一个随机数 randomValue。然后,我们将使用 data.NewFrame 创建一个数据帧(data frame),其中包含 randomValue 和当前时间,并使用 sender.SendFrame 发送它。此循环将无限期运行,直到我们关闭通道。
您可以删除由框架创建的 QueryData 方法以及与其相关的所有代码,因为我们不再实现后端 QueryDataHandler。
步骤 4:修改 plugin.json
Grafana 在首次加载时需要识别新插件是流式插件。为此,只需将 "streaming":true 属性添加到您的 src/plugin.json 文件中。它应如下所示
{
...
"id": "grafana-streamingbackendexample-datasource",
"metrics": true,
"backend": true,
...
"streaming": true
}
步骤 5:构建插件
插件开发过程的编码部分已完成。现在我们需要生成插件包以便在 Grafana 中运行它。由于我们的插件包含前端和后端两部分,因此我们需要分两步进行。
- 构建前端
npm install
npm run build
这将下载所有依赖项并在 ./dist 目录中创建前端插件文件。
- 编译后端代码并生成插件二进制文件。为此,您应该安装
mage,然后只需运行
mage -v
此命令将编译 Go 代码,并在 ./dist 目录中为所有 Grafana 支持的平台生成二进制文件。
步骤 6:运行插件
插件构建完成后,您可以将 ./dist 及其内容一起复制,将其重命名为插件的 id,然后将其放在 Grafana 实例的插件路径中进行测试。
然而,有一种更简单的方法可以完成这一切。
- 只需运行
npm run server
此命令使用 docker compose 运行 Grafana 容器,并将构建好的插件放置在正确的位置。
- 要验证构建,请访问
https://:3000上的 Grafana。
步骤 7:测试插件
-
在
https://:3000上的 Grafana 中,使用默认凭据:用户名admin,密码admin。如果未显示登录页面,请单击页面顶部的登录并输入凭据。 -
添加数据源。由于我们在
docker compose环境中运行,因此无需安装,可以直接使用。使用左侧菜单导航到 Connections > Data sources,如下图所示 -
新页面打开后,单击添加数据源。Grafana 会打开另一个页面,您可以在其中搜索我们刚刚创建的数据源名称。
-
点击数据源卡片,然后在下一页上点击保存并测试。
-
单击右上角的构建仪表盘。在下一页上,单击按钮+ 添加可视化。在对话框中,单击新添加的数据源。数据将显示如下
-
为了更好地可视化数据,将可视化时间范围更改为从现在起 1 分钟,然后应用。
此时,您应该开始看到实时数据。如果需要,您可以更改上限、下限或数据生成间隔。这将生成一个新的查询并更新面板。您还可以添加更多查询。
您已成功创建了一个包含前端和后端的 Grafana 流式数据源插件。该插件已准备好供您根据您的特定需求进行自定义。